











信頼性の高いソフトウェアシステムを構築するには、機能的なコードを書くこと以上に、システムがさまざまな条件下でどのように振る舞うかを明確に理解することが求められます。ステートマシン図(しばしば単にステート図と呼ばれる)は、この振る舞いの設計図を提供します。これらは、システムが取りうる明確なモードと、それらの間を移行するルールを明示します。しかし、システムが複雑化するにつれて、論理エラーが発生する可能性が高くなります。これらの問題をデバッグするには、構造的なアプローチ、基盤となる論理に関する深い洞察、そして変数を体系的に排除する方法が必要です。
このガイドは、ステートベースのアーキテクチャ内での論理エラーの特定と解決に必要な戦略を概説します。ステート遷移の構造と一般的な落とし穴を理解することで、エンジニアは推測に頼ることなく、システムの整合性を維持できます。
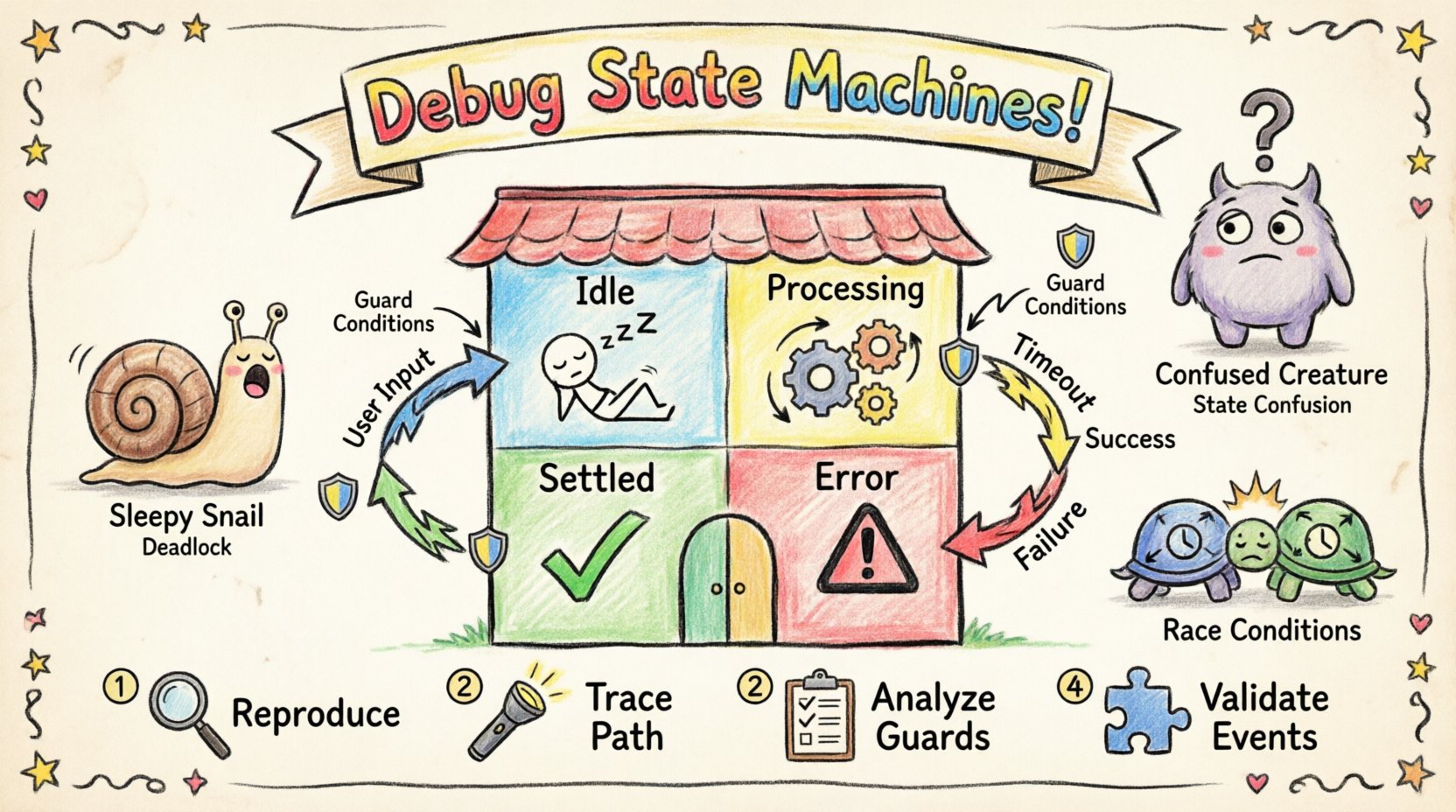
🔍 ステートマシンの構造を理解する
トラブルシューティングを行う前に、ステートマシンを駆動する要素を理解する必要があります。ステート図は単なる視覚的表現ではなく、システムのライフサイクルを定義する論理的な契約です。すべての要素は、フローとデータの制御において特定の目的を持っています。
- ステート:システムが存在しうる明確なモードまたは状態。例としてアイドル, 処理中、またはエラー.
- 遷移:ステートを結ぶ経路。特定のイベントが発生して、一つのステートから別のステートに変化するときに遷移が発生する。
- イベント:遷移をトリガーする信号またはアクション。これらは内部のアクションまたは外部からの入力である可能性がある。
- ガード:遷移中に評価される論理条件(ブール条件)。ガードがtrueに評価された場合にのみ、遷移が発生する。
- アクション:ステートに入室する、退出する、または遷移中に実行される操作。ログ記録、データの更新、外部サービスの起動などが含まれる可能性がある。
- 初期/最終ステート:ライフサイクルの開始点と終了点。
デバッグを行う際、これらの要素が正しく相互作用していることを確認することが重要です。論理エラーの多くは、図で定義された期待される振る舞いと、実行環境での実際の振る舞いとの不一致に起因します。
🚨 一般的な論理エラーとその症状
複雑なシステムは、特定の種類の論理的障害に頻繁に見舞われます。症状を早期に認識することで、デバッグプロセスにおける時間を大幅に節約できます。以下の表は、一般的な問題、観察可能な症状、および可能性の高い根本原因を分類しています。
| エラーの種類 | 症状 | 根本原因 |
|---|---|---|
| 誤った遷移 | システムが明確なトリガーなしに予期しない状態に移行する。 | ガード条件が欠落している、またはイベントハンドラが重複している。 |
| デッドロック | システムが停止し、有効な入力に応答しない。 | 特定のイベントに対して、特定の状態から出る遷移がない。 |
| 到達不可能な状態 | 特定の状態は通常の動作中に決して入らない。 | 誤ったエントリパス、または特定の状態をスキップするロジック。 |
| 状態の混乱 | システムは同じ状態でも、履歴によって異なる振る舞いを示す。 | コンテキストのリセット、または履歴状態の管理に失敗する。 |
| 並行競合状態 | 並行状態で、衝突するアクションが同時に発生する。 | 並行するサブマシン間の同期が欠如している。 |
🧪 ステップバイステップのデバッグ手法
状態機械の問題を解決するには、規律あるワークフローが必要です。急な修正はしばしば新たなバグを引き起こします。論理エラーを特定・修正するため、この体系的なアプローチに従ってください。
1. 問題の再現
修正を試みる前に、エラーを確実に再現する必要があります。問題が断続的な場合、失敗に至るまでのイベントの順序を記録してください。
- 誤った振る舞いを引き起こす特定の入力またはイベントを特定する。
- イベントが発生する前に、システムの現在の状態を記録する。
- イベント後のシステムが入る状態を記録する。
- 問題が一貫して発生するか、特定の条件下(例:特定のデータ値)でのみ発生するかを確認する。
2. 実行パスの追跡
ログ記録メカニズムを使用して実行パスを追跡する。すべての遷移は、関連するコンテキストとともにログに記録されるべきである。
- エントリ/エグジットログ:状態に入ったり出たりしたときにログを記録する。
- 遷移ログ:遷移を引き起こしたイベントをログに記録する。
- ガード評価:ガード条件が通過したか失敗したか、その理由をログに記録する。
- アクションログ:アクションが実行されたときおよびその出力をログに記録する。
このデータはイベントのタイムラインを作成する。このタイムラインを状態図と比較し、コードが設計から逸脱している箇所に不一致がないか確認する。
3. ガード条件の分析
ガード条件は論理エラーの頻発源である。図面上では遷移が利用可能に見えるが、隠れた条件によってその遷移が発火しないことがある。
- 問題のある遷移に関連するすべてのガード条件を確認する。
- ガードで使用されている変数が、イベント発生時における利用可能なデータと一致しているか確認する。
- ガード評価中に発生する副作用が、予期せぬ状態変化を引き起こす可能性がないか確認する。
- ガードがしすぎず、正当な遷移をブロックしないようにする。
4. イベント処理の検証
イベントは変化の触媒である。イベントが正しく処理されない場合、システムはそれを無視するか、誤った状態で処理してしまう可能性がある。
- イベント名がソースと状態機械の間で正確に一致しているか確認する。
- イベントが状態機械の正しいインスタンスに送信されているか確認する。
- 子状態が処理すべきイベントが、親状態によって消費されてしまわないようにする。
- イベントキューが期待される順序でイベントを処理しているか確認する。
🔄 同時実行と並列状態の処理
高度な状態機械はしばしば同時状態を利用する。これにより、複合状態内に複数の独立した状態機械を同時に実行できる。強力ではあるが、同期およびデータ共有に関する複雑性が生じる。
1. 同期ポイント
同時環境では、レースコンディションを防ぐために遷移を同期させる必要がある。一つの並列状態での遷移が、別の並列状態での遷移の完了に依存している可能性がある。
- 並列状態が一致しなければならない場所に明確な同期バリアを定義する。
- 並列ブランチの準備状態を示すためにフラグやステータス変数を使用する。
- 複合状態が完了する前に、並列ブランチの最終状態に到達していることを確認する。
2. 共有データの整合性
並列状態はしばしば共有リソースにアクセスする。二つの状態が同時に同じデータを変更すると、破損が発生する可能性がある。
- 共有状態変数にアクセスする際にはロックメカニズムを実装する。
- 可能な限り不変データ構造を使用して、誤った変更を防ぐ。
- すべてのアクション関数を監査し、グローバルまたは共有状態を変更しているかどうかを確認する。
🛡️ 検証と検査技術
デバッグは反応的であるが、検証は予防的である。デプロイ前に状態機械を検証する戦略を導入することで、トラブルシューティングの負担を軽減できる。
1. 静的解析
静的解析ツールはコードを実行せずに状態図の定義をスキャンできます。構造上の問題を特定できます。
- 到達不可能な状態がないか確認する。
- どのイベントによっても発火できない遷移を特定する。
- すべての状態に有効な退出パスがあることを確認する。
- すべてのイベントが処理されることを保証する(未処理のイベントエラーがないこと)。
2. モデル検証
モデル検証は、状態機械が特定の性質を満たしていることを数学的に検証するプロセスである。これは特に安全要件の高いシステムに有用である。
- 「システムは決してデッドロック状態に入らない」などの性質を定義する。
- これらの性質が状態遷移グラフに対して正しいかを確認するためのアルゴリズムを実行する。
- これらのツールを用いて、複雑な並行処理のシナリオを検証する。
3. 状態機械のユニットテスト
可能な限り、各状態と遷移を独立してテストする。
- システムを特定の状態に配置し、特定のイベントを発火させるテストを書く。
- システムが正しい次の状態に遷移することをアサートする。
- 期待されるアクションが発動されることをアサートする。
- イベントが許可されていない状態で発火するなどの境界条件をテストする。
📝 将来の保守のためのドキュメント
理解しにくい状態機械はデバッグも難しい。明確なドキュメントにより、将来のエンジニアが論理を逆引きしなくても効果的にトラブルシューティングできる。
- コードにコメントを追加する:複雑な遷移や明らかでないガード条件を説明するインラインコメントを追加する。
- 図を維持する:視覚的な状態図をコードと同期させる。古くなった図はリスクとなる。
- エッジケースをドキュメント化する:既知の制限や、機械が異なる方法で処理する特定のシナリオを記録する。
- バージョン管理:状態定義をコードとして扱う。バージョン管理を用いて、論理の変更を時間とともに追跡する。
⚙️ 実際のシナリオ:決済処理パイプライン
決済処理システムを検討する。状態機械は取引のライフサイクルを管理する:開始済み, 承認済み, 決済済み、または失敗.
取引が「決済済み」状態に移行したが、データベースではまだ「承認済み」であると示している。これは典型的な状態不整合エラーである。
- 原因分析: 「承認済み」から決済済み」への遷移がトリガーされたが、状態更新ロジックが永続ストアへの変更コミットに失敗した。
- 影響: ユーザーは成功と見なすが、バックエンドは資金が予約済みであると期待している。
- 修正: 状態更新とデータベースコミットが原子的に実行されることを保証するトランザクションラッパーを実装する。
- 予防策: 状態マシンの状態とデータベースの状態を定期的に照合する再整合ジョブを追加する。
🔧 高度なトラブルシューティングツール
手動トレースは効果的だが、特定のツールを使用するとデバッグプロセスを加速できる。
- インタラクティブな状態可視化ツール: 実時間で状態を視覚的にステップバイステップで確認できるツール。
- ログ集約ツール: 状態IDやイベントタイプでフィルタリング可能な集中型ログシステム。
- デバッグプロトコル: マシンを再起動せずに、外部システムが現在の状態を照会できるインターフェース。
- シミュレーション環境: イベントシーケンスを再再生してバグを安全に再現できるサンドボックス。
🧠 認知負荷と状態の複雑さ
状態の数が増えるにつれて、論理を維持するために必要な認知負荷は指数関数的に増加する。これは「状態爆発問題」として知られている。
- モジュール化: 大きな状態機械を、より小さく管理しやすいサブマシンに分割する。
- 抽象化: 複合状態を使用して、上位レベルの論理から複雑さを隠す。
- 制限: 同時状態の数を厳しく制限して、同期のオーバーヘッドを減らす。
- リファクタリング: 状態図を定期的に見直し、重複しているか重なり合う状態を特定する。
🛑 意図しない入力の処理
堅牢なシステムは、状態図に定義されていない入力に対処しなければならない。これはしばしば「エラー状態」と呼ばれる。
- デフォルト遷移: 意図しない状態で発生するイベントに対して、すべてをカバーする遷移を定義する。
- ログ記録: 意図しないイベントを高優先度でログ記録し、開発者に警告する。
- 回復: システムがエラー状態から回復できることを保証し、クラッシュさせないこと。
- 通知: 意図しないイベントが発生したときに、ユーザーまたはモニタリングシステムに通知する。
📊 状態機械の健全性に関するメトリクス
健全なシステムを維持するため、状態機械に関連する特定のメトリクスを追跡する。
- 遷移頻度: 特定の遷移がどのくらいの頻度で発生するか。急激な変化はバグの兆候である可能性がある。
- 状態持続時間: システムが特定の状態にどのくらいの期間滞在するか。長時間の滞在はスタックの兆候である可能性がある。
- エラー率: エラー遷移を引き起こすイベントの割合。
- デッドロックの数: システムが出力遷移のない状態に入ることの回数。
🚀 システム整合性に関する結論
状態機械の整合性を維持することは継続的なプロセスです。注意深さ、明確なドキュメント化、論理フローの深い理解が求められます。上記で示した手法に従うことで、エンジニアは論理エラーを効果的にデバッグし、複雑なシステムが予測可能に動作することを保証できます。
即時のバグを修正するだけでなく、アーキテクチャ全体の堅牢性を向上させることを忘れないでください。良好に設計された状態機械は自己文書化され、変更に対して耐性があります。後でトラブルシューティングのコストを減らすために、設計段階に時間を投資しましょう。
これらの原則を一貫して適用してください。図を定期的に見直してください。遷移を徹底的にテストしてください。規律を保つことで、複雑さを管理し、安定した信頼性の高いソフトウェアを提供できます。