










効果的なシステム設計は、組織内のデータの流れを理解することから始まります。明確な地図なしに複雑なソフトウェアを構築しようとすると、ビジネスニーズと技術的実装の間にズレが生じることがよくあります。情報システムのモデリングは、これらの相互作用を可視化するための構造的なアプローチを提供します。この実践の中心には、データフローダイアグラム(DFD)があります。これは、情報がどのように処理され、保存され、伝送されるかを文書化する強力なツールです。
この記事では、データフローダイアグラム(DFD)の視点から、情報システムのモデリングの原則を探ります。構成要素、抽象化のレベル、および堅牢なシステムモデルを作成するために必要な分析技術について検討します。物理的な実装ではなく、データの流れの論理に注目することで、コードが書かれる前から明確さと正確性を確保できます。
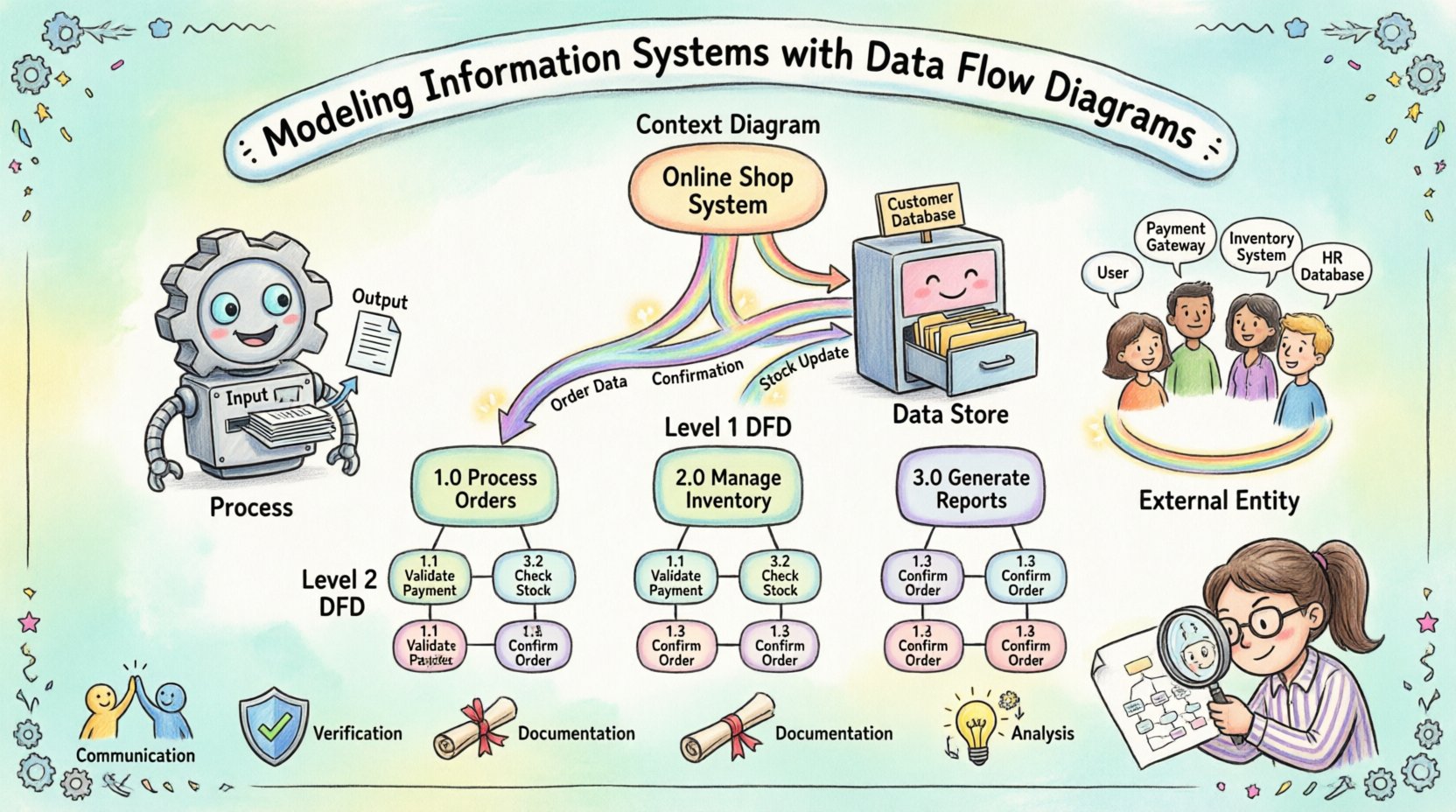
システムモデリングの目的を理解する 🧩
特定の記号に飛び込む前に、なぜシステムをモデリングするのかを理解することが不可欠です。情報システムとは、単なるデータベースやユーザーインターフェース以上のものです。それは、入力を有用な出力に変換するプロセスのネットワークです。モデリングにより、ステークホルダーは技術的な詳細に迷子にならずに、全体像を把握できます。
- コミュニケーション:視覚的な図は、技術チームとビジネスユーザーの間の溝を埋めます。誰もが同じ情報の流れを把握できます。
- 検証:モデルは、開発が始まる前にすべてのビジネス要件が考慮されていることを確認するのに役立ちます。
- 文書化:これらは、システムがどのように動作するかを長期間にわたって記録するものであり、将来の保守やトレーニングに役立ちます。
- 分析:図は、ボトルネック、重複するプロセス、およびデータ処理における潜在的なセキュリティ上の穴を明らかにします。
情報システムをモデリングするということは、本質的にブループリントを作成しているのです。建築家が計画なしに家を建てないのと同じように、システムアーキテクトは地図なしに論理を書くべきではありません。このアプローチにより、再作業が減り、最終製品が組織の目標と一致することを保証できます。
データフローダイアグラムの核心的な構成要素 🏗️
データフローダイアグラムは、システムを表すために4つの主要な要素に依存しています。各要素には特定の役割と視覚的表現があります。これらの構成要素を理解することは、有効なモデルを作成するための第一歩です。
1. プロセス ⚙️
プロセスは、データを変換する行動を表します。これらはシステムのエンジンです。プロセスは入力データを受け取り、ある操作を実行し、出力データを生成します。図では、プロセスは通常、円または丸みを帯びた長方形で表現されます。その名前は、たとえば「税金を計算する」や「ログインを検証する」など、その行動を説明するものでなければなりません。
すべてのプロセスには、少なくとも1つの入力と1つの出力が必要です。データを変換しないで単に存在するプロセスはありえません。データがプロセスに入り、何も出ない場合、モデルは不完全です。データが出力されるが入力がない場合、その出力は説明がつかないものになります。この保存則は論理的一貫性を保証します。
2. データストア 🗄️
データストアは、後で使用するために情報を保持する場所を表します。これらは物理的なデータベース、ファイル、あるいは実際に物理的なファイルボックスでも構いません。DFDでは、データストアは通常、開かれた長方形または二つの平行線で示されます。プロセスとは異なり、データストアはデータを変換しません。データを保持するだけです。
プロセスとデータストアの違いを明確にすることが重要です。プロセスはデータの状態を変更するのに対し、データストアはそれを保持します。プロセスとデータストアの間の接続は、データがストレージから読み込まれたり、書き込まれたりしていることを示しています。この違いは、情報が実際に処理されているのか、それとも単にアーカイブされているのかを明確にするのに役立ちます。
3. 外部エントリティ 👥
外部エントリティは、システム境界の外にあるデータの発信元または受信先です。これらはシステムとやり取りしますが、内部ロジックの一部ではありません。顧客、仕入先、規制機関、または他のシステムなどが例です。図では、これらは通常、四角形や長方形で表現されます。
モデリングする際には、範囲を明確に定義してください。システムの内部と外部はどこか?外部エントリティとは、現在のモデルの範囲内で直接制御または変更できないものすべてを指します。これにより、責任の境界に注目した分析が可能になります。
4. データフロー 🔄
データフローは、プロセス、ストア、エントリティの間での情報の移動を示します。矢印で表現されます。すべての矢印には、移動中のデータを説明するラベルが必要です。たとえば「注文詳細」や「支払い領収書」などです。
データフローは制御信号やタイミングを表すものではありません。実際に移動する情報のペイロードを表します。フローは分岐または合流が可能ですが、常に意味のあるデータを運ぶ必要があります。読みやすさを保つために、矢印が不必要に交差してはいけません。フローが2つのプロセスを結んでいる場合、情報の直接的な受け渡しを示しています。
抽象化のレベルと分解 🔍
複雑なシステムは、一度に一つの視点では理解できません。複雑さを管理するために、アナリストは分解を用います。システムを扱いやすい層に分けるのです。この階層的なアプローチにより、対象となる聴衆や目的に応じて、異なる詳細度のレベルを提供できます。
コンテキスト図(レベル0)
コンテキスト図は、最も高い抽象化レベルを提供します。システム全体を単一のプロセスとして示し、それとやり取りするすべての外部エントリティを特定します。この視点は、「システムとは何か?」という問いに答えます。境界を明確に定義します。
この図では、内部プロセスやデータストアは見えません。システムの境界と、データの流入・流出の流れだけが表示されます。これは、スコープについてステークホルダーの合意を得るために、しばしば最初に作成される図です。
レベル1図
レベル1図は、コンテキスト図の単一のプロセスを、主要なサブプロセスに展開します。システムの主要な機能領域を明らかにします。たとえば、「注文を管理する」プロセスは、「注文を受領する」「在庫を確認する」「支払いを処理する」に分解されることがあります。
このレベルではデータストアが導入され、主要な機能間でのデータの流れを示します。技術チームがアーキテクチャを理解するには十分な詳細さを持ちつつ、特定の論理に陥りすぎないよう、抽象度が適切に保たれています。
レベル2以降
さらに分解は、各プロセスがさらに分解せずに理解できるほど単純になるまで続きます。この段階で、しばしば特定のビジネスルールが文書化されます。このレベルでは、図はコードを書く開発者にとって直接的な参照資料となります。
分解はバランスが取れている必要があります。親プロセスの入力と出力は、その子プロセスの入力と出力と一致しなければなりません。プロセスが3つの子プロセスに分かれる場合、親プロセスに入力されるデータは、子プロセス全体に集団的に入力され、子プロセスから出力されるデータは親プロセスに出ていなければなりません。
表記規則と一貫性 📏
DFDの概念は普遍的ですが、使用される記号は異なる場合があります。業界には主に2つの表記法があります。どちらか一つを選択し、それを一貫して使用することは明確さにとって不可欠です。
| 機能 | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| プロセス | 円または角丸長方形 | 角丸長方形 |
| データストア | 開かれた長方形 | 開かれた長方形(太い線) |
| 外部エンティティ | 長方形 | 長方形 |
| データフロー | 曲線または直線の矢印 | 直線の矢印 |
一貫性は混乱を防ぎます。チームがプロジェクト途中で表記法を切り替えると、ドキュメントが断片化します。早期に標準を確立し、スタイルガイドに文書化しておくのが最善です。
さらに、命名規則も一貫性を持たせる必要があります。プロセスには動詞を使用してください(例:「レコードを更新」)、データフローには名詞を使用してください(例:「レコードデータ」)。この文法的な区別により、読者は各要素の機能をすばやく識別できます。
改善のためのシステム分析 🛠️
図を作成することは、文書化だけの話ではありません。それは分析そのものです。モデルが存在すれば、非効率性やリスクを特定するためにそのモデルを検証できます。
ボトルネックの特定
複数の入力を受けるが単一の出力しか生成しないプロセスを探してください。これらの領域は、作業がたまるボトルネックになりやすいです。2つの特定のポイント間で高いトラフィックが発生している場合は、最適化や並列処理の必要がある可能性を示しています。
データ整合性の確認
データの保存と取得方法を確認してください。機密データのフローはモデル内で暗号化されていますか?データストアに書き込む前に検証されていますか?適切にモデル化されたシステムは、すべての段階でデータ品質を確保します。検証なしにデータがストアに直接流入する場合、モデルは潜在的なリスクを明らかにします。
冗長性の排除
図の異なる部分に同じプロセスが繰り返されているのを見ませんか?これは冗長性を示唆しています。関数を1つのサービスに統合できるかもしれません。重複を減らすことでリソースを節約し、保守を簡素化できます。
完全性の検証
すべての外部エンティティに対応するフローがあることを確認してください。顧客が存在するのに、それとの間でデータフローがない場合、モデルは不完全です。同様に、すべてのデータストアに書き込み者と読み取り者がいることを確認してください。孤立したデータストアは、使用されていないストレージを示唆しています。
保守および進化のためのベストプラクティス 🌱
情報システムは静的ではありません。ビジネスニーズが変化するにつれて進化します。今日正確なモデルであっても、明日には陳腐化する可能性があります。したがって、ドキュメントの維持は、作成することと同じくらい重要です。
バージョン管理
図の変更を追跡してください。バージョン番号や日付は明確に表示されるべきです。これにより、チームは何が変更されたのか、なぜ変更されたのかを理解できます。また、新しい設計が問題を引き起こした場合に、元に戻すことも可能になります。
ステークホルダーのレビュー
定期的にビジネスユーザーとモデルをレビューしてください。システムが彼らの業務フローと一致しているかどうかの真実の情報源は、彼ら自身です。プロセスが現実と一致していない場合、論理的に見えてもモデルは誤りです。
他のモデルとの統合
DFDは孤立して存在しません。データ構造のためのエンティティ関係図(ERD)や、システム動作のための状態遷移図と頻繁に連携します。これらのモデルが整合していることを確認することで、プロセス論理とデータ構造の間の矛盾を防ぐことができます。
アナリストの役割 🧑💼
モデリングの成功は、アナリストに大きく依存します。彼らはビジネス言語と技術的論理の間の翻訳者として機能しなければなりません。これには、強力なコミュニケーションスキルと、分野に対する深い理解が必要です。
効果的なアナリストは、鋭い質問をします。「このデータはどこから来るのですか?」「この入力が欠けた場合、何が起こりますか?」「この更新の責任者は誰ですか?」これらの質問は、ステークホルダーが見落としがちな隠れた要件を明らかにします。
忍耐力も重要です。モデリングは反復的です。初期の図はおそらく誤りや不完全なものになるでしょう。その目標はフィードバックを通じて図を洗練させることです。うまくいかない図を捨てることを恐れてはいけません。得た教訓を活かして、より良い図を作り上げましょう。
結論と最終的な考察 🚀
情報システムをデータフローダイアグラムを使ってモデリングすることは、システム設計に関与する誰にとっても基本的なスキルです。複雑なプロセスについて議論するための明確で視覚的な言語を提供します。実装の詳細ではなく、データの移動に注目することで、チームは整合性を保ち、誤りを減らすことができます。
単純なコンテキスト図から詳細なレベル2モデルへと至るプロセスには、規律と細部への注意が求められます。しかし、その報酬は、理解しやすく、保守・改善がしやすいシステムを構築できることです。組織がデジタルソリューションに依存し続ける中で、その論理を可視化する能力は、重要な資産のままです。
基本から始めましょう。境界を定義しましょう。プロセスを分解しましょう。自分の作業をレビューしましょう。練習を重ねることで、これらのモデルを作成することは自然なことになり、より強固で効率的な情報システムの構築につながります。