











データフローダイアグラム(DFD)は、システム分析と設計の基盤となるものです。情報がシステム内でどのように移動するかを視覚的に表現し、外部エンティティ、内部プロセス、データストア、およびそれらを結ぶフロー間の相互作用を強調します。概念自体はシンプルですが、これらの図の詳細度は、必要な詳細レベルによって大きく異なります。この階層における最も重要な2つの段階が、レベル0とレベル1のDFDです。アーキテクト、アナリスト、ステークホルダーが不要な複雑さに迷うことなくシステムの論理を伝えるために、これらの2つのレベルの違いを理解することは不可欠です。
このガイドでは、レベル0とレベル1の図の構造的違い、使用ケース、および作成のベストプラクティスについて探ります。高レベルのコンテキストビューから詳細な機能分解へと移行する方法を検討し、システムドキュメントの明確さと正確さを確保します。
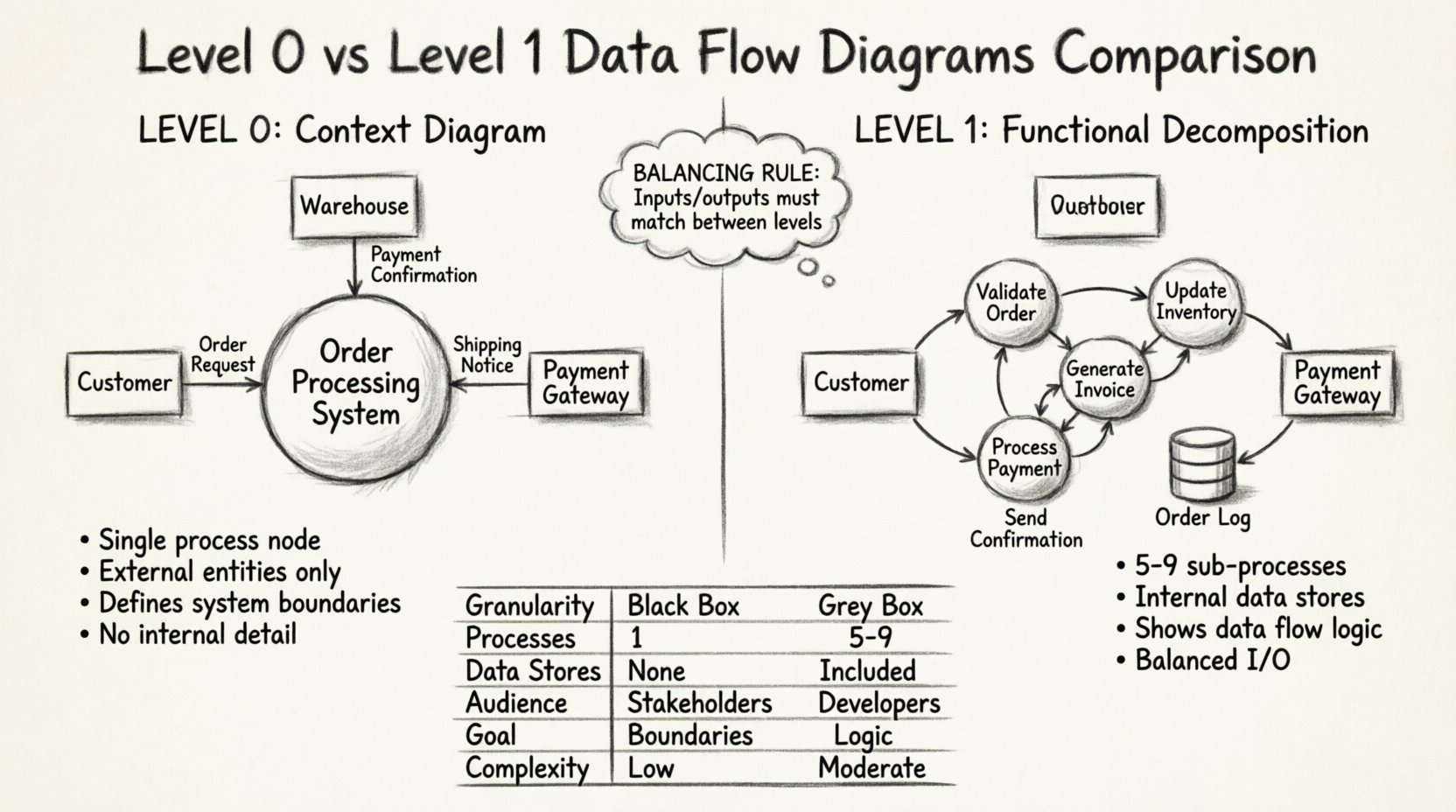
🧭 レベル0のデータフローダイアグラムとは何か?
レベル0のDFDは、しばしば「コンテキスト図」と呼ばれるもので、システムを単一のモノリシックなプロセスとして表現します。これはDFD階層における最も高い抽象度です。ここでの主な目的は、システムの境界を定義し、外部世界との相互作用を示すことです。
主な特徴
- 単一のプロセスノード: システム全体が、通常はシステム名でラベル付けされた1つの円または角丸長方形として描かれます。
- 外部エンティティ: これらはシステム境界外にあるデータの発信元または受信先です。ユーザー、他のシステム、規制機関などが例です。
- データフロー: 矢印は、外部エンティティとシステムの間でのデータの入力と出力を示します。
- 内部詳細なし: データストア、サブプロセス、または内部のデータ移動は一切表示されません。
この図は次の質問に答えます:「システムはどのようなことを行い、誰とやり取りしているのか?」 これは通常、要件収集フェーズで最初に作成されるアーティファクトです。メカニズムに深入りする前に、ステークホルダー間でプロジェクトの範囲について共有された理解を提供します。
レベル0の視覚的構造
ページ中央に「注文処理システム」とラベル付けされた大きな円を想像してください。この円の周囲には、「顧客」、「倉庫」、「決済ゲートウェイ」などの外部エンティティを表す長方形があります。これらの長方形は、データのやり取り(例:「注文リクエスト」や「決済確認」)をラベルとして持つ線で中央の円に接続されています。このシンプルさにより、非技術的なステークホルダーがシステムの目的をすばやく理解できるようになります。
⚙️ レベル1のデータフローダイアグラムとは何か?
レベル1のDFDは、レベル0の図を拡張し、単一のシステムプロセスを主要なサブプロセスに分解します。細部まで掘り下げることなく、システムの内部論理を明らかにします。このレベルは、高レベルのコンテキストと詳細な設計仕様の間のギャップを埋めます。
主な特徴
- プロセスの分解: レベル0の単一プロセスが、5~9つの主要なサブプロセスに分解されます。この数は、可読性を保つためのガイドラインです。
- 内部データストア: このレベルでは、データが保持されるリポジトリ(データベース、ファイル、キューなど)が導入されます。
- 洗練されたデータフロー: 矢印は、サブプロセスとデータストアの間でデータがどのように移動するかを示します。
- バランスの取れた入出力 レベル0のプロセスの入力と出力は、レベル1のサブプロセスの集約された入力と出力と一致しなければならない。
この図は次の質問に答えます:「システムはどのようにその機能を達成するのか?」 情報の流れを理解して基盤アーキテクチャを構築する開発者やシステムアーキテクトにとって、これは極めて重要である。
レベル1の視覚的構造
前の例を用いると、「注文処理システム」という円は、小さな円の集合に置き換えられる。一つは「注文の検証」、もう一つは「在庫の更新」、さらに別の一つは「請求書の発行」である。これらの円は、それらの間を移動するデータを示す矢印でつながっている。また、円筒形の図形が現れることもあり、それは「顧客データベース」や「注文ログ」を表す。この構造により、チームは依存関係やデータ保持要件を把握できる。
🆚 比較:レベル0 vs レベル1
違いを明確にするために、これらの2つのレベルを複数の次元で比較できる。この表は構造的および機能的な違いを強調している。
| 特徴 | レベル0(コンテキスト図) | レベル1(機能分解) |
|---|---|---|
| 粒度 | システム全体の視点(ブラックボックス) | 主要な機能モジュール(グレーボックス) |
| プロセスの数 | 正確に1つ | 5~9つの主要なサブプロセス |
| データストア | 表示なし | 明示的に含まれる |
| 対象者 | 関係者、経営陣、ユーザー | 開発者、システムアーキテクト、アナリスト |
| 主な目的 | システムの境界を定義する | 内部論理とフローを定義する |
| 複雑さ | 低 | 中程度 |
🔄 バランスの概念
レベル0からレベル1に移行する際の重要なルールはバランスの取れた設計です。レベル0のプロセスに入出力されるデータは、レベル1のサブプロセス群全体の入出力と完全に一致している必要があります。これにより、分解プロセス中にデータが生成されたり破壊されたりしないことが保証されます。
たとえば、レベル0で「顧客データ」という入力がシステムに入力されている場合、レベル1では「顧客データ」が少なくとも1つのサブプロセスに流入していることを示す必要があります。レベル0で「領収書」という出力がシステムから出力されている場合、レベル1では「領収書」データを生成するサブプロセスが存在している必要があります。このバランスを保てない場合は、分析に誤りがあるか、設計に欠落している要素があることを示しています。
🛠 設計のベストプラクティス
効果的なDFDを作成するには、規律と特定の規則への従いが求められます。これらのガイドラインに従うことで、明確さを保ち、混乱を防ぐことができます。
1. 名前付けのルール
プロセスは、動詞+名詞の構造で名前を付けるべきです(例:「税金を計算する」など、「税金」ではなく)。データフローは、内容を示す名詞句で名前を付けるべきです(例:「請求書の詳細」など、「請求書」ではなく)。外部エンティティは、データを提供する主体またはシステムを明確に反映するように名前を付けるべきです。
2. ラインの交差を避ける
図のレイアウトは、データフローの線の交差を最小限に抑えるべきです。線の交差は視覚的なノイズを生み、情報の流れを追跡しにくくします。交差を避けられない場合は、それらが明確に区別され、はっきりとラベル付けされていることを確認してください。
3. データストアの一貫性
図全体にわたってデータストアのラベル付けが一貫していることを確認してください。レベル1で「Customer DB」と名付けられたデータベースが、レベル2で「User Table」と名前変更されてはいけません。一貫性があることで、階層の異なるレベル間でのナビゲーションと理解が容易になります。
4. サブプロセスの数を制限する
レベル1は詳細であるべきですが、すべてを網羅する必要はありません。単一のサブプロセスに論理が多すぎると、独自のレベル2の分解が必要になる場合があります。しかし、一般的にレベル1は読み手を圧倒しない範囲で、適切な範囲に留めるべきです。
📈 各レベルの使用タイミング
適切なレベルを選択するには、プロジェクトの段階と対象となる読者を考慮する必要があります。
レベル0を使うべき場面:
- プロジェクト開始段階:早期に範囲と境界を明確にするため。
- 経営層向けの要約:技術的知識のない経営陣に、高レベルの概要を提供するため。
- インターフェースの定義:システムが外部システムと接続する場所を明確にするため。
レベル1を使うべき場面:
- システム設計:開発チームが内部の論理を理解できるように導くため。
- 統合計画:データストアや内部のデータフローが発生する場所を特定するため。
- テスト戦略:プロセスの経路やデータ変換に基づいてテストケースを定義するため。
🔍 一般的な課題とその解決策
これらの図を描く際には、しばしば特定の課題が生じます。これらの問題に気づいておくことで、正確なアーティファクトを作成するのに役立ちます。
問題:データストアの欠落
アナリストは、プロセス間をデータが直接流れると仮定して、レベル1の図にデータストアを含めるのを忘れてしまうことがあります。しかし、ほとんどのシステムでは永続性が求められます。トランザクションの間にデータが保存される場所を確認してください。
問題:ゴーストデータフロー
ゴーストデータフローとは、どこにも向かっていない、またはどこからも出発していない矢印のことです。すべての矢印は、ソース(プロセス、エンティティ、またはストア)から始まり、宛先に終わらなければなりません。図を確認して、すべての線が適切に固定されているか確認してください。
問題:過度な複雑さ
レベル1ですべてのステップを示そうとすると、図がごちゃごちゃになってしまうことがあります。もしレベル1の図が読みにくくなったら、システムを論理的なサブシステムに分割し、それぞれに対して別々のレベル1図を作成するほうが、一つの巨大な図を作成するよりも良いでしょう。
🔗 高レベルへの移行
レベル1の図が完成すると、それ以降のレベル2の図の親となる。レベル1の各サブプロセスはさらに分解できる。この再帰的なプロセスは、プロセスがコードや構成として直接実装できるほど単純になるまで続く。レベル1の図は、特定のアルゴリズムやデータベーススキーマの詳細に飛び込む前に、分解戦略が適切であることを確認するための重要なステップである。
📝 差異の要約
レベル0とレベル1のデータフローダイアグラムは、システム分析において明確に異なるが補完的な役割を果たす。レベル0はシステムの境界と外部環境との関係を定義する。レベル1はカーテンを引き剥がして、主要な機能的コンポーネントと内部のデータ処理を明らかにする。これらは、戦略的計画と戦術的実行の両方を支援する階層的な視点を形成する。
バランス、一貫した命名、適切な粒度という原則に従うことで、チームはこれらの図を活用して曖昧さを減らし、期待を一致させ、堅牢なシステムを構築できる。レガシーアプリケーションのドキュメント作成であれ、新しいアーキテクチャの設計であれ、これらのレベルの違いを習得することは、明確なコミュニケーションと効果的なシステムモデリングを保証する。