











分散システムは、独立したコンポーネント間での情報の移動に大きく依存しています。マイクロサービスを構築する際、アーキテクチャとはコードの分離だけではなく、データがネットワークを介してどのように移動するかを調整することです。データフローロジックを理解することは、システムの整合性、パフォーマンス、信頼性を維持するために不可欠です。データの発生源、変換場所、最終的な到着地点が明確でなければ、システムは不透明になり、トラブルシューティングが困難になります。
このガイドでは、これらのフローをマッピングする手法について探求します。構造的な要素、データ移動の背後にある論理、サービス間の通信を支配するパターンについて検討します。目的は、すべてのトランザクションが明確に記録される透明なアーキテクチャを構築することです。
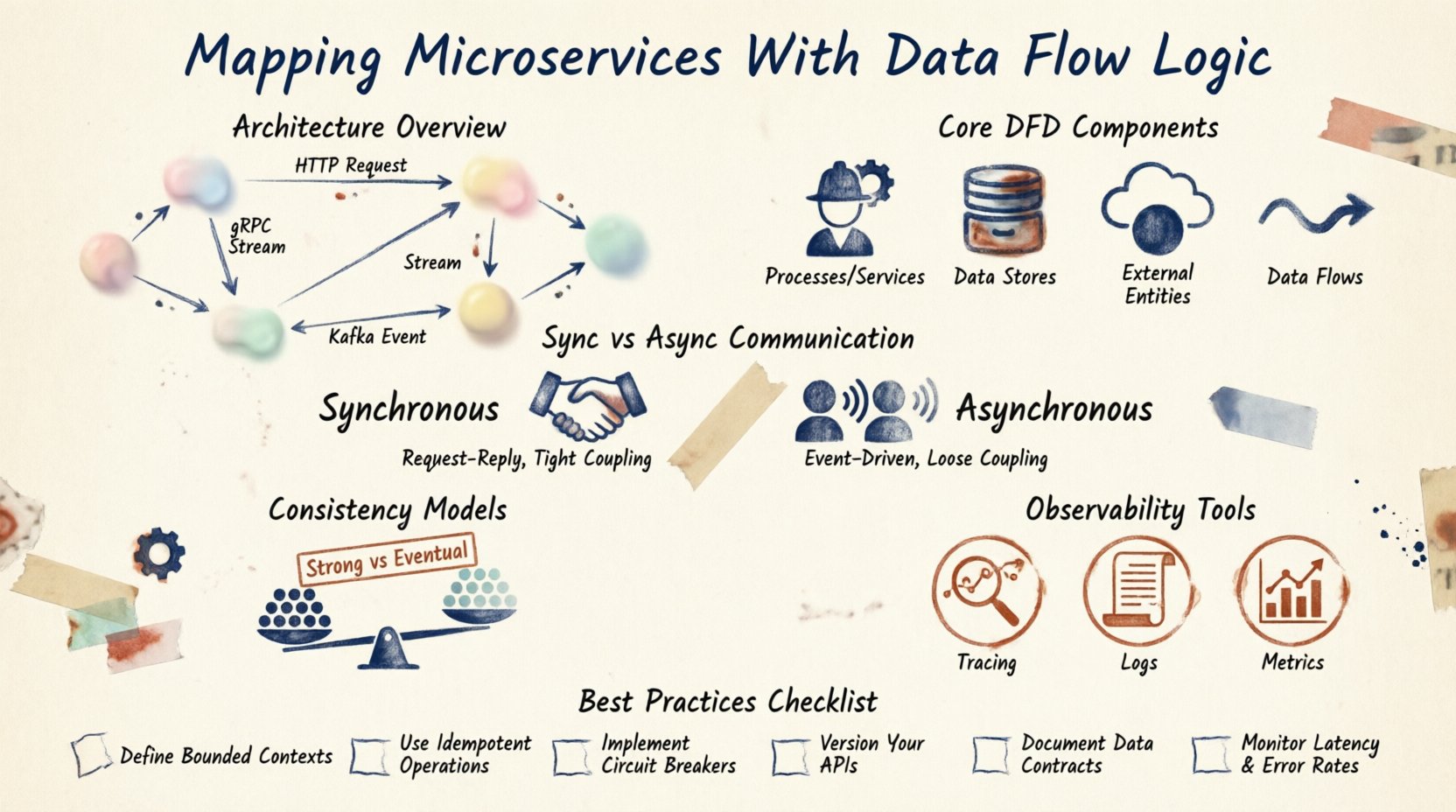
アーキテクチャの理解 🏗️
マイクロサービスアーキテクチャは、モノリシックなアプリケーションをより小さな独立した単位に分解します。各単位は特定のビジネス機能を担当します。しかし、この独立性は、状態管理や通信に関する複雑性をもたらします。データは真空状態に存在するものではなく、常に移動しています。
これらのサービスをマッピングするということは、システムの神経系のブループリントを描いているのと同じです。データの生産者と消費者を特定する必要があります。データ伝送に使用されるプロトコルを理解する必要があります。サービスはHTTP経由で直接通信していますか?メッセージキューを使用していますか?共有データベースにアクセスしていますか?
この領域での明確さが結合を防ぎます。Service AがService Bに依存して動作する場合、その依存関係はマップ上で明示されるべきです。隠れた依存関係は連鎖的な障害を引き起こします。フローを可視化することで、本番環境のパフォーマンスに影響を与える前にボトルネックを特定できます。
マッピングの主な動機
- 可視性:目に見えないものはデバッグできない。明確なマップは、分散環境におけるリクエストの追跡を助けます。
- セキュリティ:データフローを理解することで、適切な境界に暗号化やアクセス制御を適用できます。
- パフォーマンス:高遅延パスを特定することで、ネットワーク呼び出しやデータベースクエリの最適化が可能になります。
- コンプライアンス:規制では、機密データがどこに存在し、どのように移動しているかを把握することが求められることがよくあります。
データフローダイアグラムの核心的な構成要素 📊
データフローダイアグラム(DFD)は、これらの相互作用を標準化された方法で表現するものです。マイクロサービスの文脈では、従来のソフトウェアエンジニアリング用DFDと若干異なる構成要素を持ちます。
1. プロセス(サービス)
これらはアクティブな要素です。各マイクロサービスは、入力データを出力データに変換するプロセスを表します。たとえば、注文サービスは注文詳細を受け取り、在庫予約に変換します。
2. データストア
データは常にメモリ上に留まるわけではありません。データベース、キャッシュ、オブジェクトストレージなどに永続化されることがよくあります。マイクロサービス環境では、サービスは通常、プライベートなデータストアを持ちます。これにより、結合が緩くなります。データベーススキーマが変更された場合、変更を受けるのは所有サービスのみです。
3. 外部エントリティ
これらはシステム外のエージェントです。第三者の決済ゲートウェイ、モバイルアプリケーション、またはユーザーなどが該当します。リクエストを開始したり、通知を受け取ったりします。これらの境界をマッピングすることは、APIゲートウェイの設計にとって不可欠です。
4. データフロー
これらはコンポーネントを結ぶ矢印です。情報の移動を表しています。各フローには、転送中のデータを説明するラベルを付けるべきです。JSONペイロードですか?バイナリファイルですか?イベント通知ですか?
ステップバイステップのマッピングプロセス 🗺️
マップを作成することは、体系的な作業です。システムを段階的に分解する必要があります。これらの図を構築するための論理的なアプローチを以下に示します。
- 境界を特定する:システム内部と外部のものを明確に定義します。これにより、図の範囲が決まります。
- サービスをリストアップする:分析している特定のビジネスプロセスに関与するすべてのマイクロサービスを列挙します。
- データエントリポイントを定義する: データはシステムのどこから入力されますか? APIエンドポイントですか? スケジュールされたジョブですか? メッセージキューのコンシューマーですか?
- 経路を追跡する: データの1つの単位を入力から出力まで追跡する。通るすべてのサービスをメモする。
- ストレージを特定する: 各ステップでデータが読み込まれる場所または書き込まれる場所をマークする。
- ロジックを検証する: 実際の実装と一致しているかを確認するために、開発チームと地図を確認する。
通信パターン 📡
サービス同士のやり取りの仕方がフローのロジックを決定する。主なモードは2つある:同期的と非同期的。
同期通信
Service AがService Bを呼び出し、応答を待つ。これは通常RESTやgRPCで実装される。即時フィードバックが得られるが、強い結合が生じる。Service Bが遅いと、Service Aは停止する。
非同期通信
Service Aがメッセージを送信して、処理を続ける。Service Bは準備ができたらそれを受信する。メッセージブローカーやイベントストリームを使用する。耐障害性は向上するが、ステートの追跡が難しくなる。
| 側面 | 同期的 | 非同期的 |
|---|---|---|
| レイテンシ | 高い(ブロッキング) | 低い(ノンブロッキング) |
| 結合度 | 強い | 弱い |
| 複雑さ | 追跡が簡単 | イベントソーシングを要する |
| 障害処理 | 即時再試行 | デッドレターキュー |
整合性モデル 🤝
分散システムでは、データの整合性が大きな課題となる。複数のデータベースにまたがる単一のトランザクションに頼ることはできない。整合性モデルを決定しなければならない。
強一貫性
すべての読み取りは、最新の書き込みを受け取ります。ブロッキングなしでマイクロサービス間でこれを達成するのは難しいです。多くの場合、分散ロックメカニズムが必要になります。
最終的一貫性
ある時点でデータは一貫性を持つようになります。更新は非同期に伝播します。これは大多数のマイクロサービスの標準です。高い可用性を可能にする一方で、一時的なデータの不一致をアプリケーションが処理する必要があります。
可観測性とトレーシング 🔍
マップが描かれたら、それを監視するツールが必要です。分散トレーシングにより、リクエストIDをすべてのサービスを通じて追跡できます。これはデバッグに不可欠です。
ログは関連付けるべきです。リクエストが失敗した場合、ゲートウェイ、注文サービス、支払いサービスからのログはすべてリンクされなければなりません。このリンクは、あなたのデータフローダイアグラムのデジタルツインです。
メトリクスもフローの一部です。メッセージの量、呼び出しの遅延、エラー率を追跡すべきです。これらのメトリクスは、設計したデータ経路の健全性を検証します。
保守のためのベストプラクティス 🛠️
図が正確なまま保たれなければ、意味がありません。システムは進化するため、マップもそれに合わせて進化しなければなりません。
- 自動生成: 可能な限り、コードやインフラストラクチャをコードとして図を生成してください。これにより手動エラーを減らすことができます。
- バージョン管理: 図をコードと同じリポジトリに保存してください。プルリクエストの際に図をレビューしてください。
- 定期的な監査: 四半期ごとのレビューをスケジュールして、マップが実行中のシステムと一致していることを確認してください。
- プロトコルの文書化: データフォーマットを明確に定義してください。スキーマを使用して、サービス間で構造を強制してください。
分散フローにおける課題 ⚠️
これらのシステムをマッピングすることは、困難を伴います。ネットワークが障害になることがあります。サービスが再起動する場合があります。データが失われる場合もあります。
ネットワーク遅延: サービス間の物理的な距離はパフォーマンスに影響を与えることがあります。タイミングロジックでこれを考慮しなければなりません。
データ断片化: データは多数のストアに分散されています。エンティティの完全なビューを再構成するには、異なるソースからのデータを結合する必要があります。これによりクエリの複雑性が増します。
オーケストレーション vs. コレオグラフィー: フローを誰が制御するかを決めなければなりません。オーケストレーションは中央の調整者を使用します。コレオグラフィーはイベントに依存します。両者とも可視性と制御に関するトレードオフがあります。
将来に備えた設計 🔮
技術は変化します。プロトコルは進化します。あなたのマップは、これらの変化に耐えうるほど抽象的でなければなりません。
実装の詳細ではなく、ビジネスロジックに注目してください。データが何を意味するかを説明し、単にどのようにエンコードされているかだけではなく、その意味を述べましょう。この抽象化により、基盤技術を変更しても全体のアーキテクチャを再書き直さずに済みます。
スケーラビリティを考慮してください。フローは10倍の負荷を処理できますか?マップはボトルネックが発生する可能性がある場所を示していますか?最初から成長を想定して設計してください。
データロジックに関する最終的な考察
マイクロサービスをデータフローロジックでマッピングすることは、アーキテクトにとって基盤的なスキルです。議論を抽象的なコードから具体的な動きへと移行させます。フローを可視化することで、チームはレジリエンス、セキュリティ、パフォーマンスに関するより良い意思決定ができます。
マップを最新の状態に保つには、自制心が必要です。すべての人が経路を理解していることを確認するには協力が必要です。しかし結果として、構築しやすく、デバッグしやすく、スケーラビリティも高いシステムが得られます。データの流れが明確になり、システムは圧力下でも安定したままです。
これらの図に時間を投資してください。これらはシステムの生命線を記録するドキュメントです。本番サーバーで電気が消えてしまったとき、これらのマップが復旧を導くのです。