











情報がシステム内でどのように移動するかを理解することは、あらゆるアナリストや開発者にとって重要です。データフローダイアグラム(DFD)は、この移動を視覚的に表現するものです。データがどこから来ているか、どのように変化するか、そして最終的にどこに到達するかを明確に示します。このガイドでは、これらの図を正確かつ明確に作成するプロセスを説明します。
なぜデータ移動を可視化するのか? 📊
ペンを取るかキャンバスを開く前に、図の目的を理解することが必要です。DFDはフローチャートではありません。制御フローまたは論理的な判断を示すものではありません。代わりに、データの移動にのみ焦点を当てます。この違いは正確性を保つために非常に重要です。
データフローを可視化することで、いくつかの実用的な利点があります:
- 明確さ:複雑なシステムは、視覚的な要素に分解することで、理解しやすくなります。
- コミュニケーション:ステークホルダーは、コードの知識がなくてもシステムの動作について議論できます。
- ギャップ分析:欠落しているデータストアや不要なフローは、図を作成する過程で明らかになります。
- ドキュメント化:この図は、システム要件の動的な記録として機能します。
データフローダイアグラムの核心的な構成要素 🧩
すべてのDFDは4つの標準的な記号に依存しています。これらの記号が図の語彙を構成します。適切に使用することで、図を読む誰もがアーキテクチャを理解できるようになります。
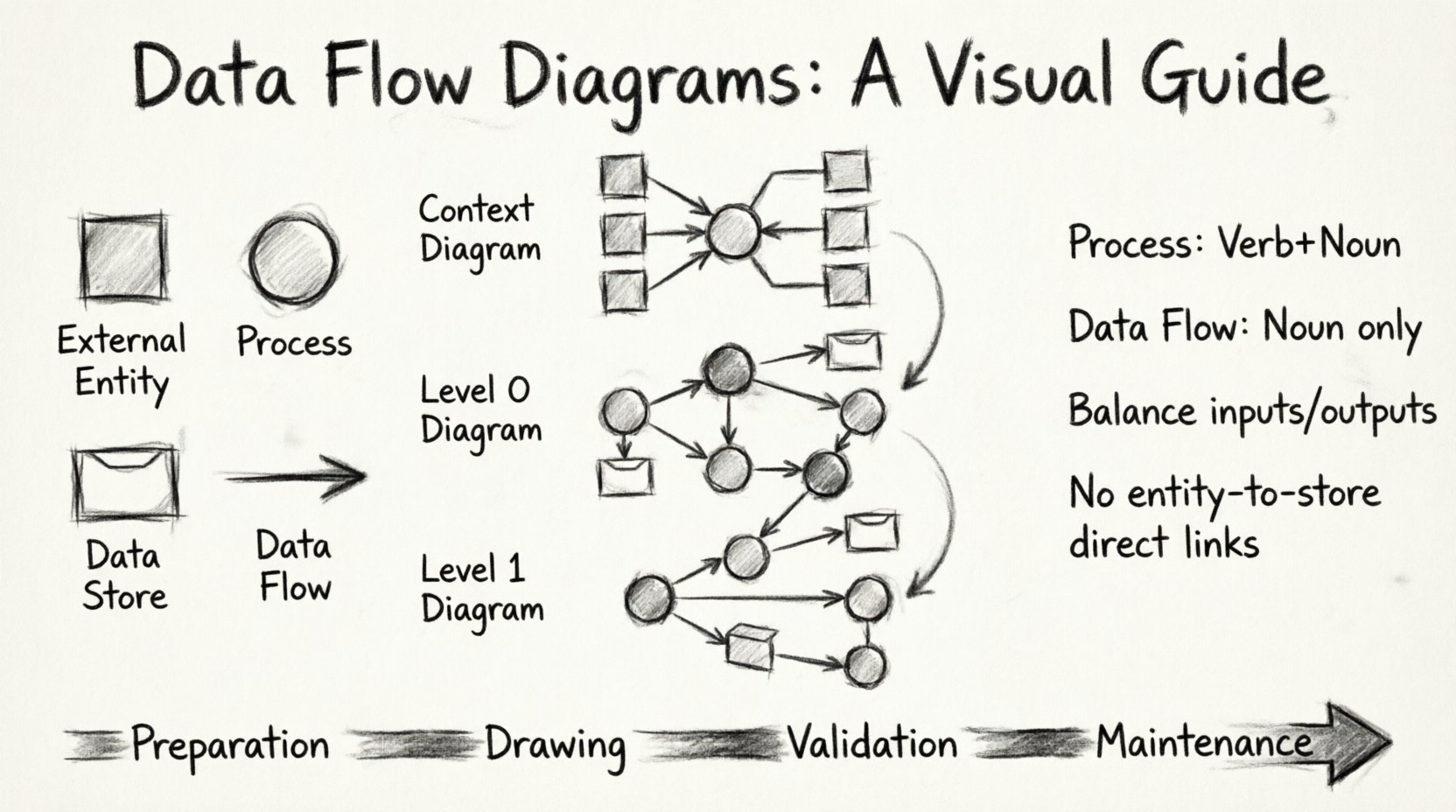
1. 外部エンティティ(発生源または目的地)
外部エンティティは、プロセスとやり取りする人々、組織、または他のシステムを表します。これらはシステムの境界の外に位置します。データはそれらから流入するか、それらへ流出します。通常、四角形または長方形で描かれます。
2. プロセス(変換)
プロセスはデータを変更します。入力を受け取り、計算またはアクションを実行し、出力を生成します。これが図の中心となる部分です。プロセスは通常、円または角が丸い長方形で表されます。すべてのプロセスには少なくとも1つの入力と1つの出力が必要です。
3. データストア(リポジトリ)
データストアは、後で使用するための情報を保持します。プロセスとは異なり、データを変換するのではなく、単に安全に保管するだけです。データベース、ファイル、キューなどが例です。これらは通常、開口部のある長方形または平行線で示されます。
4. データフロー(接続)
データフローは情報の移動を表します。矢印が方向を示します。すべてのフローは、データを説明する名詞句でラベル付けされなければなりません。動詞ではいけません。たとえば、「注文詳細」は正しいですが、「注文を処理する」は誤りです。
準備フェーズ 📝
いきなり描き始めると、混乱を招くことがあります。準備段階を経ることで、図が管理可能であることを保証できます。最初の線を描く前に、以下のステップに従ってください。
システム境界を定義する
システムの内部と外部を特定してください。境界内にあるすべてのものは、ソフトウェアまたはプロセスによって管理されます。境界外にあるものはすべて外部です。この境界は、外部エンティティをどこに配置するかを決定するのに役立ちます。
情報源を収集する
既存のドキュメントを確認し、ステークホルダーにインタビューを行い、現在のワークフローを検討してください。システムに入力されるデータと期待される結果を把握する必要があります。正確な入力データがなければ、図は推測に過ぎません。
ステップ1:コンテキスト図 🌍
コンテキスト図は高レベルの視点です。システム全体を1つのプロセスとして示し、それにやり取りする外部エンティティも示します。これはあらゆるDFDの出発点です。
- 単一のプロセスを特定する:システム全体を表す円またはバブルを描く。たとえば「注文管理システム」といった名前を付ける。
- 外部エンティティを配置する:関与するすべてのユーザー、部門、または外部システムに対して四角を描く。例として「顧客」「倉庫」「決済ゲートウェイ」などがある。
- データフローを描く:エンティティを中央プロセスに矢印で接続する。各矢印に交換されるデータをラベルで示す。データの送受信がある場合は、矢印が双方向になるようにする。
- 完全性を確認する:すべての外部インタラクションが考慮されているか確認する。エンティティがデータを送信しているが受信していない場合、応答が欠けているかどうかを確認する。
ステップ2:レベル0図(トップレベル) 🏗️
コンテキストが確立されたら、単一のプロセスを主要なサブプロセスに分解する。これをレベル0図と呼ぶ。システムを主要な機能領域に分割する。
- プロセスを分解する:単一のコンテキストプロセスを3~7つの主要プロセスに置き換える。多すぎると見づらくなるし、少なすぎると詳細が不足する。
- データストアを特定する:このレベルでデータを保存する必要がある場所を特定する。情報が取得または保存されるプロセスの間にデータストアを配置する。
- フローを接続する:プロセス、エンティティ、ストアの間に矢印を描く。すべてのプロセスに入力と出力があることを確認する。
- バランスを保つ:このレベルの入力と出力はコンテキスト図と一致している必要がある。コンテキスト図で「注文」が入力されている場合、レベル0図では「注文」がサブプロセスのいずれかに流入していることを示さなければならない。
ステップ3:レベル1およびそれ以上の分解 🔍
レベル0図内のプロセスが複雑な場合、さらに分解する必要がある。これによりレベル1図が作成される。プロセスが直接実装できるほど単純になるまでこのプロセスを繰り返すことができる。
分解のルール
- 一度に一つのプロセスのみ:次のプロセスに移る前に、一つのサブプロセスに集中して分解する。一度に全体のシステムを描こうとしない。
- フローを保持する:プロセスをより小さなプロセスに分割する際、元のプロセスに入力されるデータは新しいサブプロセスに入力されなければならない。出力されるデータは新しいサブプロセスから出なければならない。
- 詳細を制限する:開発者が追加説明なしにコードを書けるほど論理が明確になったら、分解を停止する。通常、ほとんどのシステムでは3レベルで十分である。
命名規則とベストプラクティス 🏷️
一貫した命名は図の可読性を高める。命名が一貫しないと混乱やエラーを招く。
プロセス名
プロセス名は動詞の後に名詞を付けるべきです。例として、「ユーザー検証」、「税金計算」、または「レポート生成」があります。これは行動を示しています。曖昧な名前である「システム」や「データ」は避けましょう。変換を記述するには能動的な動詞を使用してください。
データフロー名
データフロー名は名詞または名詞句であるべきです。例として、「顧客ID」、「請求書」、または「支払い領収書」があります。フロー自体がデータであり、行動ではないため、「請求書送信」のような動詞は避けましょう。行動はプロセスです。
エンティティ名
外部エンティティは、アクターを表す単数または複数の名詞であるべきです。「顧客データ」ではなく「顧客」を使用しましょう。「倉庫管理」ではなく「倉庫」を使用します。エンティティはアクターであり、データではありません。
データフローのルールと制約 ⚖️
厳格なルールを遵守することで、設計上の論理的誤りを防ぎます。これらの制約により、図が有効なシステムを表していることが保証されます。
| ルール | 説明 |
|---|---|
| データストア入力 | データはプロセスからストアにのみ書き込むことができます。エンティティとストアの間の直接的なフローは一般的に許可されていません。 |
| データストア出力 | データはプロセスによってストアからのみ読み取ることができます。エンティティはストアに直接アクセスできません。 |
| プロセス入出力 | すべてのプロセスには少なくとも1つの入力と1つの出力が必要です。入力はなくデータを消費するプロセスは「ブラックホール」と呼ばれます。入力なしにデータを生成するプロセスは「魔法のソース」と呼ばれます。両方とも誤りです。 |
| データフローの交差 | データフローはデータストアや外部エンティティを直接交差してはいけません。すべてのフローはプロセスを通らなければなりません。 |
検証とレビュー ✅
図が描かれた後は、検証が必要です。このステップにより、モデルが現実と一致していることを確認できます。
バランスの確認
親プロセスの入力と出力とその子プロセスの入力と出力を比較してください。親プロセスに入力されるデータは、子プロセスに入力されるデータと等しくなければなりません。親プロセスから出力されるデータは、子プロセスから出力されるデータと等しくなければなりません。一致しない場合は、図がバランスしていないため修正が必要です。
完全性の確認
すべてのデータフローを確認してください。すべてのデータに宛先はありますか?すべてのプロセスに元はありますか?接続のない孤児データストアはありますか?完全な図には、未接続の端がありません。
ステークホルダーの検証
システムを使用する人々に図を提示してください。データフローを追跡してもらうように依頼しましょう。彼らはその経路に同意しますか?抜けているステップは見つかりますか?彼らのフィードバックが正確性の最終的な検証です。
図の維持管理 🔄
DFDは一度きりの作業ではありません。システムは進化し、要件も変化します。図はそれらと共に進化しなければなりません。
- バージョン管理: 変更を追跡してください。バージョンには日付または番号を付けてください。
- 定期的に更新する:新しい機能が追加されたときやプロセスが変更されたときは、すぐにDFDを更新してください。
- 古いバージョンをアーカイブする:監査やデバッグの際に参照できるように、古い図を保存してください。
視覚的正確性についての結論 🎯
データフローダイアグラムを作成することは、論理と可視化に関する厳格な練習です。複雑なシステムを理解しやすい部分に分解するには忍耐が必要です。上記の手順に従うことで、開発やコミュニケーションのための信頼できる設計図として機能する図を生成できます。
目的は単に線を引くことではなく、データの流れを理解することです。データの流れが明確になると、システム設計も明確になります。この明確さによりエラーが減り、最終製品の品質が向上します。コードではなくデータに注目し、図がその目的を効果的に果たすようにしてください。