











Comprendre comment les informations traversent un système est fondamental pour concevoir des architectures logicielles fiables. Lorsque nous représentons un système à l’aide d’un diagramme de flux de données (DFD), nous ne faisons pas seulement dessiner des boîtes et des lignes ; nous traçons le cycle de vie des données elles-mêmes. Analyser les chemins de déplacement des données exige une examination rigoureuse de l’origine des données, de leur transformation, de leur lieu de stockage et de leur sortie de l’environnement. Ce processus garantit l’intégrité, les performances et la sécurité à travers toute l’architecture.
Sans une carte claire, les données peuvent se perdre, se dupliquer ou être exposées à un accès non autorisé. Une analyse approfondie révèle les goulets d’étranglement, les dépendances cachées et les points de défaillance potentiels avant qu’ils n’affectent la production. Ce guide explore la méthodologie pour détailler ces chemins avec précision et clarté.
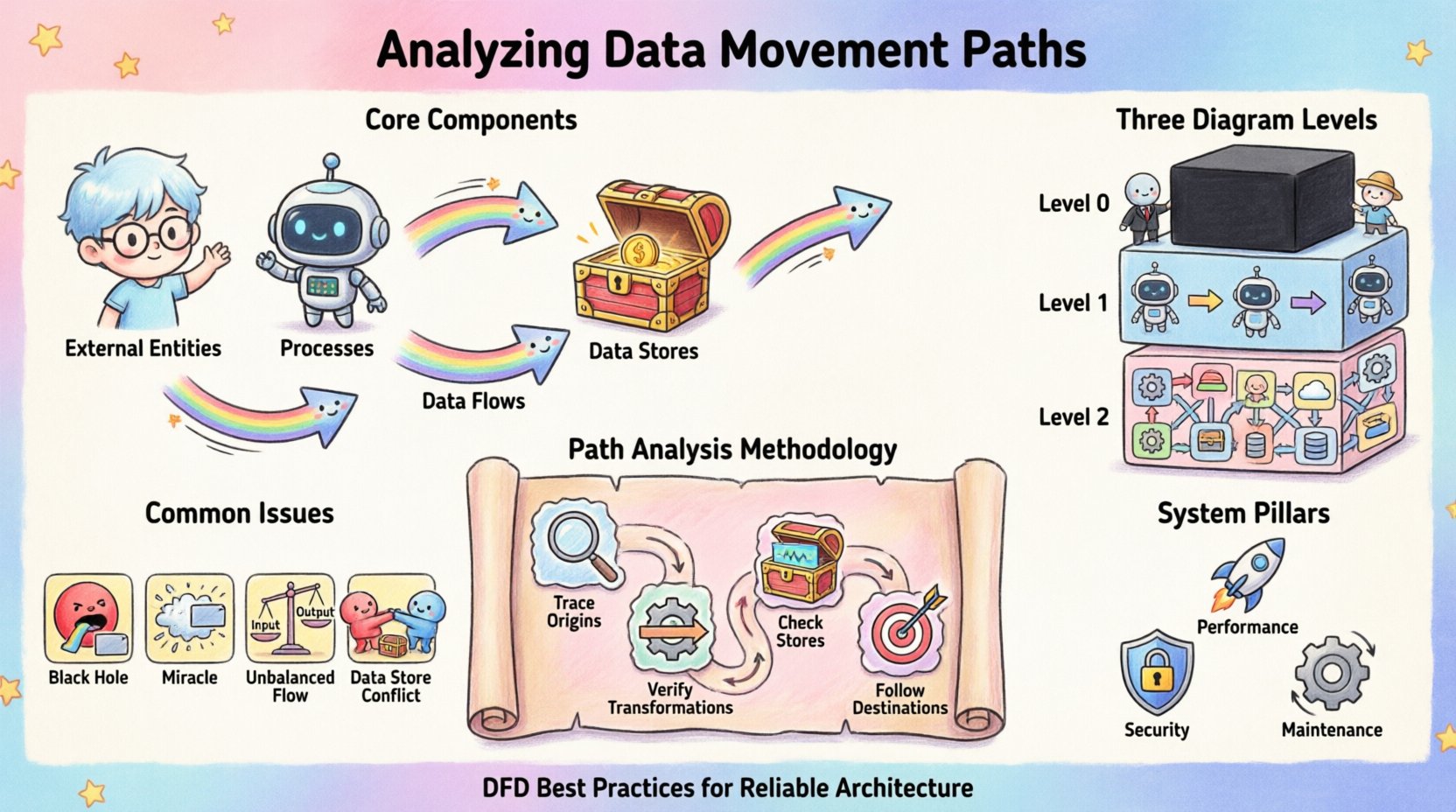
Composants fondamentaux du déplacement des données 🧩
Pour analyser efficacement le déplacement, il faut d’abord reconnaître les éléments distincts qui le facilitent. Chaque DFD repose sur un vocabulaire cohérent pour décrire le flux. Ignorer ces définitions entraîne une ambiguïté dans le modèle.
- Entités externes : Elles représentent des sources ou des destinations situées en dehors de la frontière du système. Elles initient des demandes de données ou reçoivent des sorties traitées. Les exemples incluent des utilisateurs humains, d’autres systèmes ou des services tiers.
- Traitements : Ce sont les transformations. Un traitement prend des données d’entrée, applique une logique ou des règles, et produit une sortie. C’est le moteur du changement à l’intérieur du système.
- Bases de données de données : Ce sont des répertoires où les informations sont conservées pour un accès ultérieur. Elles assurent la persistance, permettant aux données de survivre au-delà de l’exécution immédiate d’un traitement.
- Flux de données : Ce sont les flèches reliant les composants. Elles représentent le déplacement réel des paquets ou des enregistrements de données entre les entités, les traitements et les bases de données.
Chaque flèche doit comporter une étiquette descriptive indiquant exactement quelles informations circulent. Des étiquettes vagues comme « info » ou « données » masquent la nature précise du transfert, rendant l’analyse difficile.
Niveaux de détail dans la représentation graphique 📊
Le déplacement des données est rarement statique ; il existe à différents niveaux d’abstraction. Un seul diagramme ne peut pas capturer chaque octet d’information. Au lieu de cela, nous utilisons une approche hiérarchique pour décomposer le système.
1. Diagramme de contexte (Niveau 0)
Le niveau le plus élevé considère l’ensemble du système comme une seule boîte noire. Il montre le système en interaction avec des entités externes. Cela est crucial pour comprendre les frontières. Il répond à la question : Qu’est-ce que le système échange avec le monde extérieur ?
2. Diagramme de niveau 1
Ici, la boîte noire est éclatée en traitements majeurs. Ce niveau révèle les sous-systèmes principaux et comment les données de haut niveau circulent entre eux. Il offre une vue d’ensemble de l’architecture interne sans s’attarder sur des détails logiques minutieux.
3. Diagrammes de niveau 2 et inférieur
Une décomposition supplémentaire a lieu pour les processus complexes. Ces vues détaillées montrent des transformations spécifiques et le flux granulaire des données. Ce niveau est essentiel pour identifier des étapes de validation spécifiques et des mécanismes de gestion des erreurs.
Lors de l’analyse des chemins, la cohérence entre les niveaux est primordiale. Les données entrant dans un traitement de niveau 1 doivent correspondre aux données sortant de celui-ci. Les écarts entre les niveaux indiquent des lacunes dans la conception.
Méthodologie pour l’analyse des chemins 🔍
Suivre un chemin de données est un exercice systématique. Il consiste à suivre la piste depuis la source jusqu’à la destination. Ce processus aide à identifier les erreurs logiques et les connexions manquantes.
Étape 1 : Suivre les origines des entrées
Commencez par une entité externe. Suivez la flèche vers l’intérieur du système. Demandez où ces données vont ensuite. Vont-elles vers un traitement ou une base de données ? Si elles vont vers un traitement, ce dernier dispose-t-il d’informations suffisantes pour fonctionner ? Chaque traitement doit avoir au moins une entrée et une sortie.
Étape 2 : Vérifier les transformations
Dès qu’une donnée entre dans un traitement, analysez le changement. La sortie est-elle logiquement dérivée de l’entrée ? Parfois, des données apparaissent dans la sortie d’un traitement sans être présentes à l’entrée. Cela est connu comme un « miracle » et indique un input manquant ou une constante codée en dur qui devrait être documentée.
Étape 3 : Vérifier les bases de données
Identifiez chaque opération de lecture et d’écriture. Une base de données ne doit pas être une impasse. Si des données entrent dans une base, il doit y avoir un flux correspondant à sa sortie à un moment donné, sauf si les données sont archivées de manière permanente. Vérifiez que le schéma implicite du diagramme correspond aux exigences de stockage physique.
Étape 4 : Suivre les destinations des sorties
Où va les données traitées ? Revient-elle à l’utilisateur ? Déclenche-t-elle un autre processus ? Quitte-t-elle la frontière du système ? Assurez-vous que chaque chemin de sortie soit pris en compte. Les processus orphelins qui produisent des données sans destination sont un signe de conception incomplète.
Problèmes structurels courants ⚠️
Lors de l’analyse, des motifs spécifiques apparaissent, signalant des défauts de conception. Les reconnaître tôt évite des restructurations coûteuses plus tard.
| Problème | Description | Impact |
|---|---|---|
| Trou noir | Un processus a des entrées mais aucune sortie. | Les données sont consommées et disparaissent. La logique est incomplète. |
| Miracle | Un processus a des sorties mais aucune entrée. | Les données apparaissent de nulle part. La logique est indéfinie. |
| Flux déséquilibré | Les données d’entrée et de sortie ne correspondent pas entre les niveaux. | Perte d’intégrité des données lors de la décomposition. |
| Conflit de magasin de données | Plusieurs processus écrivent dans le même magasin sans verrouillage. | Problèmes de concurrence et corruption des données. |
Considérations en matière de sécurité et de conformité 🔒
La sécurité n’est pas un ajout ; elle est une propriété du déplacement des données lui-même. L’analyse des chemins nous permet d’identifier où se trouvent et où circulent les informations sensibles.
Identification des données sensibles
Suivez les informations personnellement identifiables (PII) ou les enregistrements financiers. Si des données sensibles circulent entre des processus, doivent-elles être chiffrées ? Si elles sont stockées, l’accès est-il contrôlé ? Le diagramme doit mettre en évidence ces flux sensibles, peut-être en utilisant des styles de lignes ou des étiquettes distincts.
Points de contrôle d’accès
Chaque processus agit comme un gardien potentiel. Analysez les exigences d’authentification pour chaque processus. Le diagramme de flux de données implique-t-il qu’un processus quelconque puisse accéder à n’importe quel magasin ? Cela indique souvent la nécessité de contrôles d’accès basés sur les rôles plus stricts.
Conformité réglementaire
Les réglementations fixent souvent où les données peuvent être stockées. Par exemple, certaines juridictions exigent que les données restent dans des limites géographiques spécifiques. Un chemin de déplacement des données qui franchit ces limites doit être signalé pour une revue juridique. Le diagramme sert de preuve de l’architecture de conformité.
Performance et optimisation 🚀
Le déplacement des données n’est pas gratuit. Il consomme de la bande passante, de la puissance de traitement et du temps. Analyser les chemins permet d’optimiser ces ressources.
Identification des goulets d’étranglement
Recherchez les processus ayant plusieurs entrées et sorties à haut volume. Ceux-ci risquent de devenir des goulets d’étranglement. Si un seul processus agrège des données provenant de cinq sources différentes avant de les transmettre, il peut avoir des difficultés sous charge. Considérez de le diviser en processus parallèles.
Analyse de latence
Comptez le nombre de sauts que les données doivent effectuer pour atteindre leur destination. Chaque saut introduit une latence. Si une requête utilisateur nécessite de passer par dix processus avant qu’un résultat ne soit retourné, le système semblera lent. Réduire le nombre de transformations peut améliorer la réactivité.
Réduction de la redondance
Vérifiez les flux de données redondants. Si les mêmes informations sont envoyées à trois processus différents, envisagez s’ils peuvent partager un magasin de données commun. Cela réduit le trafic réseau et assure la cohérence.
Maintien de la précision du diagramme 🔄
Un diagramme est un document vivant. Au fur et à mesure que le système évolue, les chemins changent. Maintenir sa précision exige une approche rigoureuse.
Contrôle de version
Tout changement apporté à la structure du flux de données doit être versionné. Cela permet aux équipes de retracer quand un chemin spécifique a été modifié. Cela est essentiel pour le débogage et l’analyse d’impact.
Analyse d’impact
Avant de modifier un processus, suivez tous les flux connectés. Modifier un processus pourrait rompre un consommateur en aval. Le diagramme aide à visualiser ces dépendances. Si le format des données change dans un magasin, tous les processus lisant depuis celui-ci doivent être mis à jour.
Normes de documentation
Établissez des règles pour la nomenclature et l’étiquetage. Des conventions de nommage cohérentes rendent le diagramme lisible pour les nouveaux membres de l’équipe. Une légende claire doit expliquer tout symbole spécial ou type de ligne utilisé pour des indicateurs de sécurité ou de performance.
Intégration avec d’autres modèles 🤝
Les diagrammes de flux de données n’existent pas en isolation. Ils complètent d’autres techniques de modélisation.
Diagrammes de relations entre entités (ERD)
Alors que les DFD se concentrent sur le mouvement, les ERD se concentrent sur la structure. Les croiser garantit que les données circulant à travers les processus correspondent au schéma défini dans la base de données. Si un processus attend un « CustomerID » mais que l’ERD définit « ClientNum », un désaccord existe.
Diagrammes de transition d’état
Les DFD montrent ce qui se déplace, mais les diagrammes d’état montrent quand. Combiner ces deux types aide à comprendre comment le déplacement des données déclenche des changements d’état. Par exemple, un flux « PaymentReceived » pourrait déclencher un changement d’état de « Pending » à « Shipped ».
Conclusion sur les pratiques d’analyse ✅
La discipline de l’analyse des chemins de déplacement des données repose sur la clarté et le contrôle. Elle transforme des exigences abstraites en décisions architecturales concrètes. En suivant rigoureusement chaque flèche et en vérifiant chaque transformation, les architectes construisent des systèmes résilients et compréhensibles.
Cette pratique exige une attention aux détails. Elle implique de remettre en question chaque hypothèse sur l’origine des données et leur destination. Lorsqu’elle est correctement appliquée, le diagramme résultant sert de plan directeur pour le développement, les tests et la maintenance. Il devient un langage commun entre les parties prenantes métier et les équipes techniques, garantissant que chacun comprend le parcours des données.
À mesure que les systèmes gagnent en complexité, le besoin de cartographie claire augmente. Un diagramme de flux de données bien analysé est un investissement dans la stabilité à long terme du logiciel. Il réduit le risque de perte de données, de violations de sécurité et de dégradation des performances. En respectant ces normes analytiques, les équipes assurent que leurs systèmes restent robustes à mesure de leur évolution.