











Comprendre comment les informations circulent dans un système est fondamental pour l’analyse et la conception des systèmes. Un diagramme de flux de données (DFD) fournit une représentation visuelle de ce mouvement. Contrairement aux plans techniques qui se concentrent sur le code ou les schémas de base de données, un DFD se concentre sur le flux des données et les processus qui les transforment. Ce guide détaille les symboles essentiels utilisés pour construire ces diagrammes, garantissant clarté et précision dans votre documentation.
Qu’est-ce qu’un diagramme de flux de données ? 🤔
Un diagramme de flux de données est un outil d’analyse structurée. Il cartographie la séquence des activités de traitement de l’information. Il ne décrit pas la logique du système en termes de code de programmation. Au contraire, il illustre quelles données sont transférées, d’où elles proviennent, où elles vont et comment elles évoluent. Cette abstraction permet aux parties prenantes de comprendre les exigences fonctionnelles sans se perdre dans les détails techniques de mise en œuvre.
Les DFD sont hiérarchiques. Ils commencent par une vue d’ensemble de haut niveau, puis se décomposent progressivement en vues plus détaillées. Cette décomposition aide à gérer la complexité. En définissant les limites et les interactions, les analystes peuvent identifier des lacunes dans les exigences ou des goulets d’étranglement potentiels avant le début du développement.
Les quatre symboles fondamentaux 🛠️
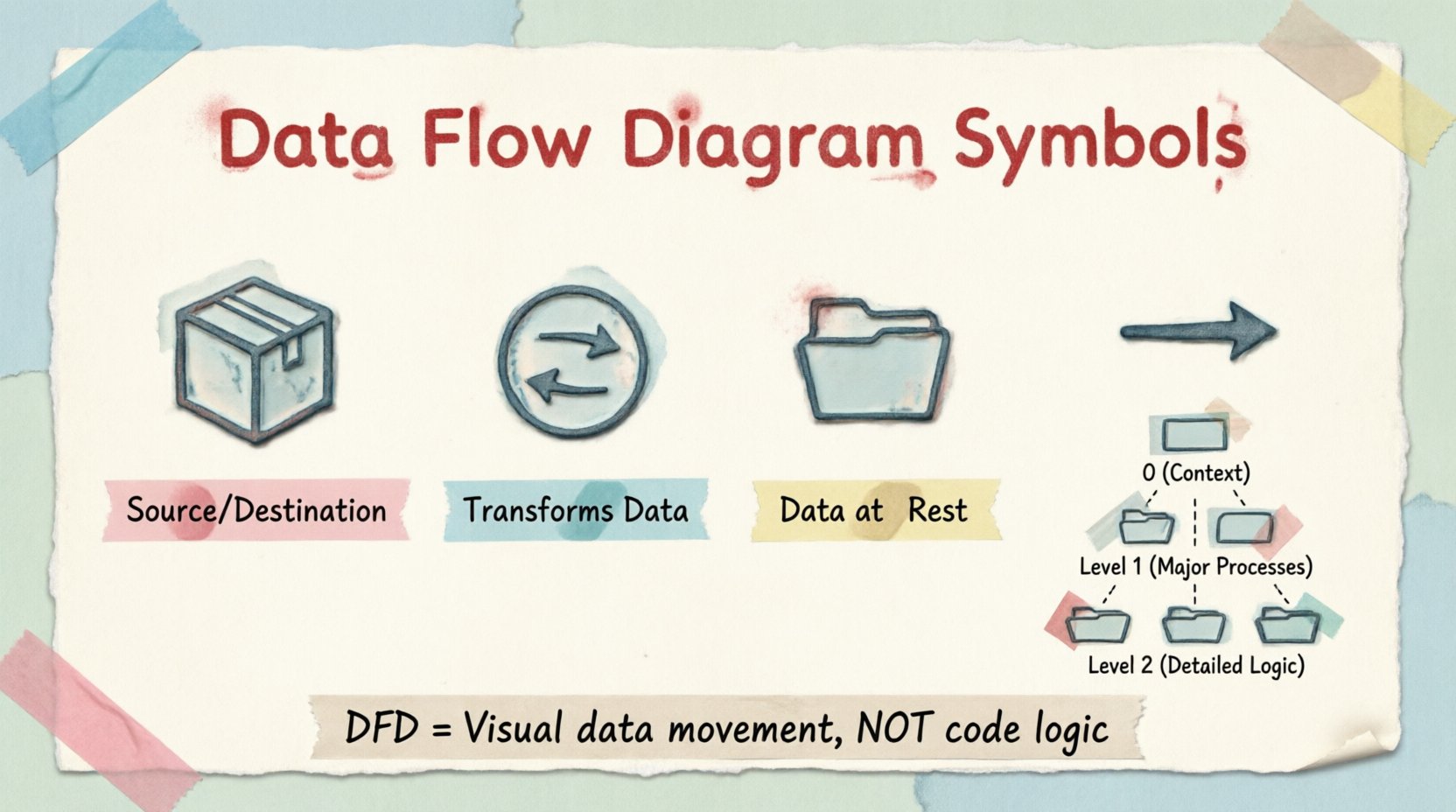
La notation standard des DFD repose sur quatre formes principales. Bien que des variations existent entre différentes méthodologies (telles que Yourdon/DeMarco ou Gane/Sarson), les concepts fondamentaux restent constants. Chaque symbole représente une fonction spécifique à l’intérieur de la frontière du système.
| Nom du symbole | Représentation visuelle | Fonction |
|---|---|---|
| Entité externe | Rectangle | Source ou destination des données |
| Processus | Cercle ou rectangle arrondi | Transformation des données |
| Stockage de données | Rectangle ouvert | Stockage des données au repos |
| Flux de données | Flèche | Mouvement des données |
1. Entité externe 📦
Les entités externes représentent les sources ou destinations des données situées à l’extérieur du système modélisé. Ce sont les acteurs qui interagissent avec le système mais qui ne font pas partie de sa logique interne. Une entité peut être une personne, un groupe, un autre système informatique ou un département.
Les entités sont généralement dessinées sous forme de rectangles. Dans certaines notations, elles peuvent apparaître sous forme d’ovales. La caractéristique principale est que le système envoie des données à ces entités ou reçoit des données d’elles. Par exemple, un client est une entité. Le système traite sa commande, mais le client existe indépendamment du logiciel de traitement des commandes.
- Entrée : Les données entrent dans le système depuis l’entité.
- Sortie : Les données quittent le système et vont vers l’entité.
Il est important de ne pas confondre les entités externes avec les processus. Une entité ne transforme pas les données ; elle les génère simplement ou les consomme.
2. Processus 🔄
Les processus sont les éléments actifs du diagramme. Ils représentent des fonctions qui transforment les données d’entrée en données de sortie. Un processus est le travail qui est effectué. Il peut s’agir d’un calcul, d’une vérification de validation, d’une décision ou d’une routine de manipulation des données.
Les processus sont généralement dessinés sous forme de cercles ou de rectangles arrondis. À l’intérieur de la forme, vous placez un nom qui décrit l’action, par exemple « Calculer le total » ou « Valider la connexion ». Chaque processus doit avoir au moins une entrée et au moins une sortie. Un processus qui reçoit des données mais ne produit rien est incomplet.
Les processus sont numérotés pour indiquer la hiérarchie. Par exemple, « Processus 1 » peut être décomposé en « Processus 1.1 », « Processus 1.2 », etc. Ce numéro permet de suivre les niveaux de détail à travers différents diagrammes.
3. Magasin de données 📁
Les magasins de données représentent les endroits où les données sont conservées pour une utilisation future. Ce sont des répertoires. Dans un système physique, cela pourrait être une table de base de données, un fichier ou un classeur physique. Dans un schéma logique, il s’agit simplement de l’endroit où les données sont stockées.
Les formes courantes incluent des rectangles ouverts ou des lignes parallèles. Le nom à l’intérieur du magasin doit être au pluriel, indiquant une collection d’enregistrements, par exemple « Fichiers clients » ou « Registres de commandes ».
- Lire :Un processus lit les données depuis un magasin afin de les utiliser.
- Écrire :Un processus écrit des données dans un magasin afin de les sauvegarder.
Les flux de données entrent et sortent des magasins. Il est crucial de noter que les flux de données ne peuvent pas traverser sans passer par un processus. Vous ne pouvez pas tracer une ligne directe entre deux magasins de données ; un processus doit se trouver entre les deux pour définir la raison du déplacement des données.
4. Flux de données ➡️
Les flux de données sont les flèches qui relient les symboles. Elles représentent le déplacement des données à travers le système. Contrairement au flux de contrôle en programmation, le flux de données représente des paquets d’informations réels.
Chaque flèche doit être étiquetée avec le nom des données qui la traversent. Par exemple, une flèche d’un Client vers un Processus pourrait être étiquetée « Demande de commande ». Une flèche d’un Processus vers un Magasin de données pourrait être étiquetée « Nouvel enregistrement de commande ».
Les flèches doivent avoir une seule direction. Si les données se déplacent dans les deux sens entre deux points, utilisez deux flèches distinctes. L’étiquette doit être au singulier ou au pluriel de manière cohérente. Évitez les étiquettes vagues comme « Données » ou « Information ». Soyez précis, par exemple « Adresse d’expédition » ou « Rapport d’inventaire ».
Comprendre les niveaux des diagrammes de flux de données 📈
Les diagrammes de flux de données sont créés par couches pour gérer la complexité. Cette approche est connue sous le nom de décomposition.
Niveau 0 : Le diagramme de contexte
Le diagramme de niveau 0 est le niveau le plus élevé. Il représente l’ensemble du système comme un seul processus. Il met en évidence la relation entre le système et les entités externes. Cette vue répond à la question : « Quelle est la frontière du système ? »
Dans ce diagramme, il n’y a qu’un seul nœud de processus. Tous les flux de données relient directement les entités externes à ce processus central. Aucun magasin de données interne n’est affiché à ce niveau, car les fonctions internes sont masquées.
Niveau 1 : Les principaux processus
Le diagramme de niveau 1 éclate le processus unique du niveau 0 en ses principaux sous-processus. Cela divise le système en éléments gérables. Vous verrez plusieurs nœuds de processus, des magasins de données et les flux spécifiques qui les relient.
Ce niveau définit les principales zones fonctionnelles. Par exemple, un système de commerce électronique pourrait se diviser en « Gérer l’inventaire », « Traiter le paiement » et « Gérer l’expédition ». Chacun de ces éléments représente un processus majeur.
Niveau 2 : Logique détaillée
Les diagrammes de niveau 2 approfondissent des processus spécifiques du niveau 1. Si un processus du niveau 1 est complexe, il obtient son propre diagramme. Cela permet aux analystes de détailler chaque étape d’une fonction spécifique sans encombrer la vue globale.
À ce stade, la notation devient plus fine. Vous pouvez voir plusieurs magasins de données et des routages complexes des flux de données. C’est là que les règles métier spécifiques sont souvent visualisées.
Règles et conventions ✅
Pour maintenir la clarté, les diagrammes de flux de données doivent respecter des règles strictes. Leur violation peut entraîner de la confusion et des malentendus.
Consistance dans la nomenclature
Le même flux de données doit avoir le même nom partout où il apparaît. Si vous étiquetez un flux « ID utilisateur » sur un diagramme, il ne peut pas être « Numéro d’identification » sur un autre. La cohérence aide à suivre les données à travers les niveaux.
Pas de trous noirs ni de miracles
Un « trou noir » est un processus ayant des entrées mais aucune sortie. Cela implique que les données disparaissent, ce qui est généralement incorrect. Un « miracle » est un processus ayant une sortie mais aucune entrée. Cela implique que les données apparaissent de nulle part. Les deux sont des erreurs logiques dans le diagramme.
Équilibre des magasins de données
Lorsque vous décomposez un processus, les magasins de données connectés au processus parent doivent rester connectés aux processus enfants. Vous ne pouvez pas supprimer un magasin de données au niveau inférieur sauf si la logique change considérablement. Le flux de données doit être équilibré entre les niveaux.
Direction des flèches
Les flèches indiquent la direction. Ne dessinez pas de flèches qui se croisent inutilement. Les lignes qui se croisent rendent le diagramme difficile à lire. Utilisez des courbures ou des interruptions pour garder les trajets clairs. Si deux flux se croisent, assurez-vous que les types de données sont distincts afin d’éviter toute confusion.
Diagramme de flux de données vs. organigramme 🧩
Il est fréquent de confondre les diagrammes de flux de données avec les organigrammes. Bien qu’ils aient une apparence similaire, ils ont des objectifs différents.
Un organigramme décrit la logique et la séquence des opérations. Il montre les points de décision (losanges), les boucles et l’ordre exact des étapes. Il est procédural. Il répond à la question : « Comment le système s’exécute-t-il ? »
Un diagramme de flux de données décrit le déplacement des données. Il ne montre pas explicitement les boucles ou la logique de décision. Il se concentre sur le « Quoi » et le « Où » des données. Il répond à la question : « Quelles données sont déplacées et transformées ? »
Utiliser un diagramme de flux de données pour la logique de contrôle est une erreur. Il ne doit pas contenir de losanges de décision. Si vous devez montrer de la logique, utilisez un tableau de décision ou une description en anglais structuré aux côtés du diagramme de flux de données. Cette séparation des préoccupations maintient le diagramme propre.
Application pratique 📝
Lors de la construction d’un diagramme, commencez par le diagramme de contexte. Identifiez la frontière du système. Dessinez les entités externes. Dessinez le processus unique représentant le système. Dessinez les flux qui les relient.
Ensuite, passez au niveau 1. Divisez le processus central en fonctions majeures. Identifiez où les données sont stockées. Assurez-vous que chaque processus dispose d’entrées et de sorties. Vérifiez que les flux correspondent au diagramme de contexte.
Faites passer le diagramme en revue avec les parties prenantes. Demandez si les flux correspondent à leur compréhension du métier. Si une partie prenante déclare : « Nous ne stockons pas ces données ici », ajustez les magasins de données. Si elle déclare : « Nous ne transmettons pas de données à cette personne », ajustez les entités.
La validation est essentielle. Un diagramme mal compris par les utilisateurs est inutile. Il sert d’outil de communication. Il comble le fossé entre les équipes techniques et les propriétaires métier.
Meilleures pratiques pour la clarté 🌟
Maintenez le nombre de symboles sur une seule page raisonnable. Si un diagramme devient trop chargé, il perd de sa valeur. Utilisez des sous-diagrammes pour le décomposer. Ne tentez pas de représenter l’ensemble du système sur une seule feuille si cela dépasse la capacité visuelle.
Utilisez une notation standard. Bien qu’il existe des variations, restez fidèle à un seul style (par exemple, Yourdon/DeMarco ou Gane/Sarson) pour éviter toute confusion. N’utilisez pas plusieurs styles dans le même document.
Tout doit être étiqueté. Les flèches non étiquetées sont sans sens. Les processus non étiquetés sont ambigus. Même les formes simples nécessitent des noms pour transmettre un sens.
Évitez les croisements de lignes. Cela crée un bruit visuel. Si des lignes doivent se croiser, utilisez un « saut » ou une interruption dans la ligne pour indiquer qu’elles ne se croisent pas.
Résumé des significations des symboles 📋
Pour résumer les composants principaux :
- Entité : À l’extérieur du système. Source ou puits.
- Processus : À l’intérieur du système. Transforme les données.
- Stockage : À l’intérieur du système. Stocke les données.
- Flux : Connecte les éléments ci-dessus. Déplace les données.
Maîtriser ces symboles vous permet de documenter clairement des systèmes complexes. Il fournit un langage commun pour les analystes et les développeurs. En respectant les règles de décomposition et de cohérence, vous créez des diagrammes qui ne sont pas seulement des dessins, mais des spécifications fonctionnelles.
Commencez simplement. Construisez le contexte. Développez les détails. Vérifiez auprès des utilisateurs. Ce processus itératif garantit que le diagramme reflète la réalité.