










Eine effektive Systemgestaltung beginnt mit dem Verständnis der Datenbewegung innerhalb einer Organisation. Wenn Teams versuchen, komplexe Software ohne eine klare Karte zu entwickeln, treten häufig Abweichungen zwischen den geschäftlichen Anforderungen und der technischen Umsetzung auf. Die Modellierung von Informationssystemen bietet einen strukturierten Ansatz, um diese Wechselwirkungen zu visualisieren. Im Zentrum dieser Praxis steht das Datenflussdiagramm, ein leistungsfähiges Werkzeug zur Dokumentation der Verarbeitung, Speicherung und Übertragung von Informationen.
In diesem Artikel werden die Prinzipien der Modellierung von Informationssystemen aus der Perspektive von Datenflussdiagrammen (DFDs) untersucht. Wir werden die Komponenten, Abstraktionsstufen und analytischen Techniken betrachten, die erforderlich sind, um robuste Systemmodelle zu erstellen. Indem man sich auf die Logik der Datenbewegung konzentriert und nicht auf die physische Implementierung, können Analysten Klarheit und Genauigkeit sicherstellen, bevor überhaupt Code geschrieben wird.
Verständnis des Zwecks der Systemmodellierung 🧩
Bevor man sich spezifischen Symbolen zuwendet, ist es entscheidend, zu verstehen, warum wir Systeme modellieren. Ein Informationssystem ist mehr als nur eine Datenbank oder eine Benutzeroberfläche; es ist ein Netzwerk von Prozessen, die Eingaben in nützliche Ausgaben umwandeln. Die Modellierung ermöglicht es den Stakeholdern, das Gesamtbild zu erkennen, ohne in technische Details abzurutschen.
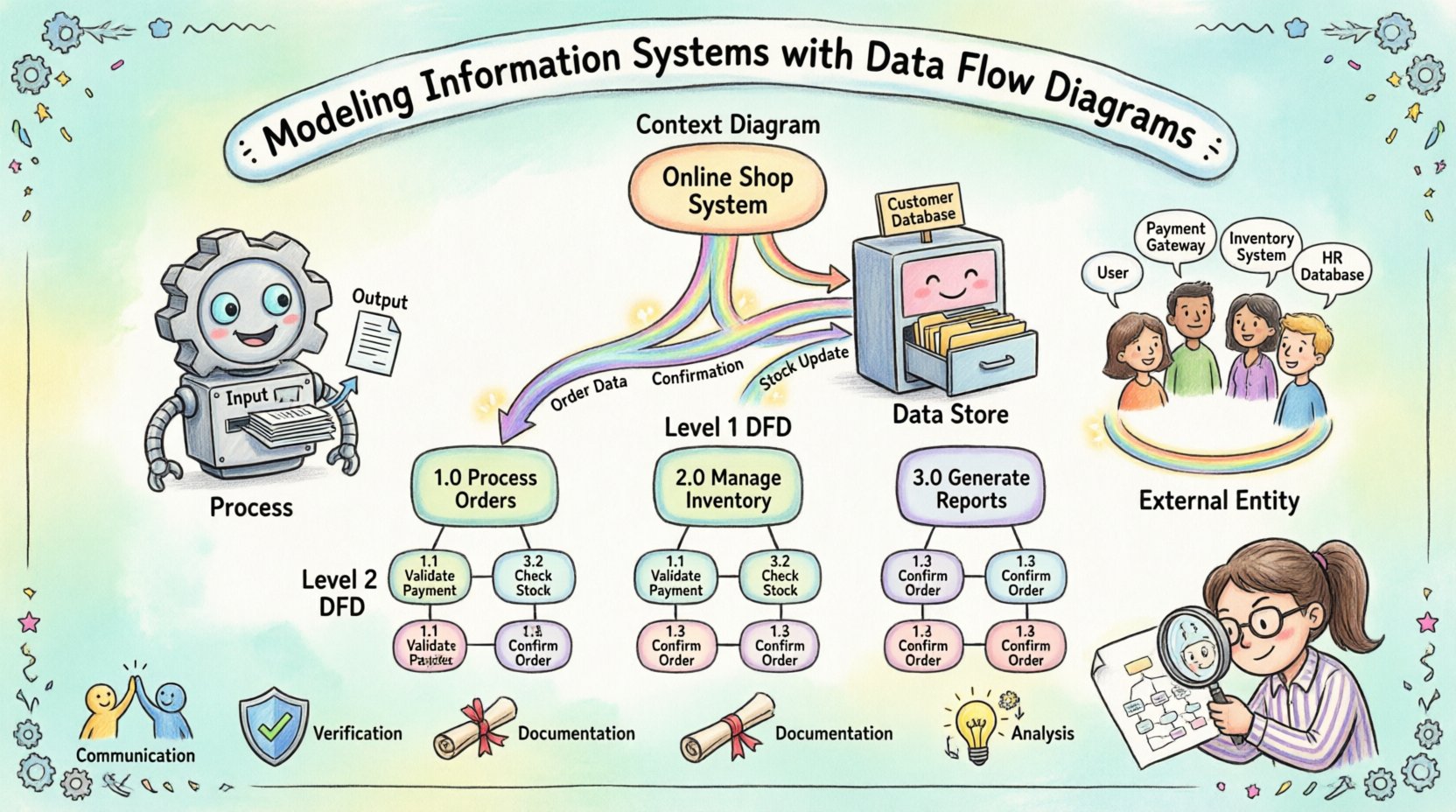
- Kommunikation:Visuelle Diagramme schließen die Lücke zwischen technischen Teams und Geschäftsanwendern. Jeder kann den gleichen Informationsfluss sehen.
- Verifikation:Modelle helfen dabei, sicherzustellen, dass alle geschäftlichen Anforderungen berücksichtigt sind, bevor die Entwicklung beginnt.
- Dokumentation:Sie dienen als dauerhafte Aufzeichnung, wie das System funktioniert, und sind nützlich für zukünftige Wartung und Schulung.
- Analyse:Diagramme offenbaren Engpässe, redundante Prozesse und potenzielle Sicherheitslücken bei der Datenverarbeitung.
Wenn Sie ein Informationssystem modellieren, erstellen Sie im Grunde ein Bauplan. Ebenso wie ein Architekt ein Haus nicht ohne Plan baut, sollte ein Systemarchitekt auch keine Logik ohne Karte schreiben. Dieser Ansatz reduziert Nacharbeit und stellt sicher, dass das Endprodukt den organisatorischen Zielen entspricht.
Die zentralen Komponenten eines Datenflussdiagramms 🏗️
Ein Datenflussdiagramm basiert auf vier Hauptelementen, um das System darzustellen. Jedes Element hat eine spezifische Rolle und eine visuelle Darstellung. Das Verständnis dieser Bausteine ist der erste Schritt zur Erstellung eines gültigen Modells.
1. Prozesse ⚙️
Prozesse stellen Aktionen dar, die Daten umwandeln. Sie sind die Triebwerke des Systems. Ein Prozess nimmt Eingabedaten entgegen, führt eine Operation durch und erzeugt Ausgabedaten. In einem Diagramm wird ein Prozess oft als Kreis oder eine abgerundete Rechteck dargestellt. Er muss einen Namen haben, der die Aktion beschreibt, wie beispielsweise „Steuer berechnen“ oder „Anmeldung validieren“.
Jeder Prozess muss mindestens eine Eingabe und eine Ausgabe haben. Ein Prozess kann nicht einfach existieren, ohne Daten zu verändern. Wenn Daten in einen Prozess eintreten, aber nichts herauskommt, ist das Modell unvollständig. Wenn Daten herausgehen, ohne einzutreten, ist die Ausgabe nicht erklärt. Dieses Erhaltungsprinzip stellt logische Konsistenz sicher.
2. Datenbanken 🗄️
Datenbanken stellen Orte dar, an denen Informationen für spätere Verwendung gespeichert werden. Dazu gehören physische Datenbanken, Dateien oder sogar physische Aktenordner. In einem DFD wird eine Datenbank typischerweise als offenes Rechteck oder zwei parallele Linien dargestellt. Im Gegensatz zu Prozessen verändern Datenbanken die Daten nicht; sie bewahren sie auf.
Es ist entscheidend, zwischen einem Prozess und einer Datenbank zu unterscheiden. Ein Prozess verändert den Zustand der Daten, während eine Datenbank sie bewahrt. Verbindungen zwischen Prozessen und Datenbanken zeigen an, dass Daten aus der Speicherung gelesen oder in sie geschrieben werden. Diese Unterscheidung hilft zu klären, ob Informationen aktiv verarbeitet werden oder lediglich archiviert werden.
3. Externe Entitäten 👥
Externe Entitäten sind Quellen oder Zielorte von Daten außerhalb der Systemgrenze. Sie interagieren mit dem System, sind aber nicht Teil der internen Logik. Beispiele hierfür sind Kunden, Lieferanten, Aufsichtsbehörden oder andere Systeme. In Diagrammen werden sie oft als Quadrate oder Rechtecke dargestellt.
Beim Modellieren ist es wichtig, den Umfang klar zu definieren. Was befindet sich innerhalb des Systems und was außerhalb? Eine externe Entität ist alles, was Sie innerhalb des aktuellen Modells nicht direkt steuern oder verändern können. Dies hilft, die Analyse auf die Grenzen der Verantwortung zu fokussieren.
4. Datenflüsse 🔄
Datenflüsse zeigen die Bewegung von Informationen zwischen Prozessen, Speichern und Entitäten an. Sie werden durch Pfeile dargestellt. Jeder Pfeil muss eine Beschriftung haben, die die übertragenen Daten beschreibt, wie beispielsweise „Bestelldetails“ oder „Zahlungsbestätigung“.
Datenflüsse stellen keine Steuersignale oder Zeitpunkte dar. Sie repräsentieren den eigentlichen Informationsinhalt. Ein Fluss kann sich teilen oder vereinigen, muss aber immer sinnvolle Daten tragen. Pfeile sollten unnötig nicht kreuzen, um die Lesbarkeit zu gewährleisten. Wenn ein Fluss zwei Prozesse verbindet, zeigt dies eine direkte Übergabe von Informationen an.
Abstraktionsstufen und Zerlegung 🔍
Komplexe Systeme können nicht in einer einzigen Sicht verstanden werden. Um die Komplexität zu bewältigen, verwenden Analysten die Zerlegung, bei der das System in handhabbare Schichten aufgeteilt wird. Dieser hierarchische Ansatz ermöglicht unterschiedliche Detailgrade je nach Zielgruppe und Zweck.
Kontextdiagramm (Ebene 0)
Das Kontextdiagramm bietet die höchste Abstraktionsstufe. Es zeigt das gesamte System als einen einzigen Prozess und identifiziert alle externen Entitäten, die mit ihm interagieren. Diese Sicht beantwortet die Frage: „Was ist das System?“ Es definiert die Grenzen klar.
In diesem Diagramm sehen Sie keine internen Prozesse oder Datenbanken. Sie sehen nur die Systemgrenze und den Datenfluss hinein und hinaus. Dies ist oft das erste Diagramm, das erstellt wird, um die Zustimmung der Stakeholder zum Umfang zu erhalten.
Ebene-1-Diagramm
Das Ebene-1-Diagramm erweitert den einzelnen Prozess aus dem Kontextdiagramm in wesentliche Unterverfahren. Es zeigt die wichtigsten funktionalen Bereiche des Systems auf. Beispielsweise könnte ein „Auftrag verwalten“-Prozess in „Auftrag empfangen“, „Bestand prüfen“ und „Zahlung bearbeiten“ zerlegt werden.
Diese Ebene führt Datenbanken ein und zeigt, wie Daten zwischen den Hauptfunktionen fließen. Sie ist detailliert genug, damit technische Teams die Architektur verstehen können, aber abstrakt genug, um nicht in spezifische Logik verstrickt zu werden.
Ebene 2 und darüber
Weitere Zerlegung erfolgt, bis jeder Prozess einfach genug ist, um ohne weitere Aufteilung verstanden zu werden. Hier werden oft spezifische Geschäftsregeln dokumentiert. Auf dieser Ebene dient das Diagramm als direkte Referenz für Entwickler, die Code schreiben.
Die Zerlegung muss ausgewogen sein. Die Eingaben und Ausgaben eines übergeordneten Prozesses müssen mit den Eingaben und Ausgaben seiner untergeordneten Prozesse übereinstimmen. Wenn ein Prozess in drei untergeordnete Prozesse aufgeteilt wird, müssen die Daten, die in den übergeordneten Prozess eingehen, gemeinsam in die untergeordneten Prozesse eingehen, und die Daten, die aus den untergeordneten Prozessen austreten, müssen auch den übergeordneten Prozess verlassen.
Notationsstandards und Konsistenz 📏
Während die Konzepte von DFDs universell sind, können die verwendeten Symbole variieren. In der Branche existieren zwei Hauptnotationen. Die Auswahl einer und die strikte Einhaltung derselben sind entscheidend für Klarheit.
| Funktion | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| Prozess | Kreis oder abgerundetes Rechteck | Abgerundetes Rechteck |
| Datenbank | Offenes Rechteck | Offenes Rechteck (mit dickem Strich) |
| Externe Entität | Rechteck | Rechteck |
| Datenfluss | Gekrümmter oder gerader Pfeil | Gerader Pfeil |
Konsistenz verhindert Verwirrung. Wenn ein Team während eines Projekts die Notation wechselt, wird die Dokumentation fragmentiert. Es ist am besten, frühzeitig einen Standard festzulegen und ihn in einer Stilrichtlinie zu dokumentieren.
Zusätzlich sollten Namenskonventionen konsistent sein. Verwenden Sie Verben für Prozesse (z. B. „Datensatz aktualisieren“) und Substantive für Datenflüsse (z. B. „Datensatzdaten“). Diese grammatische Unterscheidung hilft den Lesern, die Funktion jedes Elements schnell zu erkennen.
Analyse des Systems zur Verbesserung 🛠️
Das Erstellen eines Diagramms geht nicht nur um Dokumentation; es geht um Analyse. Sobald das Modell existiert, können Sie es untersuchen, um Ineffizienzen oder Risiken zu finden.
Identifizierung von Engpässen
Suchen Sie nach Prozessen, die mehrere Eingaben erhalten, aber nur eine Ausgabe erzeugen. Diese Bereiche werden oft zu Engpässen, an denen sich Arbeit ansammelt. Hohe Datenströme zwischen zwei bestimmten Punkten können auf die Notwendigkeit einer Optimierung oder einer parallelen Verarbeitung hinweisen.
Überprüfung der Datenintegrität
Überprüfen Sie, wie Daten gespeichert und abgerufen werden. Sind sensible Datenflüsse im Modell verschlüsselt? Werden Datenbanken vor dem Schreiben validiert? Ein gut modelliertes System stellt die Datenqualität auf jeder Stufe sicher. Wenn Datenflüsse direkt ohne Validierung in eine Datenbank fließen, zeigt das Modell ein potenzielles Risiko auf.
Beseitigung von Redundanz
Sehen Sie denselben Prozess an verschiedenen Stellen des Diagramms wiederholt? Dies deutet auf Redundanz hin. Möglicherweise können Sie Funktionen in einen einzigen Dienst zusammenfassen. Die Reduzierung von Duplikaten spart Ressourcen und vereinfacht die Wartung.
Überprüfung der Vollständigkeit
Stellen Sie sicher, dass jede externe Entität einen entsprechenden Datenfluss hat. Wenn ein Kunde existiert, aber kein Datenfluss zu oder von ihm erfolgt, ist das Modell unvollständig. Überprüfen Sie außerdem, dass jede Datenbank sowohl einen Schreiber als auch einen Leser hat. Eine verwaiste Datenbank deutet auf ungenutzten Speicher hin.
Best Practices für Wartung und Evolution 🌱
Informationssysteme sind nicht statisch. Sie entwickeln sich weiter, je nachdem, wie sich die geschäftlichen Anforderungen ändern. Ein Modell, das heute genau ist, kann morgen bereits veraltet sein. Daher ist die Pflege der Dokumentation genauso wichtig wie ihre Erstellung.
Versionskontrolle
Verfolgen Sie Änderungen an den Diagrammen. Versionsnummern oder Daten sollten sichtbar sein. Dies hilft Teams zu verstehen, was sich geändert hat und warum. Es ermöglicht außerdem eine Rückgängigmachung, falls ein neues Design problematisch erweist.
Überprüfung durch Beteiligte
Überprüfen Sie Modelle regelmäßig gemeinsam mit den Geschäftsanwendern. Sie sind die beste Quelle für die Wahrheit, ob das System ihren Arbeitsabläufen entspricht. Wenn ein Prozess der Realität nicht entspricht, ist das Modell falsch, egal wie logisch es erscheinen mag.
Integration mit anderen Modellen
DFDs existieren nicht isoliert. Sie verbinden sich oft mit Entitäts-Beziehungs-Diagrammen (ERDs) für die Datenstruktur und Zustandsübergangsdiagrammen für das Systemverhalten. Die Abstimmung dieser Modelle verhindert Widersprüche zwischen Prozesslogik und Datenstruktur.
Die Rolle des Analysten 🧑💼
Der Erfolg der Modellierung hängt stark vom Analysten ab. Er muss als Übersetzer zwischen Geschäftssprache und technischer Logik agieren. Dazu sind starke Kommunikationsfähigkeiten und ein tiefes Verständnis des Fachgebiets erforderlich.
Ein effektiver Analyst stellt durchdringende Fragen. „Woher stammt diese Daten?“ „Was passiert, wenn diese Eingabe fehlt?“ „Wer ist für diese Aktualisierung verantwortlich?“ Diese Fragen bringen versteckte Anforderungen ans Licht, die Beteiligte möglicherweise übersehen.
Geduld ist ebenfalls entscheidend. Die Modellierung ist iterativ. Erste Diagramme werden vermutlich falsch oder unvollständig sein. Ziel ist es, sie durch Feedback zu verfeinern. Fürchten Sie sich nicht davor, ein Diagramm zu verwerfen, wenn es nicht funktioniert; nutzen Sie die gelernten Erkenntnisse, um ein besseres zu erstellen.
Fazit und letzte Überlegungen 🚀
Die Modellierung von Informationssystemen mithilfe von Datenflussdiagrammen ist eine grundlegende Fähigkeit für alle, die an der Systemgestaltung beteiligt sind. Sie bietet eine klare, visuelle Sprache zur Diskussion komplexer Prozesse. Indem man sich auf die Datenbewegung statt auf Implementierungsdetails konzentriert, können Teams eine bessere Abstimmung erreichen und Fehler reduzieren.
Die Reise von einem einfachen Kontextdiagramm zu einem detaillierten Level-2-Modell erfordert Disziplin und Sorgfalt. Doch der Ertrag ist ein System, das einfacher zu verstehen, zu pflegen und zu verbessern ist. Da Organisationen weiterhin auf digitale Lösungen angewiesen sind, bleibt die Fähigkeit, deren Logik abzubilden, ein entscheidender Vorteil.
Beginnen Sie mit den Grundlagen. Definieren Sie Ihre Grenzen. Zerlegen Sie Ihre Prozesse. Überprüfen Sie Ihre Arbeit. Mit Übung wird das Erstellen dieser Modelle zur zweiten Natur und führt zu robusteren und effizienteren Informationssystemen.