











Die Gestaltung einer robusten Zustandsmaschine ist eine der wichtigsten Aufgaben in der Systemarchitektur. Wenn sie korrekt implementiert wird, bieten Zustandsdiagramme Klarheit, Vorhersagbarkeit und Wartbarkeit. Wenn jedoch die Logik fehlerhaft ist, kann das System in einen Zustand gelangen, aus dem keine weitere Fortschrittsmöglichkeit besteht. Dies wird als Deadlock bezeichnet. In einem Zustandsmaschinen-Diagramm tritt ein Deadlock auf, wenn das System einen Zustand erreicht, aus dem keine gültige Übergangsmöglichkeit existiert, wodurch die Ausführung unbegrenzt angehalten wird. ⏸️
Diese Anleitung untersucht die Mechanismen der Zustandsmaschinen-Gestaltung mit besonderem Fokus auf die Erkennung und Verhinderung von Deadlocks. Wir behandeln Übergangsbedingungen, Eingangs- und Ausgangsaktionen, konkurrierende Bereiche sowie Validierungsstrategien. Durch die Anwendung dieser strukturierten Ansätze können Sie sicherstellen, dass Ihre Zustandsdiagramme unter verschiedenen Bedingungen stabil bleiben. 🔒
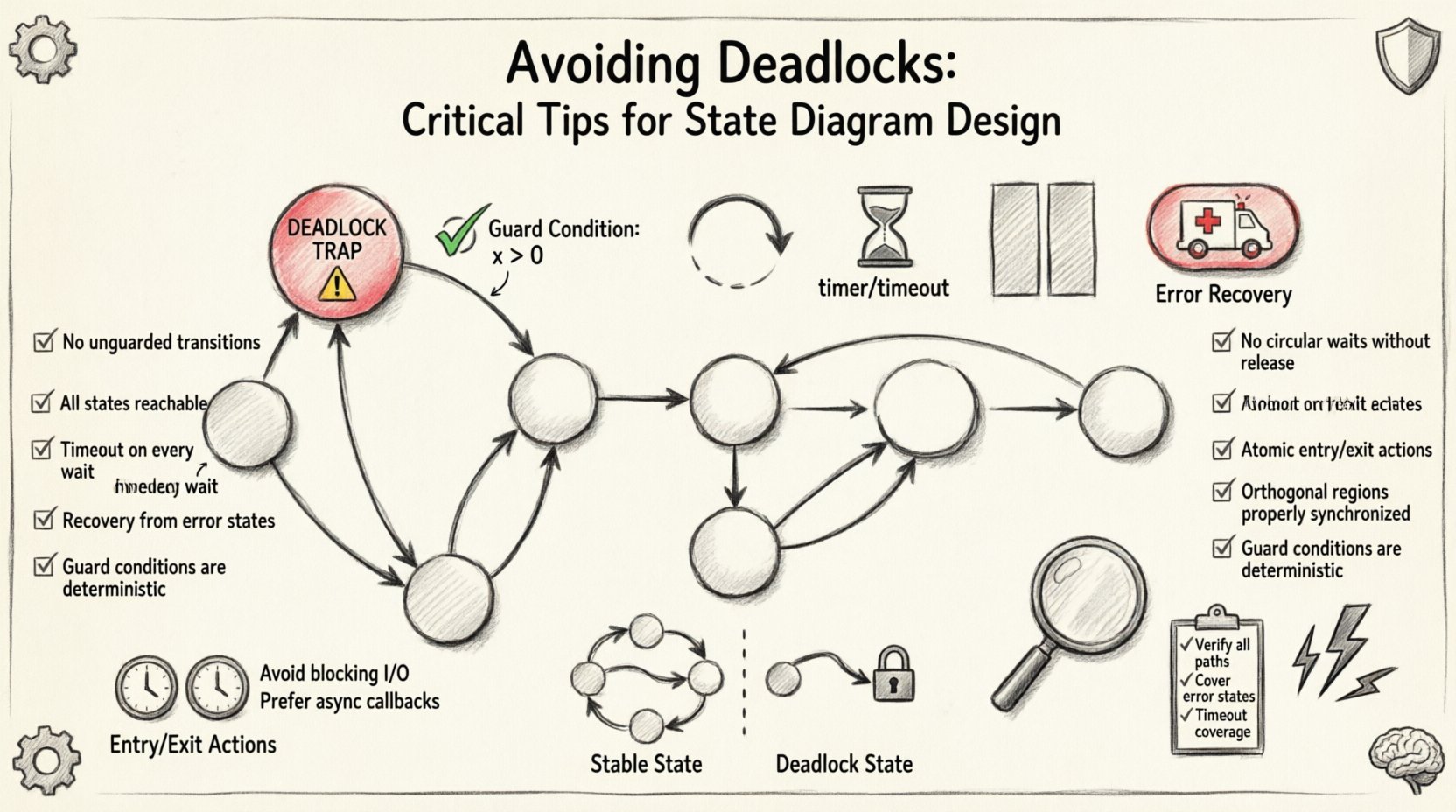
🧠 Verständnis von Deadlocks in Zustandsmaschinen
Ein Deadlock in einer endlichen Zustandsmaschine (FSM) stellt eine logische Anhaltspunkte dar. Im Gegensatz zu einem Laufzeitfehler, der die Anwendung zum Absturz bringen könnte, führt ein Deadlock oft dazu, dass das System den Anschein hat, eingefroren zu sein, während es weiterhin läuft. Die Engine ist aktiv, kann aber keine Befehle ausführen, da der aktuelle Zustand keine ausgehenden Übergänge besitzt, die die Auslösebedingungen erfüllen. 🔍
Um effektiv zu gestalten, muss man die Struktur eines Deadlock-Szenarios verstehen. Er wird selten durch eine einzelne fehlende Codezeile verursacht. Stattdessen entsteht er oft aus komplexen Wechselwirkungen zwischen mehreren Zuständen, Bedingungen und externen Ereignissen. Nachfolgend sind die zentralen Merkmale eines Deadlock-Zustands aufgeführt:
- Keine ausgehenden Übergänge: Der Zustand besitzt keine Pfeile, die von ihm wegzeigen.
- Unerreichbare Übergänge: Alle ausgehenden Pfeile haben Bedingungen, die unter den aktuellen Daten niemals wahr werden können.
- Fehlende Standardpfade: Es gibt keinen Rückfallübergang, um unerwartete Eingaben zu behandeln.
- Ressourcenbehalte: Das System hält eine Ressource (z. B. eine Sperre oder Verbindung) fest, wartet aber auf eine andere Bedingung, die niemals eintreten wird.
Die Verhinderung solcher Szenarien erfordert eine proaktive Gestaltungsphilosophie anstatt reaktives Debugging. Lassen Sie uns die Ursachen im Detail untersuchen. 📉
⚠️ Häufige Ursachen von Deadlocks bei der Zustandsgestaltung
Deadlocks sind keine zufälligen Unfälle; sie sind vorhersehbare Folgen bestimmter Gestaltungsentscheidungen. Das Verständnis dieser Muster hilft Ihnen, sie zu vermeiden, bevor sie die Produktion beeinträchtigen. Nachfolgend finden Sie die Hauptursachen für das Einfrieren von Zustandsmaschinen.
1. Fehlende Übergangsbedingungen
Bei der Gestaltung von Übergängen steht jeder Pfeil, der aus einem Zustand herausgeht, für einen möglichen Fortschritt. Wenn ein Zustand mehrere mögliche Eingaben (Ereignisse) hat, aber nur einige davon auf Übergänge abgebildet sind, hält das System an, wenn ein nicht abgebildetes Ereignis eintritt. Dies wird oft als „Fallen“-Zustand bezeichnet. ❌
- Das Problem: Eine Zustandsmaschine erwartet bestimmte Auslöser. Wenn ein unerwarteter Auslöser eintrifft und kein Übergang ihn verarbeitet, bleibt das System stehen.
- Die Lösung: Stellen Sie sicher, dass jeder Zustand alle definierten Ereignisse berücksichtigt, oder implementieren Sie einen globalen Standardhandler, um unerwartete Eingaben zu erfassen.
2. Konflikte bei den Bedingungen
Bedingungen sind boolesche Ausdrücke, die wahr sein müssen, damit ein Übergang ausgelöst wird. Ein häufiger Fehler tritt auf, wenn zwei Übergänge denselben Quellzustand und dasselbe Ereignis teilen, aber ihre Bedingungen sich gegenseitig ausschließen oder keinen möglichen Fall abdecken. 🧩
- Das Problem: Sie definieren Übergang A (wenn Punktzahl > 10) und Übergang B (wenn Punktzahl < 5). Was passiert, wenn die Punktzahl genau 10 beträgt? Bei strenger Logik könnte beides scheitern.
- Die Lösung: Überprüfen Sie die Bedingungen auf Randfälle. Stellen Sie sicher, dass die Vereinigung aller Bedingungen für ein bestimmtes Ereignis den gesamten Eingabebereich abdeckt.
3. Zirkuläre Abhängigkeiten
In komplexen Systemen können Zustände vom Status anderer Zustände oder externer Prozesse abhängen. Wenn Zustand A auf das Beenden von Zustand B wartet und Zustand B auf die Bestätigung von Zustand A wartet, bewegt sich keiner. Dies ist ein klassischer Synchronisations-Deadlock. ⏳
- Das Problem:Die Logik ist derart verflochten, dass eine gegenseitige Bestätigung erforderlich ist, bevor eine Fortschrittsbewegung möglich ist.
- Die Lösung:Brechen Sie die Schleife durch Einführung von Zeitüberschreitungen oder durch Erlaubnis eines Prozesses, weiterzumachen, ohne die sofortige Bestätigung des anderen Prozesses.
4. Falsche Behandlung von Historie-Zuständen
Historie-Zustände ermöglichen es einem System, seinen vorherigen Zustand beim erneuten Eintreten zu merken. Wenn sie nicht korrekt implementiert sind, kann ein Historie-Zustand auf einen Zustand verweisen, der nicht mehr gültig ist oder gelöscht wurde. 🔄
- Das Problem:Die Maschine versucht, in einen historischen Zustand zu wechseln, der nicht mehr existiert oder nicht erreichbar ist.
- Die Lösung:Stellen Sie sicher, dass die historischen Ziele beim Neustart oder Zurücksetzen der Maschine weiterhin aktiv sind.
🛡️ Gestaltungsmuster zur Verhinderung von Blockierungen
Sobald Sie die Risiken verstehen, können Sie spezifische Muster anwenden, um sie zu mindern. Diese Muster sind nicht software-spezifisch; sie gelten für jede Modelliersprache oder Implementierungsplattform. 🛠️
1. Das Standardzustandsmuster
Jede Zustandsmaschine sollte einen definierten Einstiegspunkt haben. Dies ist typischerweise der Anfangszustand. Doch abgesehen vom Anfangszustand sollte jeder andere Zustand idealerweise einen Standardpfad haben. Wenn ein Ereignis keiner spezifischen Bedingung entspricht, sollte das System auf ein sicheres Standardverhalten zurückgreifen. 📍
- Implementierung:Erstellen Sie für jeden Zustand einen „Alles-erfassenden“ Übergang, der unbekannte Ereignisse reibungslos behandelt.
- Vorteil:Verhindert, dass das System in einen undefinierten Zustand gerät, wenn eine unerwartete Eingabe erfolgt.
2. Das Timeout-Schutzmuster
Manchmal muss ein Zustand auf ein externes Ereignis warten, das niemals eintreffen könnte. Um eine unendliche Wartezeit zu verhindern, können Sie einen Timer einführen. Wenn das Ereignis innerhalb einer festgelegten Dauer nicht eintrifft, löst ein Timeout-Übergang aus. ⏱️
- Implementierung:Fügen Sie einen Übergang hinzu, der durch ein zeitbasiertes Ereignis ausgelöst wird (z. B. „Timer abgelaufen“).
- Vorteil:Stellt sicher, dass das System immer weitergeht, auch wenn die primäre Bedingung nicht erfüllt ist.
3. Das parallele Zustandsmuster
Bei komplexen Workflows kann ein einziger Zustand nicht alle gleichzeitigen Aktivitäten erfassen. Orthogonale Regionen ermöglichen es Ihnen, einen Zustand in mehrere unabhängige Teilzustände zu unterteilen. Dadurch verringert sich die Komplexität der Übergangsbedingungen. ⚡
- Implementierung:Verwenden Sie zusammengesetzte Zustände mit mehreren Regionen, die gleichzeitig laufen.
- Vorteil: Vereinfacht die Logik durch Trennung der Anliegen. Wenn eine Region sich verhängt, kann die andere weiterarbeiten oder den Fehler melden.
4. Der Fehlerwiederherstellungszustand
Entwerfen Sie einen spezifischen Zustand, der der Fehlerbehandlung gewidmet ist. Wenn das System eine Anomalie erkennt, wechselt es sofort in diesen Zustand. Von hier aus kann es versuchen, zurückzusetzen, erneut zu versuchen oder einen Bediener zu alarmieren. 🚑
- Implementierung: Fügen Sie einen dedizierten „Fehler“- oder „Wiederherstellung“-Zustand hinzu, der von mehreren Stellen aus erreichbar ist.
- Vorteil: Isoliert den Fehler und bietet einen klaren Weg zur Wiederherstellung, anstatt das System in einem defekten Zustand zu lassen.
📊 Vergleich: Verklemmung vs. Stabiler Zustand
Um den Unterschied zwischen einem gesunden Zustand und einer Verklemmung zu visualisieren, betrachten Sie die folgende Vergleichstabelle. Dies hebt die strukturellen Unterschiede in der Gestaltung hervor.
| Funktion | Stabiler Zustand | Verklemmungszustand |
|---|---|---|
| Übergänge | Es existiert mindestens ein gültiger ausgehender Übergang. | Keine ausgehenden Übergänge erfüllen die aktuellen Bedingungen. |
| Wächterlogik | Wächter decken alle relevanten Eingabeszenarien ab. | Wächter sind wechselseitig ausschließend oder unvollständig. |
| Ereignisbehandlung | Ereignisse lösen erwartete Aktionen aus. | Ereignisse werden ignoriert oder verursachen eine Anhalts. |
| Wiederherstellung | Das System korrigiert sich selbst oder geht zur nächsten Phase über. | Das System benötigt externe Intervention, um neu zu starten. |
🧪 Validierung- und Teststrategien
Das Design ist nur die halbe Miete. Sie müssen das Diagramm validieren, um sicherzustellen, dass es unter Stress standhält. Das Testen von Zustandsmaschinen erfordert einen anderen Ansatz als das Testen von Standardfunktionen. 🧪
1. Modellprüfung
Die Modellprüfung ist eine formale Verifizierungsmethode. Sie beweist mathematisch, dass eine Zustandsmaschine bestimmte Eigenschaften erfüllt, wie beispielsweise „kein Zustand ist erreichbar, in dem eine Verklemmung besteht“. Dies ist für kritische Systeme äußerst effektiv. 🔢
- Methode: Verwenden Sie formale Methoden-Tools, um den gesamten Zustandsraum zu durchlaufen.
- Ergebnis: Eine mathematische Garantie, dass das System keinen Deadlock-Zustand betreten kann.
2. Zustandsabdeckungsprüfung
Stellen Sie sicher, dass jeder Zustand und jeder Übergang mindestens einmal getestet wird. Dies wird als Zustandsabdeckung bezeichnet. Wenn ein Zustand nicht getestet wird, können Sie nicht wissen, ob er eine versteckte Deadlock-Bedingung enthält. 🎯
- Technik:Schreiben Sie Testfälle, die das System in jeden definierten Zustand zwingen.
- Ergebnis:Überprüfung, dass Übergänge korrekt von jedem Einstiegspunkt aus ausgelöst werden.
3. Stress-Tests für Eingaben
Senden Sie ungültige, null- oder unerwartete Eingaben an das System. Eine robuste Zustandsmaschine sollte bei schlechten Daten nicht abstürzen oder hängen bleiben. Sie sollte die Eingabe entweder ablehnen oder in einen sicheren Zustand wechseln. 🌪️
- Technik:Generieren Sie zufällige oder Grenzwert-Eingaben und beobachten Sie das Verhalten.
- Ergebnis:Identifikation von Randfällen, die zu Deadlocks führen.
4. Statische Analyse
Bevor Sie den Code ausführen, analysieren Sie die Diagrammstruktur. Suchen Sie nach Zuständen ohne ausgehende Pfeile. Suchen Sie nach Schleifen, die niemals enden. Werkzeuge können diese Muster oft automatisch erkennen. 🔎
- Technik:Führen Sie Linting- oder statische Analyse-Skripte auf den Zustandsdefinitionen aus.
- Ergebnis:Frühe Erkennung struktureller Fehler.
🔄 Umgang mit Konkurrenz und parallelen Zuständen
Konkurrenz erhöht die Komplexität. Wenn mehrere Regionen gleichzeitig arbeiten, können Deadlocks durch Synchronisationsprobleme entstehen. Sie müssen sicherstellen, dass parallele Pfade sich nicht gegenseitig blockieren. 🏗️
1. Unabhängige Regionen
Stellen Sie sicher, dass parallele Zustände wirklich unabhängig sind. Wenn Zustand A in Region 1 Daten von Zustand B in Region 2 benötigt, schaffen Sie eine Abhängigkeit. Diese Abhängigkeit kann sich zu einer Engstelle entwickeln. 🚧
- Best Practice:Minimieren Sie den Datenaustausch zwischen orthogonalen Regionen.
- Alternative:Verwenden Sie einen Ereignisbus, um zwischen Regionen zu kommunizieren, ohne direkte Blockierung.
2. Synchronisationspunkte
Manchmal müssen Zustände synchronisiert werden. Zum Beispiel muss Region A beendet sein, bevor Region B beginnt. Wenn Sie dies manuell implementieren, besteht die Gefahr eines Deadlocks. Verwenden Sie die von Ihrem Framework bereitgestellten integrierten Synchronisationskonstrukte. ⚙️
- Best Practice: Vermeiden Sie manuelle Sperrmechanismen, es sei denn, sie sind unbedingt erforderlich.
- Alternativ: Verwenden Sie Join-Zustände, die darauf warten, dass alle eingehenden Pfade natürlich abgeschlossen sind.
⚙️ Ein- und Ausgangsaktionen
Ein- und Ausgangsaktionen sind Code-Schnipsel, die ausgeführt werden, wenn ein Zustand betreten oder verlassen wird. Diese sind häufige Quellen subtiler Deadlocks. ⚠️
1. Blockierende Eingangsaktionen
Wenn eine Eingangsaktion eine langlaufende Aufgabe (wie einen Netzwerkaufruf) ohne Timeout ausführt, kann das System diesen Zustand nicht verlassen, bis die Aufgabe abgeschlossen ist. Wenn die Aufgabe hängt, hängt auch die Zustandsmaschine. 🕸️
- Best Practice: Halten Sie Eingangsaktionen leichtgewichtig und nicht blockierend.
- Alternativ: Übertragen Sie schwere Aufgaben an Hintergrundarbeiter und wechseln Sie in einen „Verarbeitung“-Zustand.
2. Endlose Schleifen in Ausgangsaktionen
Eine Ausgangsaktion sollte niemals eine Übergang auslösen, der sofort zurück zum selben Zustand führt. Dies erzeugt eine Schleife, die Ressourcen verbraucht, ohne Fortschritt zu erzielen. 🔄
- Best Practice: Stellen Sie sicher, dass Ausgangsaktionen keine gleiche Zustandsübergang erneut auslösen.
- Alternativ: Verwenden Sie Flags, um die rekursive Auslösung von Aktionen zu verhindern.
📝 Überprüfungsliste für Zustandsdiagramme
Bevor Sie eine Zustandsmaschine bereitstellen, durchlaufen Sie diese Liste. Sie deckt die kritischen Bereiche ab, in denen Deadlocks typischerweise versteckt sind. ✅
| Prüfpunkt | Bestanden / Nicht bestanden | Anmerkungen |
|---|---|---|
| Sind alle Zustände vom Anfangszustand aus erreichbar? | ||
| Hat jeder Zustand mindestens einen ausgehenden Übergang? | ||
| Sind alle Wächterbedingungen logisch konsistent (keine Lücken)? | ||
| Gibt es Zeitüberschreitungsmechanismen für wartende Zustände? | ||
| Vermeiden parallele Bereiche direkte Datenabhängigkeiten? | ||
| Gibt es einen globalen Fehlerwiederherstellungszustand? | ||
| Haben Eingangsaktionen auf blockierendes Verhalten getestet? |
🔍 Tiefgang: Randfälle
Selbst bei gutem Design können Randfälle durchschlüpfen. Hier sind spezifische Szenarien, in denen sich Deadlocks oft in Produktionsumgebungen zeigen. 🌐
1. Die Rennbedingungs-Falle
Wenn zwei Ereignisse gleichzeitig eintreten, ist die Reihenfolge der Verarbeitung entscheidend. Wenn der Zustandsautomat Ereignis A vor Ereignis B verarbeitet, könnte er einen Pfad einschlagen, der zu einem Deadlock führt. Wenn er B vor A verarbeitet, könnte es gelingen. ⚡
- Minderung:Stellen Sie Ereignisse in eine Warteschlange und verarbeiten Sie sie sequenziell. Stellen Sie sicher, dass die Reihenfolge der Ereignisse die Gültigkeit des Endzustands nicht beeinflusst.
2. Die Ressourcen-Erschöpfungs-Falle
Ein Zustand könnte auf eine Ressource warten (z. B. eine Datenbankverbindung). Wenn der Pool erschöpft ist, dauert die Wartezeit unendlich. Das sieht aus wie ein Deadlock, ist aber tatsächlich ein Ressourcenproblem. 💾
- Minderung:Implementieren Sie Verbindungs-Zeitüberschreitungen und Fallback-Zustände, die die Funktionalität sanft herabsetzen.
3. Die Konfigurations-Abweichungs-Falle
Das Diagramm könnte für Zustand A entworfen sein, aber die Konfigurationsdatei legt Zustand B fest. Wenn die Übergangslogik auf fehlende Konfigurationswerte angewiesen ist, bleibt das System hängen. 📄
- Minderung:Überprüfen Sie die Konfiguration bei Startzeit anhand des Zustandsdiagramm-Schemas.
🚀 Letzte Überlegungen für eine robuste Gestaltung
Ein Zustandsautomat, der Deadlocks widersteht, erfordert Disziplin. Es erfordert die Vorhersage von Ausfallzuständen und die Gestaltung von Umwegen darum herum. Durch die Fokussierung auf klare Übergänge, umfassende Schutzlogik und robuste Fehlerbehandlung schaffen Sie Systeme, die sich an Veränderungen anpassen können. 🛡️
Denken Sie daran, dass Zustandsdiagramme lebende Dokumente sind. Wenn sich die Anforderungen ändern, muss das Diagramm sich weiterentwickeln. Regelmäßige Refaktorisierungen und Überprüfungen stellen sicher, dass neue Funktionen keine alten Fehler einführen. Halten Sie das Modell einfach, halten Sie die Logik klar und halten Sie die Wiederherstellungspfade übersichtlich. 🔄
Wenn Sie in der Entwurfsphase Stabilität gegenüber Geschwindigkeit priorisieren, sparen Sie erhebliche Zeit bei der Wartung später. Ein gut entworfener Zustandsautomat ist die Grundlage zuverlässigen Software-Verhaltens. Investieren Sie die Mühe in die Gestaltung, und das System wird konsistent funktionieren. 📈