











В современной архитектуре программного обеспечения интерфейсы программирования приложений (API) выступают в качестве связующего звена между сервисами. Когда эти соединения выходят из строя, вся система может остановиться. Для определения источника снижения производительности требуется не просто мониторинг метрик, а структурное понимание того, как данные проходят через систему. Диаграммы взаимодействия предлагают точный способ визуализации этого потока, позволяя инженерам точно определить, где возникают узкие места.
В этом руководстве рассматриваются механизмы диагностики узких мест API через призму диаграмм взаимодействия. Мы изучим визуальное представление взаимодействий объектов, проанализируем паттерны сообщений, указывающие на перегрузку, и опишем системный подход к устранению проблем с задержками и пропускной способностью без использования проприетарных инструментов.
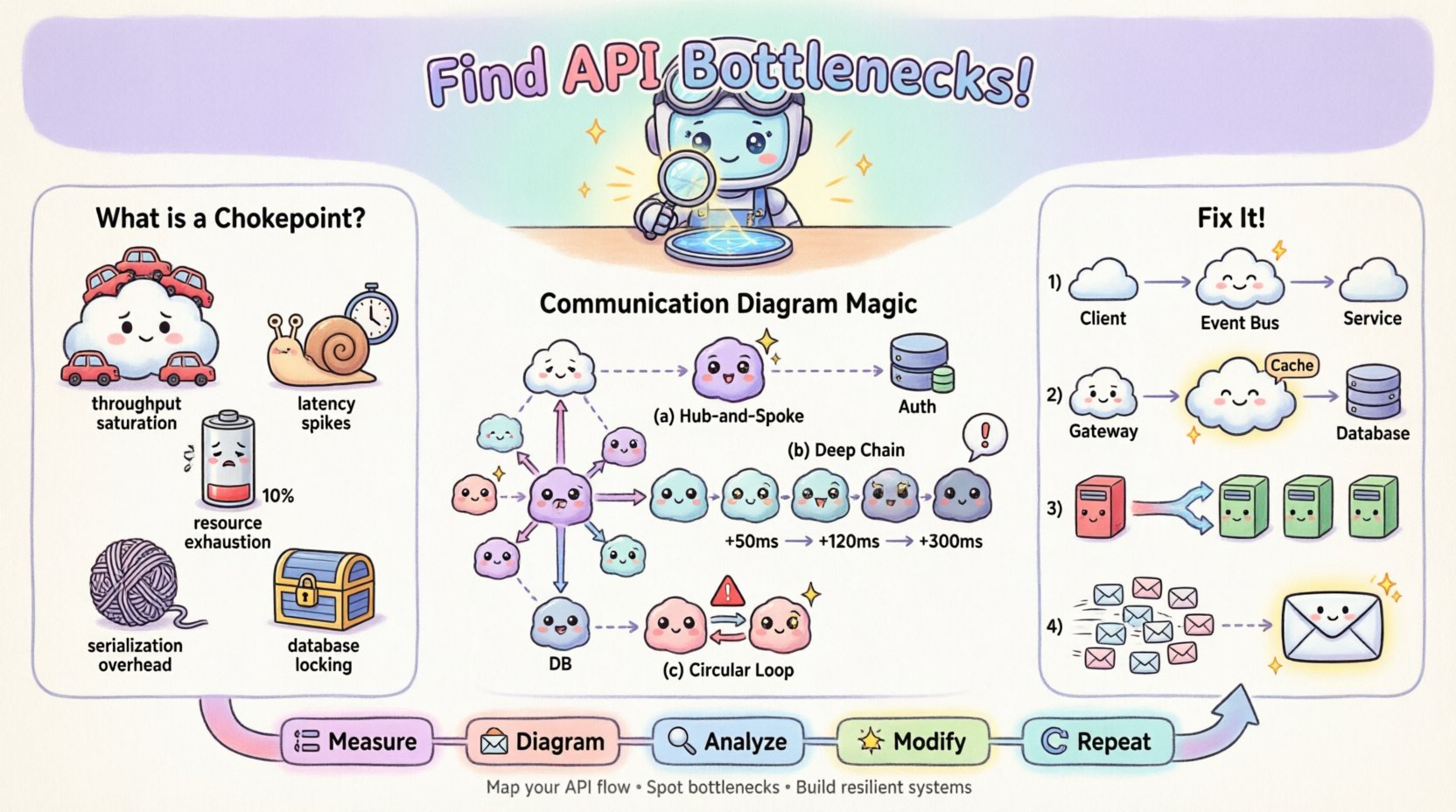
🚦 Понимание узких мест API
Узкое место API — это конкретная точка в цикле запрос-ответ, где обработка замедляется или прерывается, вызывая накопление задержек. В отличие от общей сетевой задержки, которая влияет на всю передачу данных, узкое место часто локализовано в конкретном сервисе, запросе к базе данных или механизме синхронизации. Определение типа узкого места — первый шаг к эффективному устранению проблемы.
Распространенные типы узких мест включают:
- Перегрузка по пропускной способности: Сервис-получатель не может достаточно быстро обрабатывать входящие запросы, что приводит к накоплению в очереди.
- Всплески задержек: Конкретный вызов занимает значительно больше времени, чем среднее, что замедляет последующие процессы.
- Исчерпание ресурсов: Достигнуты пределы использования ЦП, памяти или пула соединений, что вызывает таймауты или ошибки отклонения.
- Накладные расходы сериализации: Затраты на преобразование данных (например, парсинг JSON) становятся чрезмерными из-за размера полезной нагрузки.
- Блокировка базы данных: Параллельные операции записи блокируют чтение или другие операции записи, останавливая поток транзакций.
Когда возникают такие проблемы, они часто проявляются как цепные сбои. Задержка в одном микросервисе может вызвать таймауты в вызывающем сервисе, что, в свою очередь, передается по цепочке. Визуализация этой цепочки имеет критическое значение.
📐 Роль диаграмм взаимодействия при отладке
Диаграммы взаимодействия — это тип диаграмм взаимодействия UML (унифицированный язык моделирования), которые фокусируются на структурной организации объектов и сообщениях, обмениваемых между ними. В отличие от диаграмм последовательности, которые приоритизируют хронологический порядок сообщений, диаграммы взаимодействия акцентируют внимание на отношениях и связях между объектами. Эта структурная направленность делает их особенно эффективными для выявления архитектурных узких мест.
Почему следует использовать именно этот тип диаграмм для устранения неисправностей?
- Фокус на структуре: Она показывает, какие объекты являются центральными узлами. Один объект, получающий сообщения от десяти других, — явный кандидат на роль узкого места.
- Подсчет сообщений: Вы можете визуально подсчитать количество сообщений, обмениваемых в одной транзакции. Высокая разветвленность указывает на возможные проблемы параллельной обработки.
- Анализ пути: Она выделяет самый длинный путь выполнения. Длинные цепочки синхронных вызовов подвержены накоплению задержек.
- Четкость контекста: Она показывает контекст, в котором существуют объекты, помогая определить, перегружен ли сервис из-за своей роли, а не из-за кода.
Преобразовав взаимодействия API в диаграмму взаимодействия, вы превращаете абстрактные логи в осязаемую карту. Эта карта позволяет отслеживать точный путь, по которому проходит запрос, и измерять усилия, затрачиваемые на каждом узле.
🛠️ Построение диагностической диаграммы
Чтобы использовать диаграмму взаимодействия для устранения неполадок, сначала необходимо построить точное представление текущего состояния системы. Этот процесс требует сбора данных из журналов, инструментов трассировки и архитектурной документации. Цель состоит в создании модели, отражающей реальность, а не идеализированный дизайн.
Шаг 1: Определите участников и объекты
Начните с определения внешних клиентов и внутренних служб, участвующих в проблемной транзакции. В контексте API это часто:
- Клиент: Мобильное приложение, веб-браузер или стороннее служба, инициирующая запрос.
- Шлюз: Точка входа, отвечающая за аутентификацию, ограничение скорости и маршрутизацию.
- Оркестратор: Служба, координирующая поток бизнес-логики.
- Зависимости: Базы данных, внешние API, уровни кэширования и фоновые рабочие процессы.
Шаг 2: Сопоставьте потоки сообщений
Нарисуйте соединения между этими объектами. Каждая линия представляет сообщение. Используйте стрелки для указания направления потока данных. Подпишите каждую стрелку именем метода или выполняемым действием (например, GET /orders, processPayment).
Для устранения неполадок крайне важно аннотировать диаграмму данными производительности. Если у вас есть доступ к метрикам времени, добавьте их в подписи сообщений. Например:
- Шлюз ➔ Оркестратор: 50 мс
- Оркестратор ➔ База данных: 450 мс (Предупреждение)
- База данных ➔ Оркестратор: 450 мс
Шаг 3: Определите жизненные циклы взаимодействий
Хотя диаграммы взаимодействия не всегда явно показывают вертикальные жизненные циклы, как диаграммы последовательностей, вы должны мысленно отслеживать продолжительность участия каждого объекта. Объект, который долго остается активным, ожидая ответа, нецелесообразно удерживает ресурсы.
🔎 Выявление узких мест на диаграмме
Как только диаграмма заполнена данными, можно приступать к анализу. Визуальное расположение часто выявляет проблемы, которые скрывают необработанные журналы. Ищите конкретные паттерны, указывающие на узкое место.
Паттерн 1: Звезда с центральным узлом
Если вы видите один объект, подключенный ко многим другим по звездообразной схеме, этот центральный объект, скорее всего, является узким местом. Каждый запрос должен проходить через него. Если этот объект синхронный, он становится точкой последовательной обработки.
| Визуальный индикатор | Последствия | Частая причина |
|---|---|---|
| Один объект с 10+ входящими стрелками | Высокая нагрузка от параллельных запросов | Сервис агрегации |
| Множество длинных горизонтальных стрелок, сходящихся в одной точке | Накопление времени ожидания | Синхронный разветвленный вызов |
| Объект, помеченный высоким использованием CPU % | Перегрузка обработки | Сложная логика |
Шаблон 2: Глубокие цепочки вызовов
Пройдите по самому длинному пути от точки входа до окончательного получения данных. Если путь включает пять или более переходов, задержка будет накапливаться. Каждый переход добавляет сетевую накладную и время обработки.
- Влияние:Общая задержка = Сумма всех задержек переходов + сетевая накладная.
- Решение: Уменьшите глубину цепочки вызовов, размещая данные вместе или используя единый конечный пункт агрегации.
Шаблон 3: Циклические зависимости
Хотя циклические сообщения (A вызывает B, B вызывает A) встречаются реже в хорошо структурированных системах, они могут вызывать взаимоблокировку или бесконечные циклы. В контексте производительности они указывают на неэффективное управление состоянием.
🛠️ Стратегии устранения на основе визуального анализа
Как только узкое место найдено на диаграмме, можно применить конкретные архитектурные изменения. Диаграмма служит чертежом для этих изменений.
1. Отделение синхронных вызовов
Если диаграмма показывает длинную цепочку синхронных вызовов, преобразуйте хвост цепочки в асинхронное событие. Вместо ожидания ответа оркестратор может отправить событие и немедленно вернуться.
- До: Пользователь ➔ API ➔ Сервис A ➔ Сервис B ➔ База данных (Ожидание)
- После: Пользователь ➔ API ➔ Сервис A ➔ Шина событий ➔ Сервис B (Отправить и забыть)
2. Кэширование на границе
Если диаграмма показывает повторяющиеся запросы к одному и тому же объекту для одних и тех же данных, введите слой кэширования. Расположите этот объект между вызывающим и тяжелым ресурсом.
- Изменение диаграммы: Вставьте объект «Кэш» между Шлюзом и Базой данных.
- Обновление метки: Обновите метку сообщения, чтобы отобразить «Попадание в кэш: 1 мс» против «Пропуск кэша: 200 мс».
3. Балансировка нагрузки и шардирование
Если один объект имеет слишком много соединений (паттерн «центр-периферия»), распределите нагрузку. Это может включать шардирование данных или внедрение балансировщика нагрузки для распределения трафика между несколькими экземплярами этого сервиса.
4. Объединение запросов
Если диаграмма показывает несколько небольших сообщений, отправленных в один и тот же объект последовательно, объедините их в один пакетный запрос. Это сокращает накладные расходы на установку соединения и переключение контекста.
📊 Анализ пропускной способности против задержки
Диаграммы взаимодействия также могут помочь различать проблемы с пропускной способностью и задержки. Это различие имеет решающее значение для выбора правильного решения.
- Высокая задержка, низкая пропускная способность: Система медленная, но обрабатывает мало запросов. Это обычно указывает на одну тяжелую операцию (например, сложное формирование отчета).
- Низкая задержка, низкая пропускная способность: Система быстрая, но отклоняет много запросов. Это указывает на ограничения ресурсов (например, исчерпание пула соединений).
- Высокая задержка, высокая пропускная способность: Система медленная и обрабатывает много запросов. Это классическая ситуация узкого места, когда пропускная способность превышена.
Добавив эти метрики на диаграмму, вы сможете визуализировать кривую пропускной способности. Отметьте на диаграмме сценарий «Высокая нагрузка», чтобы увидеть, какой узел сломается первым.
⚠️ Распространённые ошибки при создании диаграмм для отладки
Даже при лучших намерениях создание диаграммы для устранения неполадок может привести к путанице, если не избегать определённых ошибок.
- Чрезмерная абстракция: Не объединяйте слишком много сервисов в одну коробку. Если вы скрываете внутреннюю сложность сервиса, вы не сможете увидеть, где находится внутреннее узкое место. Держите сервисы атомарными.
- Игнорирование асинхронных потоков: Если ваша диаграмма показывает только синхронные запросы, она не отразит реальную нагрузку. Включите фоновые задания и обработчики событий в диаграмму.
- Статическая vs. Динамическая: Статическая диаграмма показывает архитектуру; динамическая диаграмма показывает работу в реальном времени. При устранении неполадок убедитесь, что вы используете данные времени выполнения (фактические пути, пройденные запросами).
- Отсутствующие пути ошибок: Большинство диаграмм показывают путь «счастливого случая». Узкое место часто возникает при обработке ошибок (например, повторные попытки, резервные варианты). Включите циклы повторных попыток в диаграмму.
🔄 Итеративное уточнение диаграммы
Архитектура не является статичной. По мере применения исправлений диаграмма должна эволюционировать. После внедрения слоя кэширования диаграмма изменяется. Сообщение от Шлюза к Базе данных заменяется сообщением к Кэшу.
Этот итеративный процесс создаёт обратную связь:
- Измерьте: Зафиксируйте текущие метрики производительности.
- Диаграмма: Зафиксируйте поток с помощью метрик.
- Анализ: Определите узкое место.
- Измените: Внесите архитектурные изменения.
- Повторите: Перемерьте и обновите диаграмму.
Этот цикл гарантирует, что усилия по оптимизации основаны на данных, а не на догадках.
📈 Интеграция с системами мониторинга
Хотя диаграммы взаимодействия являются визуальными инструментами, они должны основываться на данных из систем мониторинга. Вы должны сопоставить узлы диаграммы с конкретными потоками журналов или идентификаторами телеметрии.
- Идентификаторы трассировки: Убедитесь, что каждое сообщение на диаграмме соответствует уникальному идентификатору трассировки в вашей системе ведения журналов.
- Тепловые карты: Если ваш инструмент мониторинга поддерживает это, визуализируйте частоту вызовов в виде тепловой карты на диаграмме. Более тёплые цвета указывают на более высокий объём трафика.
- Оповещения: Настройте оповещения для конкретных узлов, выявленных как узкие места. Если узел «База данных» резко возрастает, запустите уведомление.
🧠 Кейс-стади: Цепочка обработки заказов
Рассмотрим ситуацию, когда процесс оформления заказа в электронной коммерции медленный. Первоначальный запрос показывает задержку в 5 секунд.
Анализ исходной диаграммы:
- Клиент ➔ Шлюз API (10 мс)
- Шлюз ➔ Сервис заказов (50 мс)
- Сервис заказов ➔ Сервис инвентаря (200 мс)
- Сервис заказов ➔ Сервис оплаты (4000 мс)
- Сервис заказов ➔ Сервис уведомлений (50 мс)
Наблюдение:
Диаграмма показывает, что сервис оплаты — это аномалия. Он потребляет 80% общего времени. Сервис заказов ожидает синхронно завершения сервиса оплаты, прежде чем продолжить работу.
Вмешательство:
1. Перенесите оплату в асинхронный поток. Сервис заказов отправляет запрос и помечает заказ как «В обработке». 2. Фоновый рабочий процесс обрабатывает подтверждение оплаты. 3. Обновите диаграмму, чтобы показать объект «Рабочий оплаты», а не прямой вызов.
Результат:
Пользователь сразу видит статус «В обработке». Общая задержка для пользовательского опыта сокращается с 5 секунд до 50 миллисекунд. Бэкенд выполняет тяжелую работу асинхронно. Диаграмма теперь отражает более устойчивую архитектуру.
🎯 Лучшие практики обслуживания
Чтобы эти диаграммы оставались полезными с течением времени, придерживайтесь следующих практик обслуживания.
- Контроль версий: Храните файлы диаграмм в том же репозитории, что и кодовая база. Когда код изменяется, диаграмма также должна изменяться.
- Циклы обзора: Включите обзор диаграмм в записи решений архитектуры. Убедитесь, что новые службы добавляются на карту до развертывания.
- Стандартизация: Используйте единые обозначения для типов сообщений (например, запрос, ответ, событие), чтобы диаграммы были понятны всем членам команды.
- Документация: Добавьте на диаграмму примечания, объясняющие *почему* существует конкретный путь. Это предотвратит удаление необходимой логики будущими инженерами.
🔗 Заключение
Устранение неисправностей производительности API — это сочетание анализа данных и структурной визуализации. Диаграммы взаимодействия обеспечивают необходимую структуру для понимания сложных взаимодействий. Сопоставляя потоки сообщений, добавляя пояснения к временным данным и анализируя паттерны соединений, вы можете точно выявить узкие места. Этот подход выходит за рамки догадок и позволяет вносить целенаправленные улучшения архитектуры, повышающие стабильность и скорость системы.
Помните, что диаграмма — это живой документ. Она должна развиваться вместе с системой. Регулярный обзор карты гарантирует, что новые функции не создадут новых узких мест. При чётком понимании потоков вы сможете поддерживать здоровую, высокопроизводительную систему.