











情報がシステム内をどのように移動するかを理解することは、システム分析と設計の基盤です。データフローダイアグラム(DFD)は、この移動を視覚的に表現するものです。コードやデータベーススキーマに注目する技術的図面とは異なり、DFDはデータの流れとそのデータを変換するプロセスに焦点を当てます。このガイドでは、これらの図を構築する際に使用される基本的な記号を詳述し、ドキュメントの明確さと正確性を確保します。
データフローダイアグラムとは何か? 🤔
データフローダイアグラムは、構造化分析のためのツールです。情報処理活動の順序をマッピングします。これは、プログラミングコードの観点からシステムの論理を記述するものではありません。代わりに、どのデータが移動され、それがどこから来ているか、どこへ向かっているか、そしてどのように変化するかを示します。この抽象化により、ステークホルダーは技術的な実装の詳細に巻き込まれることなく、機能要件を理解できるようになります。
DFDは階層的です。高レベルの概要から始まり、段階的により詳細なビューに分解されていきます。この分解により、複雑さを管理できます。境界と相互作用を明確にすることで、開発が始まる前に要件の穴や潜在的なボトルネックを特定できるようになります。
4つの基本記号 🛠️
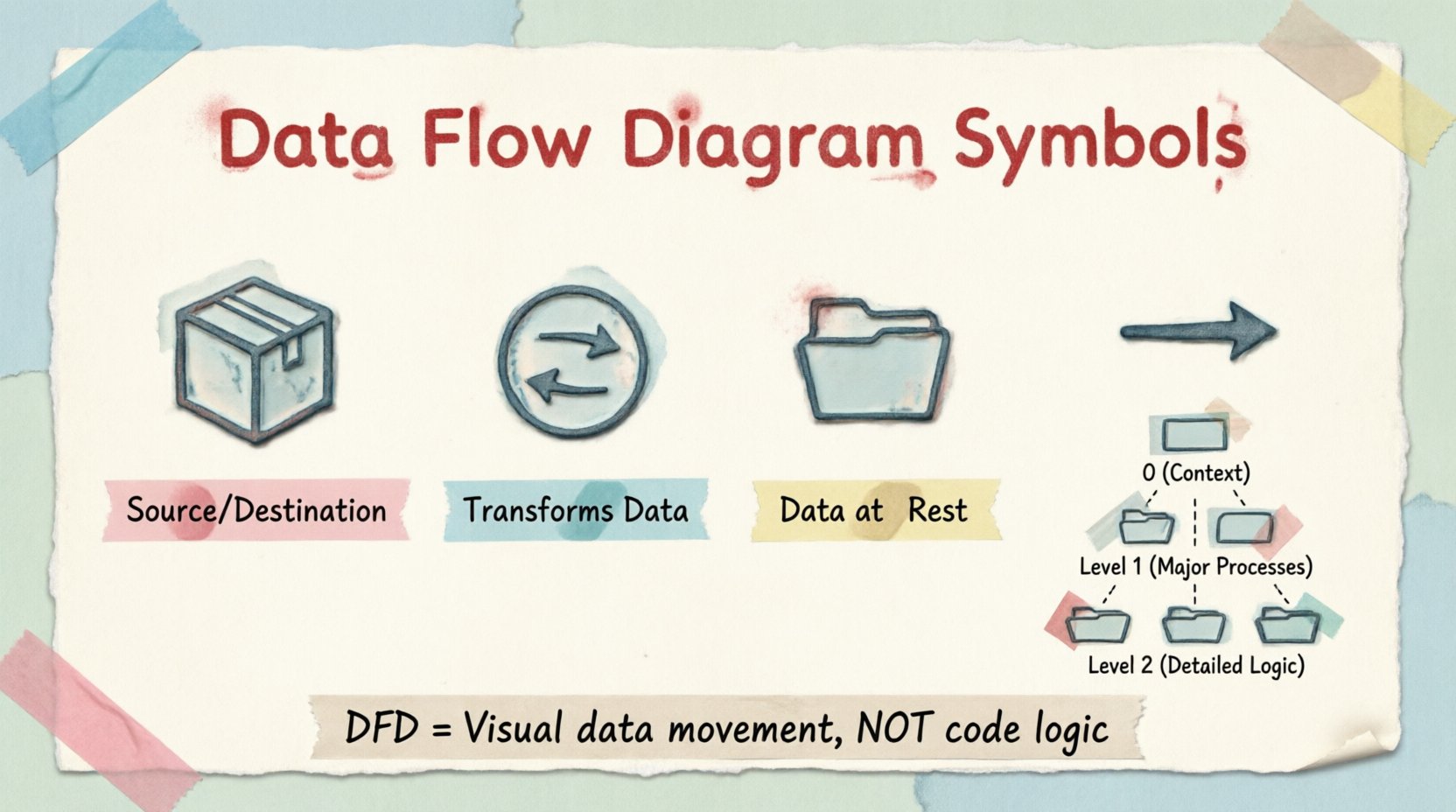
標準的なDFD表記は、4つの主要な形状に依存しています。Yourdon/DeMarcoやGane/Sarsonなどの異なる手法間でバリエーションはありますが、基本的な概念は一貫しています。各記号は、システム境界内の特定の機能を表しています。
| 記号名 | 視覚的表現 | 機能 |
|---|---|---|
| 外部エンティティ | 長方形 | データの発生源または到着先 |
| プロセス | 円または角丸長方形 | データの変換 |
| データストア | 開かれた長方形 | 静止状態のデータの保存 |
| データフロー | 矢印 | データの移動 |
1. 外部エンティティ 📦
外部エンティティは、モデル化されているシステムの外部にあるデータの発生源または到着先を表します。これらはシステムとやり取りするアクターですが、システムの内部論理の一部ではありません。エンティティは人、グループ、別のコンピュータシステム、または部門であることがあります。
エンティティは通常、長方形で描かれます。一部の表記法では楕円として表示されることがあります。重要な特徴は、システムがそれらにデータを送信するか、それらからデータを受け取ることです。たとえば、顧客はエンティティです。システムはその注文を処理しますが、顧客は注文処理ソフトウェアとは独立して存在しています。
- 入力: データがエンティティからシステムに入力される。
- 出力: データがシステムから出力され、エンティティへ向かう。
外部エンティティとプロセスを混同しないことが重要です。エンティティはデータを変換するものではなく、単にデータを発生させたり、消費したりするだけです。
2. プロセス 🔄
プロセスは図のアクティブな要素です。入力データを出力データに変換する機能を表します。プロセスとは、実際に行われている作業です。計算、検証チェック、判断、データ操作ルーチンなどが含まれます。
プロセスは通常、円または角丸長方形で描かれます。形状の内部には、「合計を計算する」や「ログインを検証する」など、その動作を説明する名前を記入します。すべてのプロセスには、少なくとも1つの入力と少なくとも1つの出力が必要です。入力はあっても出力がないプロセスは不完全です。
プロセスは階層を示すために番号が付けられます。たとえば、「プロセス1」は「プロセス1.1」、「プロセス1.2」などに分解されることがあります。この番号付けにより、異なる図間で詳細レベルを追跡しやすくなります。
3. データストア 📁
データストアは、将来の使用のためにデータを保持する場所を表します。それはリポジトリです。物理的なシステムでは、データベーステーブル、ファイル、または物理的なファイルボックスを指すことがあります。論理図では、単にデータが置かれる場所を意味します。
一般的な形状は、開口部のある長方形または平行線です。ストア内の名前は複数形でなければならず、レコードの集合を示すもの、たとえば「顧客ファイル」や「注文ログ」などです。
- 読込: プロセスは、データを活用するためにストアからデータを読み取ります。
- 書込: プロセスは、データを保存するためにストアにデータを書き込みます。
データはストアに入り、ストアから出ます。データフローがプロセスを経由せずに交差することはないという点に注意することが重要です。2つのデータストアの間に直接線を引くことはできません。データが移動する理由を定義するために、プロセスが間に存在しなければなりません。
4. データフロー ➡️
データフローは、記号をつなぐ矢印です。これらはシステム全体を通じたデータの移動を表します。プログラミングにおける制御フローとは異なり、データフローは実際の情報パケットを表します。
各矢印は、その中を移動するデータの名前でラベル付けされるべきです。たとえば、顧客からプロセスへの矢印は「注文要求」とラベル付けされることがあります。プロセスからデータストアへの矢印は「新規注文記録」とラベル付けされることがあります。
矢印は単一の方向を持つ必要があります。2点間でデータが双方向に移動する場合は、2つの別々の矢印を使用してください。ラベルは単数または複数形を一貫して使用してください。「データ」や「情報」といった曖昧なラベルは避け、具体的なもの、たとえば「配送先住所」や「在庫レポート」などを使用してください。
DFDのレベルを理解する 📈
DFDは複雑さを管理するために段階的に作成されます。このアプローチは分解と呼ばれます。
レベル0:コンテキスト図
レベル0の図は最も高いレベルです。システム全体を単一のプロセスとして表示します。システムと外部エンティティの関係を強調します。この視点は、「システムの境界はどこか?」という問いに答えます。
この図では、プロセスノードが1つだけ存在します。すべてのデータフローは外部エンティティをこの中心プロセスに直接接続しています。このレベルでは内部のデータストアは表示されません。内部の動作は隠されているためです。
レベル1:主要プロセス
レベル1の図では、レベル0の単一のプロセスがその主要なサブプロセスに分解されます。これによりシステムが管理可能な部分に分割されます。複数のプロセスノード、データストア、およびそれらをつなぐ具体的なフローが見られます。
このレベルでは主な機能領域が定義されます。たとえば、eコマースシステムは「在庫管理」、「支払い処理」、「配送対応」に分かれます。それぞれが主要なプロセスを表します。
レベル2:詳細な論理
レベル2の図では、レベル1の特定のプロセスをさらに詳細に分析します。レベル1のプロセスが複雑な場合、そのプロセスは独自の図を持ちます。これにより、分析者は全体の視図を乱すことなく、特定の機能のすべてのステップをマッピングできます。
この段階では、記号の使用がより詳細になります。複数のデータストアや複雑なデータフローのルーティングが見られることがあります。ここでは、特定のビジネスルールがしばしば可視化されます。
ルールと規則 ✅
明確さを保つために、DFDは厳格なルールに従わなければなりません。これらのルールを違反すると、混乱や誤解を招くことがあります。
命名の一貫性
同じデータフローは、どこに出現しても同じ名前でなければなりません。ある図でフローを「ユーザーID」とラベル付けした場合、別の図では「ID番号」とはできません。一貫性があることで、レベル間でのデータの追跡が容易になります。
ブラックホールやミラクルは禁止
「ブラックホール」とは、入力はあるが出力がないプロセスを指します。これはデータが消えてしまうことを意味し、通常は誤りです。一方、「ミラクル」とは、出力はあるが入力がないプロセスを指します。これはデータがどこからともなく出現することを意味します。これらはいずれも図における論理的な誤りです。
データストアのバランス
プロセスを分解する際、親プロセスに接続されているデータストアは、子プロセスにも接続されたままにする必要があります。論理が大きく変化しない限り、低レベルでデータストアを削除してはいけません。データの流れは、レベル間でバランスが取れている必要があります。
矢印の方向
矢印は方向を示します。不要な交差を避けて矢印を描いてください。線が交差すると図が読みにくくなります。経路を明確にするために、曲げや中断を使用してください。2つのフローが交差する場合は、データ型が明確に異なることを確認して、混乱を避けてください。
DFDとフローチャートの違い 🧩
データフローダイアグラム(DFD)とフローチャートを混同することはよくあります。見た目は似ていますが、目的は異なります。
フローチャートは、操作の論理と順序を記述します。決定ポイント(ダイアモンド)やループ、ステップの正確な順序を示します。手続き的です。システムがどのように実行されるかを問うものです。
一方、DFDはデータの移動を記述します。ループや決定論理を明示的に示しません。データの「何」が移動し、「どこ」で変換されるかに焦点を当てます。何のデータが移動・変換されるかを問うものです。
制御論理にDFDを使用することは誤りです。決定用のダイアモンドを含んではいけません。論理を示したい場合は、DFDと共に決定表や構造化英語による記述を使用してください。この関心の分離により、図は明確な状態を保ちます。
実践的な応用 📝
図を構築する際は、まずコンテキスト図から始めましょう。システムの境界を特定します。外部エンティティを描きます。システムを表す単一のプロセスを描きます。それらをつなぐフローを描きます。
次に、レベル1に移行します。中心となるプロセスを主要な機能に分割します。データが格納される場所を特定します。すべてのプロセスが入力と出力を持っていることを確認します。フローがコンテキスト図と一致しているか確認します。
ステークホルダーと図を確認します。フローがビジネスの理解と一致しているか尋ねます。ステークホルダーが「そのデータはここでは保存していません」と言う場合は、データストアを調整します。また、「その人物にデータを送信していません」と言う場合は、エンティティを調整します。
検証が重要です。ユーザーが理解できない図は無意味です。図はコミュニケーションツールとして機能します。技術チームとビジネスオーナーの間のギャップを埋めます。
明確性のためのベストプラクティス 🌟
1ページに表示する記号の数を管理可能な範囲に保ちましょう。図が込みすぎると価値を失います。サブ図を用いて分割しましょう。視覚的な容量を超える場合は、1枚の紙に全体のシステムを表示しようとしないでください。
標準的な記法を使用しましょう。バリエーションはありますが、1つのスタイル(例:Yourdon/DeMarcoまたはGane/Sarson)に統一することで混乱を防ぎます。同じ文書内でスタイルを混在させないでください。
すべてにラベルを付けましょう。ラベルのない矢印は意味がありません。ラベルのないプロセスは曖昧です。たとえ単純な形状であっても、意味を伝えるために名前が必要です。
線が交差するのを避けましょう。視覚的なノイズが生じます。線が交差する必要がある場合は、「ジャンプ」や線の断ち切りを使って、交差していないことを示しましょう。
記号の意味の要約 📋
コアとなる構成要素を振り返ります:
- エンティティ:システムの外側。データの発生源または終着点。
- プロセス:システムの内部。データを変換する。
- ストア:システムの内部。データを保持する。
- フロー:上記をつなぐ。データを移動させる。
これらの記号を習得することで、複雑なシステムを明確に文書化できます。アナリストと開発者間の共有言語を提供します。分解のルールと一貫性を守ることで、単なる図ではなく、機能仕様となる図を作成できます。
シンプルから始めましょう。コンテキストを構築します。詳細を拡張します。ユーザーと検証します。この反復的なプロセスにより、図が現実を反映していることを保証できます。