











堅牢な状態機械を設計することは、システムアーキテクチャにおける最も重要なタスクの一つである。正しく実装された場合、状態図は明確性、予測可能性、保守性を提供する。しかし、論理に誤りがあると、システムは進展が不可能な状態に入り込む可能性がある。これをデッドロックと呼ぶ。状態機械図においては、システムが有効な遷移が存在しない状態に到達したときにデッドロックが発生し、実行が無期限に停止する。 ⏸️
このガイドでは、状態機械設計のメカニズムに焦点を当て、特にデッドロックの特定と防止について解説する。遷移ガード、エントリーアクションとエグジットアクション、並行領域、検証戦略について取り上げる。これらの構造化されたアプローチに従うことで、さまざまな条件下でも状態図が耐性を持つことを保証できる。 🔒
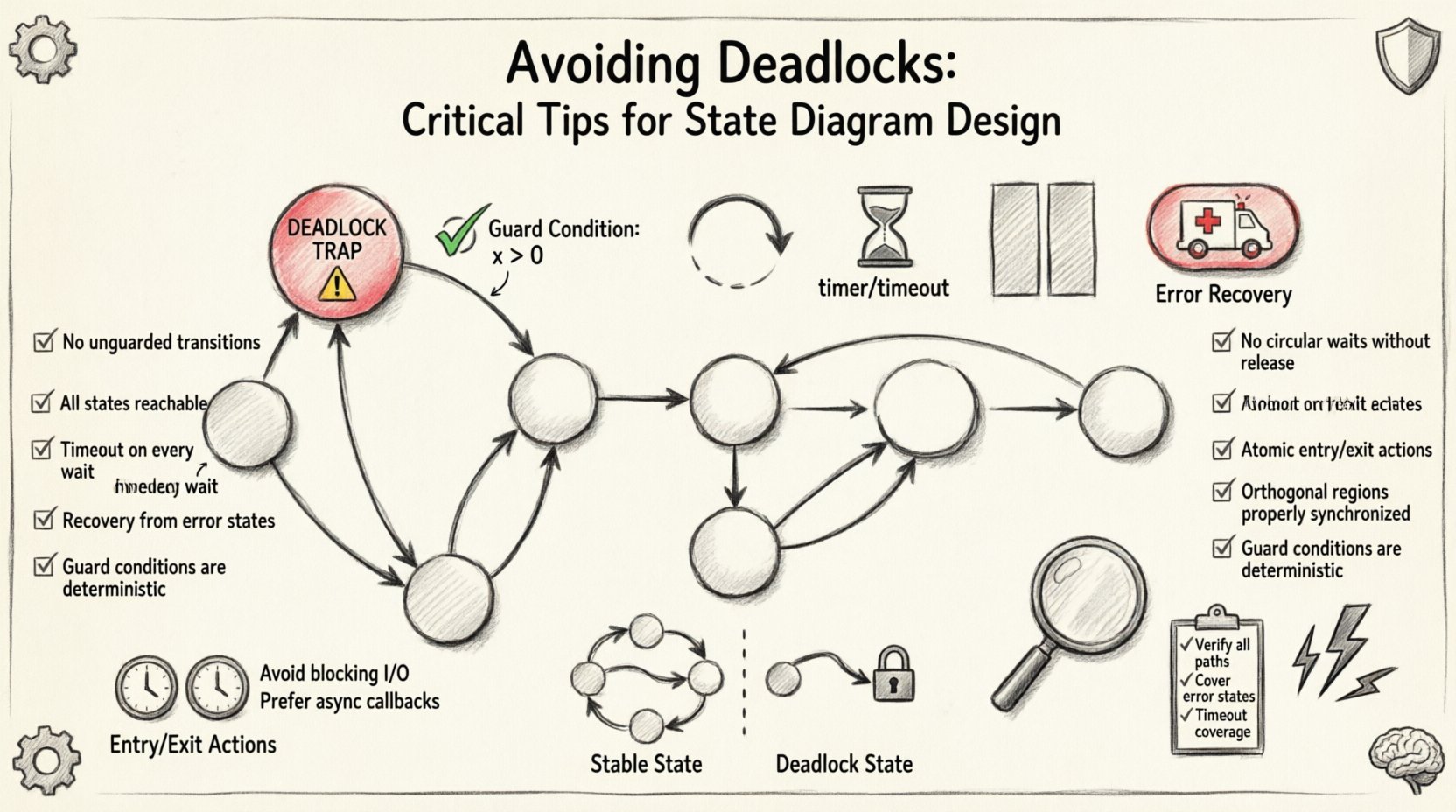
🧠 状態機械のデッドロックを理解する
有限状態機械(FSM)におけるデッドロックは、論理的な停止を意味する。ランタイムエラーがアプリケーションをクラッシュさせるのとは異なり、デッドロックはシステムがまだ実行中であるにもかかわらず、凍結しているように見えることが多い。エンジンは活性化しているが、現在の状態にトリガー条件を満たす出力遷移が存在しないため、何のコマンドも実行できない。 🔍
効果的に設計するためには、デッドロック状況の構造を理解する必要がある。これは単一のコード行が欠けていることによって引き起こされることがほとんどない。むしろ、複数の状態、ガード、外部イベントの複雑な相互作用が原因であることが多い。以下のものが、デッドロック状態の核心的な特徴である:
- 出力遷移がない: その状態からは、出る矢印が存在しない。
- 到達不可能な遷移: すべての出力矢印には、現在のデータでは決して真にならないガード条件が設定されている。
- デフォルトパスの欠如: 意外な入力を処理するためのフォールバック遷移が存在しない。
- リソースの保持: システムはリソース(ロックや接続など)を保持しているが、決して発生しない別の条件を待っている。
これらの状況を防ぐには、反応的なデバッグよりも、予防的な設計哲学が必要である。根本原因を詳しく検討しよう。 📉
⚠️ 状態設計におけるデッドロックの主な原因
デッドロックはランダムな事故ではなく、特定の設計選択の予測可能な結果である。これらのパターンを理解することで、本番環境に影響を与える前に回避できる。状態機械の停止を引き起こす主な原因を以下に示す。
1. 遷移ガードの欠如
遷移を設計する際、状態から出るすべての矢印は、前進する可能性のあるパスを表す。状態に複数の可能な入力(イベント)があるが、そのうち一部しか遷移にマッピングされていない場合、マッピングされていないイベントが発生するとシステムは停止する。これはしばしば「トラップ」状態と呼ばれる。 ❌
- 問題点: 状態機械は特定のトリガーを期待している。予期しないトリガーが到着し、それを処理する遷移が存在しない場合、システムはその場に留まる。
- 解決策: すべての状態が定義されたイベントをすべてカバーするようにする、または、予期しない入力をキャッチするためのグローバルなデフォルトハンドラを実装する。
2. 互いに矛盾するガード条件
ガード条件は、遷移が発火するためには真でなければならないブール式である。2つの遷移が同じ元状態とイベントを共有しているが、そのガード条件が互いに排他的である、またはあり得る状況をカバーしていないという、よくある誤りが発生する。 🧩
- 問題点: 遷移A(スコア > 10の場合)と遷移B(スコア < 5の場合)を定義する。スコアがちょうど10の場合どうなるか?論理が厳密であれば、両方とも失敗する可能性がある。
- 解決策:エッジケースについてガード条件を確認する。特定のイベントに対するすべてのガード条件の和集合が、入力領域全体をカバーしていることを確認する。
3. 円環依存
複雑なシステムでは、状態が他の状態や外部プロセスの状態に依存する場合があります。State AがState Bの終了を待っている一方で、State BがState Aの確認を待っている場合、どちらも進みません。これは古典的な同期デッドロックです。⏳
- 問題点:論理が相互の承認が進展前に必要になるように絡み合っており、進行が阻害されます。
- 解決策:タイムアウトを導入するか、一方のプロセスが他方の即時確認なしに進行できるようにすることで、循環を解除します。
4. 歴史状態の不適切な扱い
履歴状態は、再入時に以前の状態を記憶できるようにします。正しく実装されない場合、履歴状態が無効になったり削除された状態を指すことがあります。🔄
- 問題点:マシンが存在しないかアクセスできない歴史状態に遷移しようとしています。
- 解決策:マシンが再起動またはリセットされたときに、歴史的ターゲットがまだ有効であることを検証します。
🛡️ スタックを防ぐための設計パターン
リスクを理解した後は、特定のパターンを適用してそれらのリスクを軽減できます。これらのパターンはソフトウェアに特化したものではなく、あらゆるモデル言語や実装フレームワークに適用可能です。🛠️
1. デフォルト状態パターン
すべての状態機械には明確なエントリポイントが必要です。これは通常、初期状態です。しかし初期状態を超えて、他のすべての状態は理想的にはデフォルトパスを持つべきです。イベントが特定の条件に一致しない場合、システムは安全なデフォルト動作にフォールバックすべきです。📍
- 実装方法:すべての状態に、未知のイベントを適切に処理する「万能」遷移を作成します。
- 利点:予期しない入力が発生した際に、システムが未定義の状態に入ることを防ぎます。
2. タイムアウトガードパターン
場合によっては、決して到着しない可能性のある外部イベントを待つ必要がある状態があります。無限に待つのを防ぐためにタイマーを導入できます。指定された期間内にイベントが到着しなければ、タイムアウト遷移が発動します。⏱️
- 実装方法:時間に基づくイベント(例:「タイマー期限切れ」)によってトリガーされる遷移を追加します。
- 利点:主な条件が満たされなくても、システムが常に前進することを保証します。
3. 並列状態パターン
複雑なワークフローでは、1つの状態ではすべての並行アクティビティを捉えることはできません。直交領域を使うことで、状態を複数の独立した部分状態に分割できます。これにより、遷移ガードの複雑さが軽減されます。⚡
- 実装方法:複合状態を用い、同時に実行される複数の領域を使用します。
- 利点: 要件を分離することで論理を簡素化する。一方の領域でデッドロックが発生しても、もう一方は依然として動作可能であるか、エラーを報告できる。
4. エラー回復状態
エラー処理専用の状態を設計する。システムが異常を検出すると、直ちにこの状態に遷移する。ここからリセットの試行、再試行、またはオペレーターへの警告が可能になる。 🚑
- 実装: 複数のポイントからアクセス可能な専用の「エラー」または「回復」状態を追加する。
- 利点: 故障を隔離し、システムを破損した状態に放置するのではなく、明確な回復経路を提供する。
📊 比較:デッドロック vs. 安定状態
健全な状態とデッドロックの違いを可視化するため、以下の比較表を検討する。これにより設計上の構造的違いが明確になる。
| 機能 | 安定状態 | デッドロック状態 |
|---|---|---|
| 遷移 | 少なくとも1つの有効な出力遷移が存在する。 | 現在の条件を満たす出力遷移が存在しない。 |
| ガード論理 | ガードがすべての関連する入力シナリオをカバーしている。 | ガードが互いに排他的であるか、不完全である。 |
| イベント処理 | イベントが予期された動作を引き起こす。 | イベントが無視されるか、停止を引き起こす。 |
| 回復 | システムが自己修正するか、次のフェーズに進む。 | システムは再起動のために外部の介入を必要とする。 |
🧪 検証とテスト戦略
設計は戦いの半分に過ぎない。ストレス下でも耐えうるかを確認するために、図を検証する必要がある。ステートマシンのテストは、標準的な関数のテストとは異なるアプローチを要する。 🧪
1. モデル検証
モデル検証は形式的検証手法の一つである。数学的にステートマシンが特定の性質を満たすことを証明するもので、たとえば「デッドロックが存在する状態に到達可能である」ことはない、といった性質を含む。これはクリティカルなシステムにおいて非常に効果的である。 🔢
- 手法: 形式的な手法のツールを用いて、すべてのステート空間を探索する。
- 結果:システムがデッドロック状態に入ることのない数学的な保証。
2. 状態カバレッジテスト
すべての状態とすべての遷移が少なくとも1回はテストされることを確認する。これを状態カバレッジと呼ぶ。状態がテストされていない場合、その状態に隠れたデッドロック条件が含まれているかどうかは分からない。 🎯
- 技法:システムをすべての定義された状態に強制するテストケースを書く。
- 結果:すべてのエントリポイントから遷移が正しく発火することの検証。
3. 入力のストレステスト
無効な、null、または予期しない入力をシステムに送信する。堅牢な状態機械は、悪意のあるデータを受け取ってもクラッシュしたり、停止したりしてはならない。入力を拒否するか、安全な状態に遷移すべきである。 🌪️
- 技法:ランダムまたは境界値の入力を生成し、挙動を観察する。
- 結果:デッドロックを引き起こすエッジケースの特定。
4. 静的解析
コードを実行する前に、図の構造を解析する。出力矢印のない状態がないか確認する。終了しないループがないか確認する。ツールはこれらのパターンを自動的に検出できることが多い。 🔎
- 技法:状態定義ファイルに対してlintingまたは静的解析スクリプトを実行する。
- 結果:構造的なエラーの早期発見。
🔄 同時実行と並列状態の扱い
同時実行は複雑性を加える。複数の領域が同時に動作する場合、同期の問題からデッドロックが発生する可能性がある。並列パスが互いにブロックしないことを確認しなければならない。 🏗️
1. 独立した領域
並列状態が本当に独立していることを確認する。Region 1 の状態AがRegion 2 の状態Bからのデータを必要とする場合、依存関係が生じる。この依存関係はボトルネックになる可能性がある。 🚧
- ベストプラクティス:直交する領域間でのデータ共有を最小限に抑える。
- 代替案:直接的なブロッキングなしに領域間で通信するために、イベントバスを使用する。
2. 同期ポイント
場合によっては、状態間の同期が必要になる。たとえば、Region Aが終了してからRegion Bが開始しなければならない。これを手動で実装すると、デッドロックのリスクがある。フレームワークが提供する組み込みの同期構造を使用する。 ⚙️
- ベストプラクティス:絶対に必要でない限り、手動のロックメカニズムを避ける。
- 代替案:すべての入力パスが自然に完了するのを待つジョインステートを使用する。
⚙️ エントリーアクションとエグジットアクション
エントリーアクションとエグジットアクションは、状態に入ったり出たりするときに実行されるコードスニペットです。これらは微細なデッドロックのよくある原因です。⚠️
1. ブロッキングエントリーアクション
エントリーアクションがタイムアウトなしで長時間実行されるタスク(ネットワークリクエストなど)を実行すると、タスクが完了するまでその状態から脱出できなくなる。タスクがフリーズすると、状態機械もフリーズする。🕸️
- ベストプラクティス:エントリーアクションは軽量でブロッキングしないようにする。
- 代替案:重いタスクをバックグラウンドワーカーに任せて、「処理中」状態に遷移する。
2. エグジットアクション内の無限ループ
エグジットアクションは、直ちに同じ状態に戻る遷移を発生させてはならない。これにより、進展のないリソース消費が続くループが発生する。🔄
- ベストプラクティス:エグジットアクションが同じ状態遷移を再発動しないことを確認する。
- 代替案:フラグを使用して、アクションの再帰的発動を防ぐ。
📝 状態図のレビュー確認リスト
状態機械をデプロイする前に、このチェックリストを確認する。デッドロックが通常隠れている重要な領域を網羅している。✅
| チェック項目 | 合格/不合格 | メモ |
|---|---|---|
| 初期状態からすべての状態に到達可能か? | ||
| すべての状態に少なくとも1つの出力遷移があるか? | ||
| すべてのガード条件は論理的に整合しているか(隙間がないか)? | ||
| 待機状態にはタイムアウトメカニズムがあるか? | ||
| 並列領域は直接的なデータ依存を避けてるか? | ||
| グローバルなエラーリカバリ状態があるか? | ||
| エントリーアクションはブロッキング動作についてテストされたか? |
🔍 深入調査:エッジケースのシナリオ
良い設計をしても、エッジケースは見逃されてしまうことがあります。ここでは、本番環境でデッドロックが頻繁に発生する具体的なシナリオを紹介します。 🌐
1. レースコンディションの罠
2つのイベントが同時に発生した場合、処理順序が重要になります。ステートマシンがイベントAをイベントBより先に処理すると、デッドロックを引き起こすパスを取る可能性があります。逆にBをAより先に処理すれば、成功するかもしれません。 ⚡
- 緩和策:イベントをキューに格納し、順次処理する。イベントの順序が最終的なステートの正当性に影響しないことを確認する。
2. リソース枯渇の罠
ステートがリソース(データベース接続など)を待つ場合があります。プールが枯渇すると、待機は無限に続きます。これはデッドロックのように見えますが、実際はリソースの問題です。 💾
- 緩和策:接続タイムアウトを実装し、機能を段階的に低下させるフォールバックステートを設ける。
3. 設定のずれの罠
図はステートAを想定して設計されているが、設定ファイルではステートBが指定されている場合があります。遷移ロジックが欠落している設定値に依存していると、システムは停止します。 📄
- 緩和策:起動時に設定をステート図のスキーマと照合して検証する。
🚀 ロバストな設計のための最終的な考慮事項
デッドロックに強いステートマシンを構築することは、規律の問題です。失敗モードを予測し、それらを回避するための経路を設計する必要があります。明確な遷移、包括的なガードロジック、強固なエラー処理に注力することで、変化に強いシステムを構築できます。 🛡️
ステート図は動的な文書であることを忘れないでください。要件が変化するたびに、図も進化しなければなりません。定期的なリファクタリングとレビューにより、新機能が古いバグを引き起こさないことを保証できます。モデルはシンプルに、ロジックは明確に、回復経路は明確に保ちましょう。 🔄
設計段階でスピードよりも安定性を優先すれば、後での保守に大きな時間の節約ができます。適切に設計されたステートマシンは、信頼性の高いソフトウェア動作の基盤です。設計に努力を注ぎ、システムは一貫した動作を実現します。 📈