










Construir sistemas de software robustos requiere más que simplemente escribir código funcional. Requiere un enfoque estructurado para gestionar el ciclo de vida de los datos y los procesos. Una máquina de estados es una herramienta fundamental para esto, proporcionando un mapa claro de cómo un sistema pasa de un estado a otro. Cuando se integran diagramas de estados con almacenamiento persistente y servicios externos, la complejidad aumenta significativamente. Esta guía explora los patrones técnicos necesarios para conectar la lógica de estados con operaciones de base de datos e interacciones de API de manera efectiva.
Las máquinas de estados no son meras construcciones teóricas; son implementaciones prácticas que determinan el flujo de datos. Ya sea gestionando el procesamiento de pedidos, la incorporación de usuarios o la automatización de flujos de trabajo, la integridad del estado es fundamental. Integrar esta lógica con bases de datos garantiza que los cambios de estado sean duraderos. Conectarse con APIs permite al sistema reaccionar a desencadenantes externos. Este documento detalla las consideraciones arquitectónicas, los patrones de implementación y las estrategias de mitigación de riesgos para esta integración.
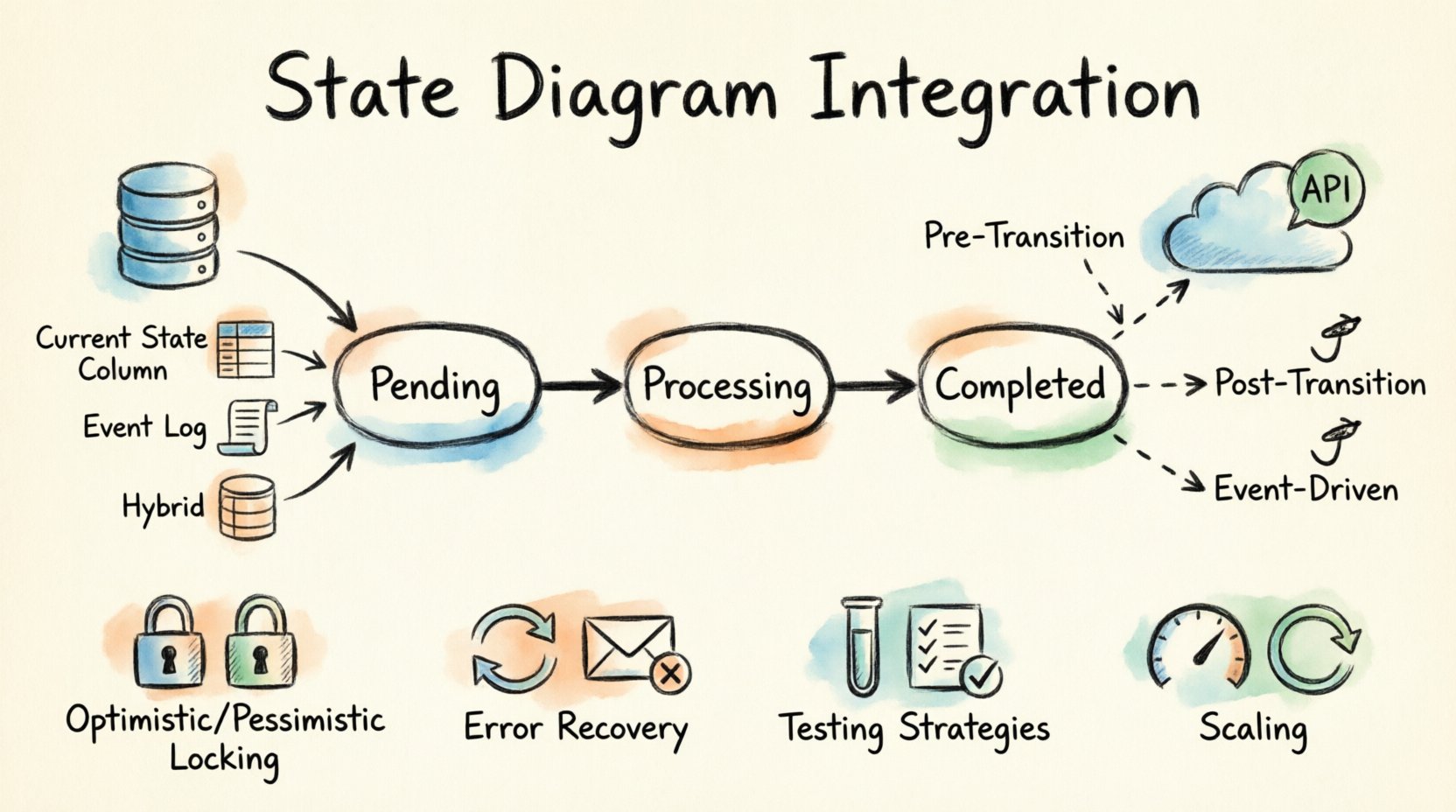
Comprendiendo la arquitectura principal 🧩
Antes de adentrarnos en la persistencia y la lógica de red, es esencial definir los componentes involucrados. Una máquina de estados consta de tres elementos principales: estados, transiciones y eventos. Comprender cómo estos interactúan con sistemas externos forma la base de la integración.
- Estados: Representan el estado de la entidad en un momento específico. Ejemplos incluyen Pendiente, Procesando, o Completado.
- Transiciones: El movimiento de un estado a otro desencadenado por un evento. Aquí es donde se aplica la lógica.
- Eventos: Señales que desencadenan una transición. Pueden provenir de acciones internas del sistema o de llamadas a API externas.
Al integrar, el estado debe ser visible para la base de datos, y las transiciones deben ser capaces de invocar llamadas a API. Esto crea una cadena de dependencias donde la base de datos almacena la verdad, y la API maneja los efectos secundarios.
Estrategias de persistencia de base de datos 🗄️
La persistencia es el proceso de almacenar el estado actual para que sobreviva a un reinicio del sistema o a un fallo. Cómo almacenas el estado afecta el rendimiento, la consistencia y las capacidades de recuperación. Existen varios patrones para mapear los nodos del diagrama de estados a filas de la base de datos.
Almacenamiento del estado actual
El enfoque más común implica almacenar el identificador del estado actual en una columna dedicada dentro de la tabla principal de registros. Esto permite una recuperación rápida sin escanear registros.
- Implementación: Agrega una
estadoocódigo_estadocolumna en la tabla principal de la entidad. - Beneficio: Alto rendimiento de lectura para verificar el estado actual.
- Riesgo:Si la lógica del estado es compleja, una sola columna puede no capturar todo el contexto necesario.
Almacenamiento de registro de eventos
En algunas arquitecturas, el estado actual no se almacena directamente. En su lugar, la secuencia de eventos se almacena en un registro. El estado actual se deriva mediante la reproducción de los eventos.
- Implementación:Agregue un evento a una tabla cada vez que ocurre una transición.
- Beneficio:Rastro completo de auditoría y la capacidad de reconstruir la historia.
- Riesgo:Calcular el estado actual requiere procesar todo el registro, lo que puede ser más lento.
Comparación de modelos de almacenamiento
| Modelo | Rendimiento de lectura | Complejidad de escritura | Capacidad de auditoría |
|---|---|---|---|
| Columna de estado actual | Alto | Bajo | Bajo |
| Registro de eventos | Medio (requiere reproducción) | Medio | Alto |
| Híbrido | Alto | Medio | Medio |
El modelo híbrido suele ser el preferido. Almacena el estado actual para un acceso rápido, mientras mantiene un registro de eventos para auditoría. Esto garantiza que el sistema sepa dónde está ahora, pero también sabe cómo llegó hasta allí.
Restricciones y integridad de la base de datos
Asegurar la integridad de los datos es fundamental. La base de datos debe imponer reglas que eviten transiciones de estado inválidas. Aunque la lógica de la aplicación es el principal controlador, las restricciones de la base de datos proporcionan una red de seguridad.
- Restricciones de verificación:Defina valores válidos para la columna de estado.
- Claves foráneas:Vincule los registros de estado con la entidad principal para garantizar la integridad referencial.
- Transacciones:Envuelva las actualizaciones de estado y los cambios de datos relacionados en una sola transacción para garantizar la atomicidad.
Integración de API y lógica externa 🔗
Los cambios de estado a menudo requieren una acción. Cuando un sistema pasa de Pendiente a Procesamiento, podría necesitar enviar una notificación, cobrar un pago o actualizar un sistema de inventario. Estas acciones se gestionan mediante API.
Activación de llamadas externas
Las llamadas a la API deben activarse según la lógica de transición. Esto garantiza que los efectos secundarios solo ocurran cuando el cambio de estado sea válido.
- Ganchos previos a la transición:Valide las condiciones externas antes de permitir el cambio de estado.
- Ganchos posteriores a la transición:Ejecute la lógica después de que el estado se haya confirmado correctamente.
- Ganchos basados en eventos:Escuche los eventos de cambio de estado y reaccione de forma asíncrona.
Manejo de fallas de API
Las llamadas de red son poco confiables. Si una llamada a la API falla durante una transición de estado, el sistema debe decidir cómo proceder. Dejar el estado en una posición ambigua puede causar corrupción de datos.
- Transacciones compensatorias: Si una acción falla, active un retroceso o un estado específico para marcar el fallo (por ejemplo, Fallido o Reintentar).
- Lógica de reintentos:Implemente un retroceso exponencial para errores transitorios.
- Idempotencia: Asegúrese de que volver a intentar una llamada a la API no cree registros duplicados ni cargos.
Patrones de solicitud
| Patrón | Casos de uso | Complejidad |
|---|---|---|
| Síncrono | Se requiere retroalimentación inmediata | Bajo |
| Asíncrono | Tareas de larga duración | Medio |
| Disparar y olvidar | Notificaciones | Bajo |
Las llamadas síncronas bloquean la transición de estado hasta que la API responde. Esto es simple, pero puede provocar tiempos de espera. Las llamadas asíncronas permiten que el estado se actualice de inmediato, con un trabajador que procesará la solicitud externa más adelante. Esto desacopla la lógica del estado de la latencia de la dependencia externa.
Concurrencia y condiciones de carrera 🔄
Cuando múltiples procesos intentan cambiar el estado de la misma entidad simultáneamente, pueden ocurrir condiciones de carrera. Esto es común en sistemas distribuidos donde las solicitudes llegan a través de diferentes puntos finales de API.
Bloqueo optimista
El bloqueo optimista asume que los conflictos son raros. Utiliza un número de versión o marca de tiempo para detectar cambios.
- Lógica: Lea la versión actual. Actualice el registro con el nuevo estado y la versión incrementada.
- Conflicto: Si la actualización afecta cero filas, otro proceso modificó el registro. La transacción se revierte.
- Beneficio: Alto rendimiento para sistemas con baja contención.
Bloqueo pesimista
El bloqueo pesimista asume que los conflictos son probables. Bloquea el registro antes de leerlo.
- Lógica: Adquiera un bloqueo exclusivo en la fila. Realice la actualización. Suelte el bloqueo.
- Conflicto:Otros procesos esperan hasta que se libere el bloqueo.
- Beneficio:Garantiza el orden de las operaciones.
- Riesgo:Puede provocar interbloqueos si no se gestiona con cuidado.
Gestión de estado basada en colas
Para evitar por completo los problemas de concurrencia, enruta todas las solicitudes de cambio de estado a través de una sola cola.
- Implementación:Todas las solicitudes de la API envían un evento a una cola de mensajes.
- Procesamiento:Un único trabajador procesa eventos de forma secuencial para un ID de entidad específico.
- Beneficio:Elimina las condiciones de carrera por diseño.
Manejo de errores y recuperación 🛡️
Los errores son inevitables. La capa de integración debe manejarlos sin dejar la máquina de estados en un estado roto.
Límites de transacción
Define dónde comienza y termina la transacción. Un error común es confirmar el estado de la base de datos antes de que la llamada a la API tenga éxito. Esto deja al sistema en un estado en el que la base de datos diceCompletado, pero el servicio externo nunca recibió la solicitud.
- Compromiso de dos fases:Asegúrate de que tanto la base de datos como el servicio externo estén de acuerdo con el resultado.
- Consistencia eventual:Acepta que la consistencia puede retrasarse, pero asegúrate de tener un mecanismo para corregirla.
Colas de cartas muertas
Si una llamada a la API falla repetidamente, mueve el evento a una cola de cartas muertas. Esto evita que el sistema gire indefinidamente en un bucle de reintento.
- Alertas:Notifica a los ingenieros cuando los elementos ingresan a la cola de cartas muertas.
- Intervención manual:Permite a los operadores volver a intentar o descartar eventos fallidos.
Pruebas y validación 🧪
Probar máquinas de estado es complejo porque el número de caminos posibles crece exponencialmente. Una estrategia de pruebas sólida cubre la lógica, los puntos de integración y los escenarios de fallo.
Pruebas unitarias de la lógica de estado
Pruebe la máquina de estado de forma aislada de la base de datos y la API.
- Entrada/Salida:Introduzca un evento y verifique el estado resultante.
- Transiciones inválidas:Asegúrese de que los eventos inválidos sean rechazados.
- Cobertura de código:Busque una cobertura del 100 % de las reglas de transición de estado.
Pruebas de integración
Pruebe el flujo con mocks de base de datos y API.
- Esquema de la base de datos:Verifique que las actualizaciones de estado coincidan con el esquema.
- Mocks de API:Simule respuestas de API (éxito, fallo, tiempo de espera) para probar el manejo de errores.
- De extremo a extremo:Ejecute todo el flujo desde el inicio hasta el final en un entorno de pruebas.
Pruebas de mutación
Romper intencionalmente el código para ver si las pruebas detectan el error.
- Cambios en la lógica:Elimine una transición de estado y verifique que la prueba falle.
- Cambios en los datos:Modifique el estado de la base de datos y verifique que el sistema lo rechace.
Escalabilidad y rendimiento 🚀
A medida que el sistema crece, la máquina de estado debe manejar una carga mayor sin degradar el rendimiento.
Cachear el estado
Leer el estado de la base de datos en cada solicitud puede ser lento. Las cachés en memoria pueden reducir la latencia.
- Estrategia:Cachee el estado actual para un ID de entidad específico.
- Invalidación: Asegúrese de invalidar la caché inmediatamente después de un cambio de estado.
- Consistencia: Acepte inconsistencias temporales si la tasa de aciertos de la caché es alta.
Fragmentación de bases de datos
Si el número de entidades es grande, divida la base de datos en múltiples fragmentos según el ID de la entidad.
- Beneficio: Distribuye la carga entre múltiples servidores.
- Desafío: Las consultas complejas que abarcan fragmentos se vuelven difíciles.
Mantenimiento y versionado 📝
Las máquinas de estado evolucionan. Se agregan nuevos estados y los antiguos se deprecian. Gestionar esta evolución es crucial para la estabilidad a largo plazo.
Versionado de la lógica del estado
Almacene la versión de la lógica de la máquina de estado junto con los datos del estado.
- Compatibilidad: Asegúrese de que los datos antiguos puedan ser leídos por las nuevas versiones.
- Migración: Escriba scripts para actualizar los registros existentes al nuevo esquema.
Estrategia de desuso
Cuando elimine un estado, no lo elimine de inmediato.
- Marcar como obsoleto: Agregue una bandera para indicar que el estado es obsoleto.
- Bloquear transiciones: Evite nuevas transiciones hacia el estado obsoleto.
- Limpieza: Elimine la definición del estado solo después de que todos los datos se hayan migrado.
Documentación
Mantenga un diagrama visual que coincida con el código. Esto ayuda a los nuevos desarrolladores a entender el sistema.
- Herramientas de diagramas: Utilice herramientas que puedan generar diagramas a partir de código o configuración.
- Registros de cambios:Documente cada cambio en el diagrama de estados en el historial de versiones.
Consideraciones de seguridad 🔐
Las transiciones de estado implican con frecuencia datos sensibles. La seguridad debe integrarse en la capa de integración.
- Autorización:Verifique que el usuario que solicita el cambio de estado tenga permiso para esa transición específica.
- Validación de datos:Limpie todos los datos de entrada antes de procesar el cambio de estado.
- Registro:Registre los cambios de estado para auditoría de seguridad, pero asegúrese de que los datos sensibles estén enmascarados.
Resumen de las mejores prácticas
- Almacene el estado actual en la base de datos para un acceso rápido.
- Registre todos los eventos para auditoría y reconstrucción.
- Utilice transacciones para garantizar la atomicidad entre las actualizaciones de estado y las llamadas a la API.
- Implemente lógica de reintento con retroceso exponencial para fallas de la API.
- Utilice bloqueo optimista para manejar actualizaciones concurrentes de forma eficiente.
- Pruebe todas las transiciones de estado, incluyendo las inválidas.
- Versione su lógica de estado para gestionar su evolución con el tiempo.
Siguiendo estos patrones, los desarrolladores pueden crear máquinas de estado resilientes, escalables y mantenibles. La integración entre la lógica de estado, las bases de datos y las API es la columna vertebral de los procesos empresariales confiables. Un diseño adecuado a este nivel previene la corrupción de datos y garantiza que el sistema se comporte de forma predecible bajo carga.