











En el panorama de los sistemas distribuidos modernos, la complejidad no es un error; es una característica de la escala. A medida que las organizaciones crecen, las arquitecturas monolíticas se fragmentan en microservicios. Este cambio ofrece agilidad y resiliencia, pero introduce un desafío importante: comprender cómo estas unidades independientes se comunican entre sí. Sin un mapa claro de los flujos de comunicación, los equipos navegan por un laberinto de dependencias, lo que conduce a ciclos lentos de depuración, efectos secundarios no deseados y despliegues frágiles.
Esta guía explora un enfoque práctico para mapear comunicaciones complejas entre microservicios. Avanzaremos más allá de la teoría abstracta para examinar la mecánica de la interacción entre servicios, los métodos para documentar estas relaciones y las estrategias para mantener la claridad mientras el sistema evoluciona. El objetivo no es crear un documento estático, sino establecer una comprensión dinámica de su arquitectura distribuida.
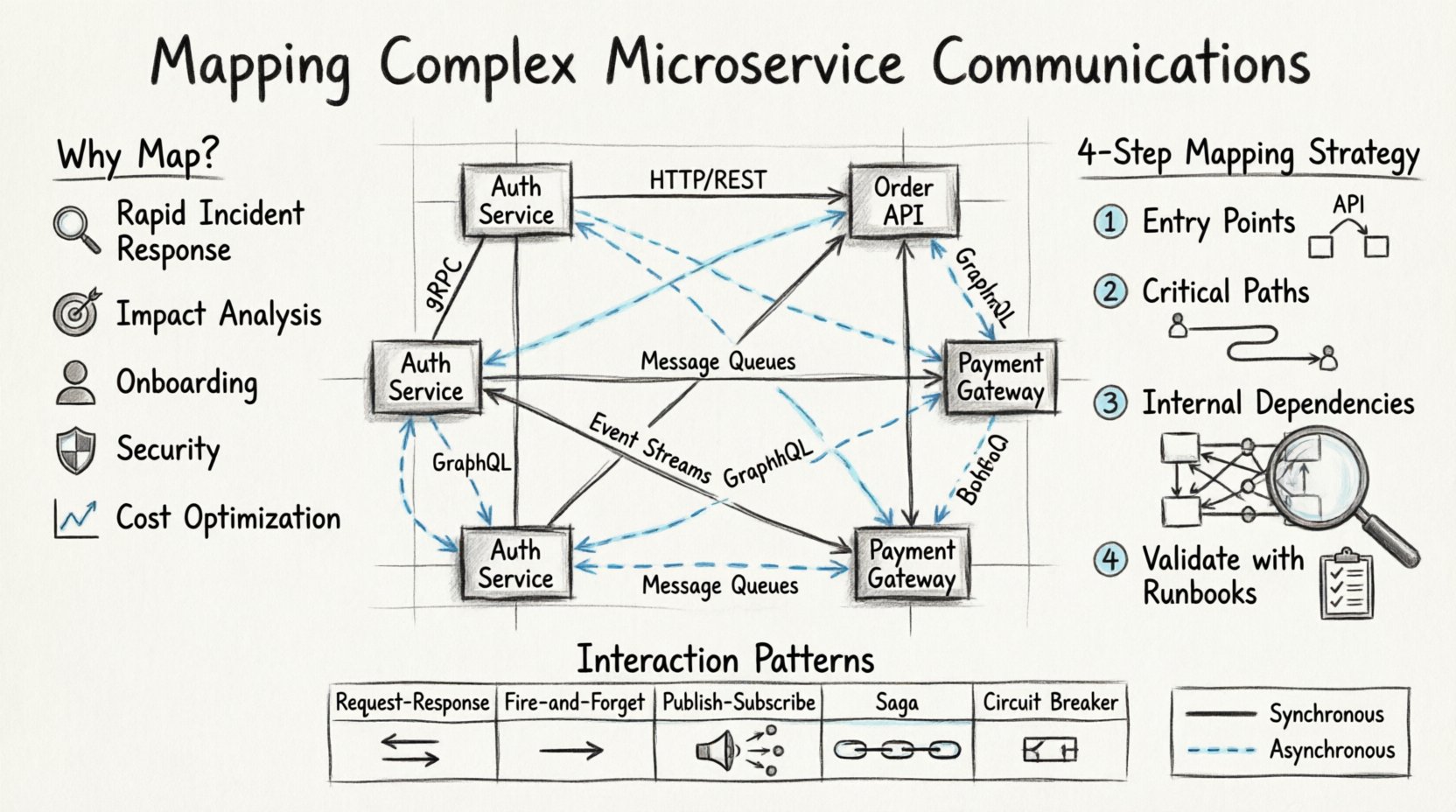
¿Por qué la visibilidad importa en los sistemas distribuidos 🧠
Cuando un sistema consta de decenas o cientos de servicios, el número de rutas de interacción potenciales crece exponencialmente. Una sola solicitud de un cliente puede atravesar cinco servicios diferentes, activar dos trabajos en segundo plano y actualizar tres bases de datos antes de que se devuelva una respuesta. Sin una representación visual o documentada de esta ruta, los ingenieros dependen de conocimientos fragmentados.
Estos son los motivos fundamentales por los que mapear la comunicación es esencial:
- Respuesta rápida ante incidentes:Cuando hay picos de latencia o se producen errores, conocer el flujo exacto de los datos permite a los ingenieros aislar rápidamente el punto de fallo.
- Análisis de impacto:Antes de desplegar un cambio en un servicio específico, debe saber qué otros servicios dependen del contrato actual de su API.
- Eficiencia en la incorporación:Los nuevos miembros del equipo pueden comprender la arquitectura del sistema sin necesidad de rastrear el código a través de cada repositorio.
- Cumplimiento de seguridad:Comprender el flujo de datos es fundamental para identificar dónde se transmite información sensible y garantizar que se cifre adecuadamente.
- Optimización de costos:Identificar llamadas redundantes o transferencias de datos ineficientes ayuda a reducir los gastos de infraestructura.
Sin embargo, crear un mapa no se trata solo de dibujar cajas y líneas. Se trata de capturar la lógica, los protocolos y las restricciones que rigen el flujo de información.
Definir el alcance de la comunicación 🚧
Antes de dibujar un solo diagrama, es necesario definir qué constituye un evento de comunicación. En las arquitecturas de microservicios, las interacciones generalmente se clasifican en dos categorías principales: síncronas y asíncronas. Distinguir entre estas es el primer paso para un mapeo preciso.
Comunicación síncrona
Las interacciones síncronas ocurren cuando el llamador espera una respuesta inmediata. Este es el modelo tradicional de solicitud-respuesta encontrado en la mayoría de las aplicaciones web.
- HTTP/REST:El protocolo más común. Un cliente envía una solicitud y se bloquea hasta que el servidor responde.
- gRPC:A menudo utilizado para la comunicación interna entre servicios debido a su rendimiento y tipado fuerte.
- GraphQL:Permite a los clientes solicitar estructuras de datos específicas, cambiando la forma en que los servicios exponen sus puntos finales.
Mapear estos flujos requiere documentar los puntos finales, las cargas esperadas y las estrategias de manejo de errores. Si el Servicio A llama al Servicio B, ¿espera 5 segundos? ¿Qué sucede si el Servicio B no está disponible? Estos detalles son críticos para un mapa completo.
Comunicación asíncrona
Las interacciones asíncronas desacoplan al emisor del receptor. El emisor inicia un mensaje y continúa procesando sin esperar una respuesta directa.
- Colas de mensajes:Los servicios publican mensajes en una cola, y los consumidores los recuperan cuando están listos.
- Flujos de eventos:Los servicios emiten eventos a un registro o flujo, al que otros servicios se suscriben para su procesamiento.
- Trabajos en segundo plano:Tareas desencadenadas por un evento pero ejecutadas más tarde.
Los flujos asíncronos son más difíciles de representar porque la conexión es implícita. No existe una línea directa entre el emisor y el receptor en tiempo de ejecución; comparten un canal común. Documentar estos requiere listar los temas, los esquemas de mensajes y la lógica de suscripción.
Patrones de interacción y sus implicaciones 🔄
Comprender el patrón de interacción ayuda a determinar la fiabilidad y la complejidad del sistema. A continuación se presenta una comparación de los patrones comunes utilizados en arquitecturas distribuidas.
| Patrón | Dirección | Fiabilidad | Casos de uso |
|---|---|---|---|
| Petición-respuesta | Síncrono | Alta (requiere reintentos) | APIs para usuarios, necesidades de datos inmediatas |
| Disparar y olvidar | Asíncrono | Media (depende de la cola) | Registro, notificaciones, análisis |
| Publicar-suscribirse | Asíncrono | Alta (con colas duraderas) | Cambios de estado, eventos entre dominios |
| Patrón Saga | Híbrido | Alta (transacciones compensatorias) | Procesos empresariales complejos de múltiples pasos |
| Interruptor de circuito | Protector | Evita fallas en cadena | Evita la sobrecarga de servicios secundarios |
Al mapear su sistema, debe anotar cada interacción entre servicios con el patrón que se está utilizando. Por ejemplo, un servicio que llama a una base de datos es sincrónico. Un servicio que envía un correo de confirmación de pedido es asíncrono. Un servicio que orquesta un flujo de compra utilizando múltiples servicios podría usar el patrón Saga.
Una estrategia paso a paso para el mapeo 🛠️
¿Cómo pasar de una base de código caótica a un diagrama claro? Intentar mapear todo de una vez con frecuencia conduce al agotamiento y a datos incompletos. Un enfoque por fases produce mejores resultados.
1. Identifique los puntos de entrada
Comience desde el borde. Documente la pasarela de API o el balanceador de carga. ¿Qué solicitudes externas ingresan al sistema? ¿Qué protocolos utilizan? Esto define el límite de su diagrama.
- Enumere todos los puntos finales públicos.
- Identifique los mecanismos de autenticación.
- Mapee las reglas de enrutamiento que dirigen el tráfico a servicios internos.
2. Rastree las rutas críticas
No intente mapear cada función individual. Enfóquese en los flujos de negocio críticos. Para una plataforma de comercio electrónico, esto sería el proceso de compra. Para una red social, podría ser la generación de feed o la entrega de notificaciones.
- Siga una sola solicitud de usuario desde el inicio hasta el final.
- Anote cada servicio que se toca durante el recorrido.
- Registre los datos que se pasan entre cada salto.
3. Documente las dependencias internas
Una vez mapeadas las rutas críticas, mire hacia adentro. ¿Cómo se comunican los servicios entre sí fuera de los flujos principales de usuario? Esto incluye comprobaciones de salud, recuperación de configuración y trabajos de procesamiento por lotes.
- Verifique los registros de servicios para identificar pares conocidos.
- Revise los archivos de configuración en busca de nombres de colas o suscripciones a temas.
- Inspeccione los manifiestos de orquestación de contenedores en busca de proxies sidecar.
4. Valide con guías de operación
La documentación a menudo se vuelve obsoleta. El mejor método de validación es usar el mapa durante un incidente. Si depende de un diagrama para corregir un error y los pasos no coinciden con la realidad, el mapa necesita actualizarse. Trate el diagrama como una fuente de verdad que debe ser probada.
Manejo de flujos asíncronos y flujos de eventos 📬
La comunicación asíncrona es donde muchos esfuerzos de mapeo fracasan. Debido a que no hay un intercambio directo, el acoplamiento permanece oculto. Para mapearlo de forma efectiva, debe examinar la capa de infraestructura.
Centralización del conocimiento sobre eventos
Los eventos a menudo se definen en registros de esquemas o repositorios de documentación. Crear un índice central de todos los eventos le permite ver qué servicios publican y cuáles se suscriben.
- Esquemas de eventos: Define la estructura de los datos que se envían. Si el esquema cambia, el consumidor debe saberlo.
- Propiedad del tema: ¿Quién es responsable de mantener el broker de mensajes? ¿Quién es responsable de los consumidores?
- Monitoreo de la lista de pendientes:Una alta latencia en una cola indica un cuello de botella en el procesamiento, lo cual debe señalarse en el estado del sistema.
Visualización del flujo
En un diagrama, los flujos asíncronos deben verse diferentes a los síncronos. Utilice líneas punteadas para representar colas de mensajes y líneas sólidas para llamadas directas. Etiquete las líneas punteadas con el nombre del evento y el tema.
Considere el escenario en el que el Servicio A publica un OrderCreatedevento. El Servicio B y el Servicio C se suscriben ambos a él. El Servicio B procesa el pago, mientras que el Servicio C actualiza el inventario. Sin un mapa, es fácil olvidar que el Servicio C existe o que depende del mismo evento que el Servicio B.
Gestión del cambio y la evolución 🌱
Un mapa estático es un mapa inútil. Los servicios evolucionan, las APIs se rompen y cambia la infraestructura. El objetivo es crear un proceso en el que el mapa se actualice naturalmente a medida que cambia el código.
Descubrimiento automatizado
Aunque la documentación manual es valiosa, está propensa a desviarse. Donde sea posible, utilice herramientas de descubrimiento automatizado para generar los datos subyacentes de sus diagramas. Los sistemas de rastreo pueden registrar llamadas entre servicios y exportarlas como gráficos de dependencias.
- Integre los datos de rastreo en la canalización de documentación.
- Configure alertas para nuevas dependencias que aparezcan inesperadamente.
- Utilice el análisis de código para identificar declaraciones de importación que indiquen dependencias potenciales.
Control de versiones para diagramas
Trate los diagramas de arquitectura como código. Guárdelos en el mismo repositorio que el código de la aplicación. Exija que cualquier solicitud de extracción que cambie una interfaz de servicio incluya una actualización correspondiente al diagrama.
- Utilice un sistema de control de versiones para rastrear los cambios con el tiempo.
- Revise los cambios en los diagramas durante los procesos de revisión de código.
- Mantenga versiones históricas para comprender cómo ha cambiado la arquitectura.
Errores comunes en el mapeo 🚫
Incluso con una estrategia sólida, los equipos a menudo caen en trampas que reducen la utilidad del mapa.
Dependencias circulares
Cuando el Servicio A llama al Servicio B, y el Servicio B llama al Servicio A, se crea un bucle. Esto hace que el sistema sea frágil y difícil de depurar. El mapeo debe destacar estos bucles para que puedan refactorizarse.
- Identifique ciclos en el grafo de dependencias.
- Refactorice para romper el ciclo utilizando eventos o interfaces compartidas.
- Documente la razón del ciclo si no puede eliminarse de inmediato.
Acoplamiento oculto
Los servicios podrían compartir una base de datos o un sistema de archivos sin llamadas de API explícitas. Esto es un acoplamiento fuerte disfrazado de acoplamiento débil. Debe documentarse claramente, ya que afecta las estrategias de despliegue.
- Verifique los montajes de almacenamiento compartido.
- Revisa las cadenas de conexión de la base de datos para los esquemas compartidos.
- Documenta los recursos compartidos explícitamente en la arquitectura.
Sobrediseñar el diagrama
Intentar mapear cada llamada a función resulta en un diagrama demasiado complejo para leer. Enfócate en los flujos de alto nivel y en las rutas críticas. Los detalles pueden almacenarse en comentarios del código o en la documentación de la API.
- Utiliza niveles de abstracción. De alto nivel para la gestión, de bajo nivel para los ingenieros.
- Enlaza la documentación detallada de la API con los nodos del diagrama de alto nivel.
- Elimina la lógica interna innecesaria del mapa.
El elemento humano de los diagramas 👥
La tecnología es solo la mitad del desafío. La otra mitad es la capacidad del equipo para entender y utilizar el mapa. Un diagrama que nadie lee es peor que no tener ningún diagrama.
Estandarizar la notación
Asegúrate de que todos en el equipo entiendan los símbolos utilizados. Si usas un color específico para flujos asíncronos, todos deben saber que ese color representa ese protocolo. La consistencia reduce la carga cognitiva.
- Crea una leyenda para tus diagramas.
- Acuerda convenciones de nomenclatura para los servicios.
- Define íconos estándar para bases de datos, colas y sistemas externos.
Accesibilidad y distribución
¿Dónde se almacena el diagrama? Si está enterrado en una unidad de documentos personal, es inaccesible. Guárdalo en un lugar central y buscable accesible para todos los ingenieros.
- Alberga los diagramas en la wiki interna o en el sitio de documentación.
- Asegúrate de que los diagramas se representen correctamente en los visores de markdown.
- Enlaza los diagramas desde los archivos README del servicio.
Fomentar las actualizaciones
Haz que actualizar el mapa forme parte de la definición de terminado. Si un desarrollador cambia el código pero olvida el mapa, el trabajo está incompleto. Este cambio cultural asegura que la documentación permanezca relevante.
- Incluye las actualizaciones del diagrama en la lista de verificación de la solicitud de extracción.
- Elogia a los miembros del equipo que mantienen la documentación actualizada.
- Audita regularmente los mapas contra el sistema en funcionamiento.
Depuración con el mapa 🐞
La prueba definitiva de un mapa de comunicación es su utilidad durante un incidente. Cuando el sistema es lento o falla, el mapa se convierte en una herramienta de diagnóstico.
- Rastrea la solicitud:Utiliza el mapa para identificar qué servicio en la cadena es probable que sea el cuello de botella.
- Verifica el estado de salud:Verifica si las dependencias mapeadas están activas y funcionando.
- Analizar registros: Busque errores en los servicios identificados por el mapa.
- Validar configuración: Asegúrese de que la configuración coincida con el mapa (por ejemplo, nombres de colas, URLs de puntos finales).
Si el mapa es preciso, reduce significativamente el tiempo medio para resolver problemas (MTTR). Los ingenieros pueden omitir las suposiciones y centrarse en el nodo específico que requiere atención.
Mantener la claridad con el tiempo ⏳
A medida que el sistema crece, el mapa también crecerá. Para evitar que se convierta en una red enredada, debe gestionar su complejidad.
- Vistas por capas: Cree diagramas diferentes para distintos públicos. De alto nivel para ejecutivos, detallados para ingenieros.
- Propiedad del servicio: Asigne la propiedad de diagramas específicos a equipos específicos. Esto garantiza que alguien sea responsable de su precisión.
- Revisiones regulares: Programar revisiones trimestrales de la arquitectura para eliminar código muerto y actualizar flujos.
- Bucles de retroalimentación: Permita a los ingenieros sugerir correcciones a los diagramas cuando encuentren discrepancias en producción.
Al tratar el mapa como un artefacto vivo, asegura que permanezca un activo valioso en lugar de una reliquia histórica. La complejidad de los microservicios es inevitable, pero el caos que la rodea es opcional. Con un enfoque disciplinado en el mapeo, puede navegar el entorno distribuido con confianza y claridad.