











En la arquitectura de software moderna, las interfaces de programación de aplicaciones (APIs) actúan como el tejido conectivo entre los servicios. Cuando estas conexiones fallan, todo el sistema puede detenerse. Identificar la fuente de la degradación del rendimiento requiere más que solo monitorear métricas; exige una comprensión estructural de cómo fluye la información a través del sistema. Los diagramas de comunicación ofrecen un método preciso para visualizar este flujo, permitiendo a los ingenieros identificar exactamente dónde ocurren los cuellos de botella.
Esta guía explora la mecánica de diagnosticar cuellos de botella de API desde la perspectiva de los diagramas de comunicación. Examinaremos la representación visual de las interacciones entre objetos, analizaremos patrones de mensajes que indican estrés y delinearemos un enfoque sistemático para resolver problemas de latencia y rendimiento sin depender de herramientas propietarias.
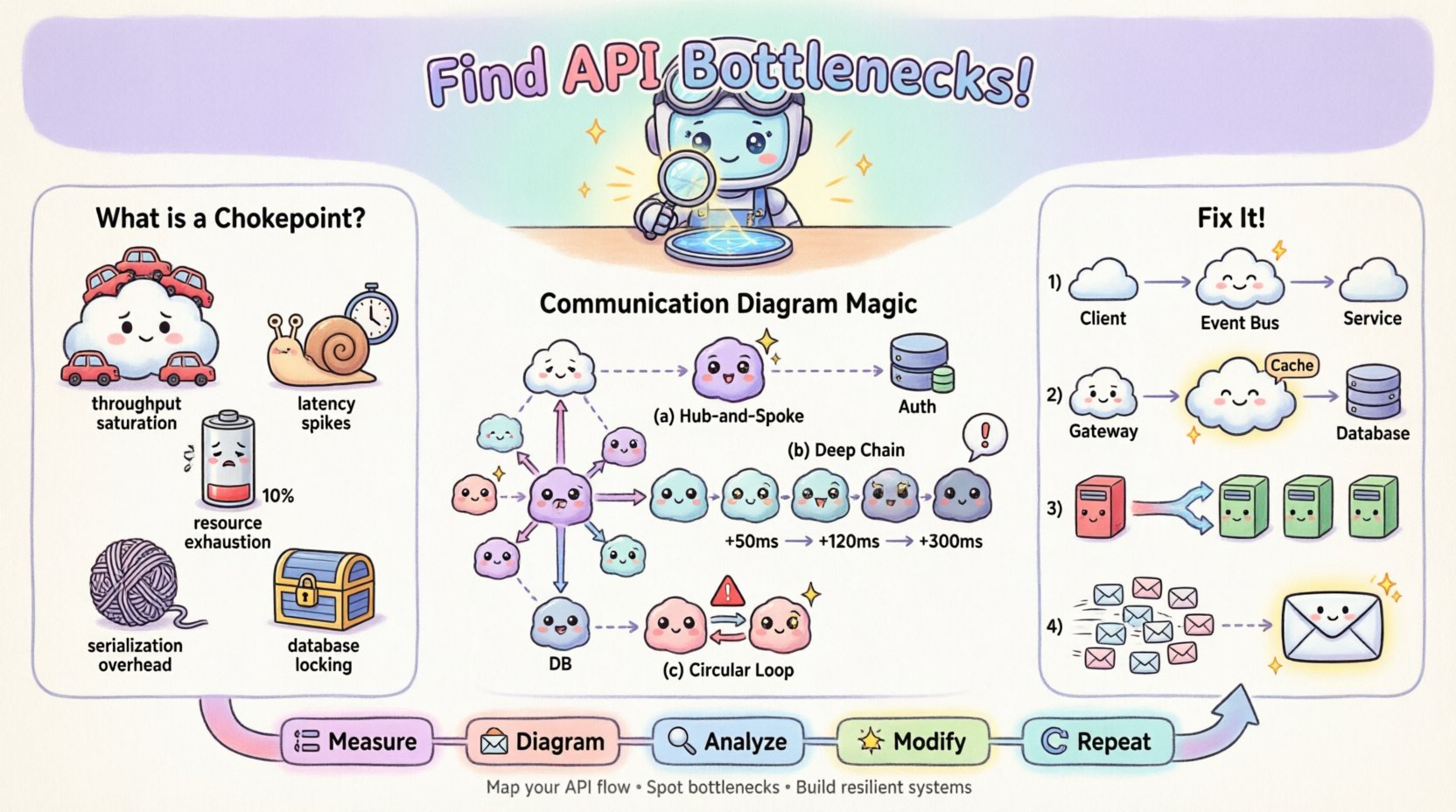
🚦 Comprender los cuellos de botella de API
Un cuello de botella de API es un punto específico dentro del ciclo de solicitud-respuesta donde el procesamiento se ralentiza o falla, causando una acumulación de solicitudes. A diferencia de la latencia de red general, que afecta toda la transmisión, un cuello de botella suele estar localizado en un servicio específico, una consulta a la base de datos o un mecanismo de sincronización. Reconocer el tipo de cuello de botella es el primer paso hacia una corrección efectiva.
Los tipos comunes de cuellos de botella incluyen:
- Saturación de rendimiento: El servicio receptor no puede procesar las solicitudes entrantes con suficiente rapidez, lo que provoca una acumulación en la cola.
- Picos de latencia: Una llamada específica tarda significativamente más que el promedio, retrasando los procesos posteriores.
- Agotamiento de recursos: Se alcanzan los límites de CPU, memoria o grupo de conexiones, lo que provoca tiempos de espera o errores de rechazo.
- Sobrecarga de serialización: Los costos de transformación de datos (por ejemplo, análisis de JSON) se vuelven excesivos debido al tamaño de la carga útil.
- Bloqueo de base de datos: Las escrituras concurrentes bloquean lecturas u otras escrituras, deteniendo el flujo de transacciones.
Cuando ocurren estos problemas, a menudo se manifiestan como fallos en cadena. Un retraso en un microservicio puede desencadenar tiempos de espera en el servicio que lo llama, lo que luego se propaga hacia arriba en la cadena. Visualizar esta cadena es fundamental.
📐 El papel de los diagramas de comunicación en la depuración
Los diagramas de comunicación, un tipo de diagrama de interacción de UML (Lenguaje Unificado de Modelado), se centran en la organización estructural de los objetos y los mensajes intercambiados entre ellos. A diferencia de los diagramas de secuencia, que priorizan el orden cronológico de los mensajes, los diagramas de comunicación enfatizan las relaciones y enlaces entre los objetos. Este enfoque estructural los hace particularmente eficaces para identificar cuellos de botella arquitectónicos.
¿Por qué usar este tipo específico de diagrama para la solución de problemas?
- Enfoque en la estructura: Revela qué objetos son centros principales. Un objeto único que recibe mensajes de diez otros es un candidato ideal para un cuello de botella.
- Conteo de mensajes: Puedes contar visualmente el número de mensajes intercambiados en una sola transacción. Un alto número de salidas indica posibles problemas de procesamiento paralelo.
- Análisis de rutas: Destaca la ruta de ejecución más larga. Las largas cadenas de llamadas síncronas son propensas a acumular latencia.
- Claridad de contexto: Muestra el contexto en el que existen los objetos, ayudando a identificar si un servicio está sobrecargado debido a su rol y no a su código.
Al mapear las interacciones de la API en un diagrama de comunicación, transformas registros abstractos en un mapa tangible. Este mapa te permite rastrear la ruta exacta que sigue una solicitud y medir el esfuerzo requerido en cada nodo.
🛠️ Creación del diagrama diagnóstico
Para utilizar un diagrama de comunicación para la resolución de problemas, primero debe construir una representación precisa del estado actual del sistema. Este proceso requiere recopilar datos de registros, herramientas de trazado y documentación arquitectónica. El objetivo es crear un modelo que refleje la realidad, no un diseño idealizado.
Paso 1: Identificar a los actores y objetos
Comience definiendo a los clientes externos y servicios internos involucrados en la transacción problemática. En el contexto de una API, estos suelen ser:
- Cliente: La aplicación móvil, navegador web o servicio de terceros que inicia la solicitud.
- Pasarela: El punto de entrada que maneja la autenticación, el control de tasa y el enrutamiento.
- Orquestador: El servicio que coordina el flujo de lógica de negocio.
- Dependencias: Bases de datos, APIs externas, capas de caché y trabajadores en segundo plano.
Paso 2: Mapa de los flujos de mensajes
Dibuje las conexiones entre estos objetos. Cada línea representa un mensaje. Use flechas para indicar la dirección del flujo de datos. Etiquete cada flecha con el nombre del método o la acción que se realiza (por ejemplo, GET /pedidos, procesarPago).
Para la resolución de problemas, es crucial anotar el diagrama con datos de rendimiento. Si tiene acceso a métricas de tiempo, agréguelas a las etiquetas de los mensajes. Por ejemplo:
- Pasarela ➔ Orquestador: 50ms
- Orquestador ➔ Base de datos: 450ms (Advertencia)
- Base de datos ➔ Orquestador: 450ms
Paso 3: Definir las líneas de vida de interacción
Aunque los diagramas de comunicación no muestran siempre de forma explícita las líneas de vida verticales como los diagramas de secuencia, debe rastrear mentalmente la duración de la participación de cada objeto. Un objeto que permanece activo durante mucho tiempo mientras espera una respuesta está utilizando recursos innecesariamente.
🔎 Identificación de cuellos de botella en el diagrama
Una vez que el diagrama está poblado con datos, puede comenzar el análisis. La disposición visual revela a menudo problemas que los registros crudos ocultan. Busque patrones específicos que indiquen un cuello de botella.
Patrón 1: La estrella de eje y radios
Si ve un objeto único conectado a muchos otros en un patrón de estrella, ese objeto central probablemente es un cuello de botella. Cada solicitud debe pasar por él. Si ese objeto es síncrono, se convierte en un punto de procesamiento serial.
| Indicador visual | Implicación | Causa común |
|---|---|---|
| Un objeto con 10+ flechas entrantes | Alta carga de concurrencia | Servicio de agregación |
| Varias flechas horizontales largas que convergen | Acumulación de tiempo de espera | Distribución síncrona |
| Objeto etiquetado con alto porcentaje de CPU | Saturación de procesamiento | Lógica compleja |
Patrón 2: Cadenas de llamadas profundas
Rastree la ruta más larga desde el punto de entrada hasta la recuperación final de datos. Si la ruta implica cinco o más saltos, la latencia se acumulará. Cada salto añade sobrecarga de red y tiempo de procesamiento.
- Impacto:Latencia total = Suma de todas las latencias de salto + sobrecarga de red.
- Solución:Reduzca la profundidad de la cadena de llamadas al colocar los datos juntos o utilizando un único punto final de agregación.
Patrón 3: Dependencias circulares
Aunque menos común en sistemas bien estructurados, los mensajes circulares (A llama a B, B llama a A) pueden causar bloqueos o bucles infinitos. En un contexto de rendimiento, indican una gestión ineficiente del estado.
🛠️ Estrategias de corrección basadas en el análisis visual
Una vez localizado el cuello de botella en el diagrama, se pueden aplicar cambios arquitectónicos específicos. El diagrama sirve como plano para estos cambios.
1. Desacoplamiento de llamadas síncronas
Si el diagrama muestra una larga cadena de llamadas síncronas, convierta la cola de la cadena en un evento asíncrono. En lugar de esperar la respuesta, el orquestador puede disparar un evento y devolver inmediatamente.
- Antes: Usuario ➔ API ➔ Servicio A ➔ Servicio B ➔ Base de datos (Esperar)
- Después: Usuario ➔ API ➔ Servicio A ➔ Bus de eventos ➔ Servicio B (Disparar y olvidar)
2. Caché en el borde
Si el diagrama muestra solicitudes repetidas al mismo objeto para los mismos datos, introduzca una capa de caché. Coloque este objeto entre el llamador y el recurso pesado.
- Cambio en el diagrama: Inserte un objeto “Caché” entre la Puerta de enlace y la Base de datos.
- Actualización de etiqueta: Actualiza la etiqueta del mensaje para mostrar «Cache Hit: 1ms» frente a «Cache Miss: 200ms».
3. Distribución de carga y fragmentación
Si un objeto único tiene demasiadas conexiones (patrón Hub-and-Spoke), distribuye la carga. Esto podría implicar fragmentar los datos o introducir un equilibrador de carga para rotar el tráfico entre múltiples instancias de ese servicio.
4. Agrupación de solicitudes
Si el diagrama muestra múltiples mensajes pequeños enviados al mismo objeto de forma consecutiva, combínalos en una única solicitud agrupada. Esto reduce la sobrecarga de establecimiento de conexiones y el cambio de contexto.
📊 Análisis de rendimiento frente a latencia
Los diagramas de comunicación también pueden ayudar a distinguir entre problemas de rendimiento y problemas de latencia. Esta distinción es vital para elegir la solución adecuada.
- Alta latencia, bajo rendimiento: El sistema es lento pero maneja pocas solicitudes. Esto suele indicar una única operación pesada (por ejemplo, la generación de un informe complejo).
- Baja latencia, bajo rendimiento: El sistema es rápido pero rechaza muchas solicitudes. Esto indica límites de recursos (por ejemplo, agotamiento de la piscina de conexiones).
- Alta latencia, alto rendimiento: El sistema es lento y está manejando muchas solicitudes. Este es el escenario clásico de cuello de botella donde la capacidad se ve superada.
Al anotar tu diagrama con estas métricas, puedes visualizar la curva de capacidad. Anota el escenario «Carga pesada» en tu diagrama para ver qué nodo falla primero.
⚠️ Errores comunes al crear diagramas para depuración
Incluso con las mejores intenciones, crear un diagrama para la depuración puede generar confusión si no se evitan ciertos errores.
- Sobreactualización: No agrupes demasiados servicios en una sola caja. Si ocultas la complejidad interna de un servicio, no podrás ver dónde se encuentra el cuello de botella interno. Mantén los servicios atómicos.
- Ignorar flujos asíncronos: Si tu diagrama solo muestra solicitudes síncronas, no reflejará la carga real. Incluye trabajos en segundo plano y escuchadores de eventos en el diagrama.
- Estático frente a dinámico: Un diagrama estático muestra el diseño; un diagrama dinámico muestra la ejecución en tiempo real. Para la depuración, asegúrate de usar datos en tiempo real (los caminos reales recorridos).
- Rutas de error omitidas: La mayoría de los diagramas muestran el camino ideal. Un cuello de botella suele ocurrir durante el manejo de errores (por ejemplo, reintentos, alternativas). Incluye los bucles de reintento en el diagrama.
🔄 Mejora iterativa del diagrama
La arquitectura no es estática. A medida que aplicas soluciones, el diagrama debe evolucionar. Tras implementar una capa de caché, el diagrama cambia. El mensaje del Gateway a la Base de datos se reemplaza por un mensaje a la Caché.
Este proceso iterativo crea un bucle de retroalimentación:
- Medir: Captura las métricas de rendimiento actuales.
- Diagrama: Mapa el flujo con métricas.
- Analizar:Identifica el cuello de botella.
- Modificar:Aplica un cambio arquitectónico.
- Repetir:Vuelve a medir y actualiza el diagrama.
Este ciclo asegura que los esfuerzos de optimización se basen en datos en lugar de adivinanzas.
📈 Integración con sistemas de monitoreo
Aunque los diagramas de comunicación son herramientas visuales, deben estar basados en datos de sistemas de monitoreo. Deberías correlacionar los nodos del diagrama con flujos de registro específicos o identificadores de telemetría.
- IDs de seguimiento:Asegúrate de que cada mensaje en el diagrama corresponda a un ID de seguimiento único en tu sistema de registro.
- Mapas de calor:Si tu herramienta de monitoreo lo permite, visualiza la frecuencia de llamadas como un mapa de calor en el diagrama. Los colores más intensos indican un mayor volumen de tráfico.
- Alertas:Configura alertas para los nodos específicos identificados como cuellos de botella. Si el nodo «Base de datos» presenta un pico, activa una notificación.
🧠 Estudio de caso: La cadena de procesamiento de pedidos
Considera un escenario en el que el proceso de pago de una tienda en línea es lento. La solicitud inicial muestra un retraso de 5 segundos.
Análisis inicial del diagrama:
- Cliente ➔ Pasarela de API (10ms)
- Pasarela ➔ Servicio de Pedidos (50ms)
- Servicio de Pedidos ➔ Servicio de Inventario (200ms)
- Servicio de Pedidos ➔ Servicio de Pago (4000ms)
- Servicio de Pedidos ➔ Servicio de Notificaciones (50ms)
Observación:
El diagrama revela que el Servicio de Pago es el anómalo. Consuma el 80 % del tiempo total. El Servicio de Pedidos espera de forma sincrónica a que el Servicio de Pago finalice antes de continuar.
Intervención:
1. Mueve el pago a un flujo asíncrono. El Servicio de Pedidos envía la solicitud y marca el pedido como «En proceso». 2. Un trabajador en segundo plano maneja la confirmación del pago. 3. Actualiza el diagrama para mostrar un objeto «Trabajador de Pago» en lugar de una llamada directa.
Resultado:
El usuario ve el estado «En proceso» de inmediato. La latencia total para la experiencia del usuario baja de 5 segundos a 50 milisegundos. El backend realiza la carga pesada de forma asíncrona. El diagrama ahora refleja una arquitectura más resiliente.
🎯 Mejores prácticas para el mantenimiento
Para mantener estos diagramas útiles con el paso del tiempo, siga las siguientes prácticas de mantenimiento.
- Control de versiones:Almacene los archivos del diagrama en el mismo repositorio que la base de código. Cuando cambie el código, el diagrama también debe cambiar.
- Ciclos de revisión:Incluya revisiones de diagramas en los registros de decisiones arquitectónicas. Asegúrese de que los nuevos servicios se agreguen al mapa antes de la implementación.
- Estandarización:Utilice una notación consistente para los tipos de mensajes (por ejemplo, solicitud, respuesta, evento) para que los diagramas sean legibles por todos los miembros del equipo.
- Documentación:Añada notas al diagrama que expliquen *por qué* existe una ruta específica. Esto evita que ingenieros futuros eliminen lógica necesaria.
🔗 Conclusión
Solucionar problemas de rendimiento de la API es una combinación de análisis de datos y visualización estructural. Los diagramas de comunicación proporcionan la estructura necesaria para comprender interacciones complejas. Al mapear flujos de mensajes, anotar datos de tiempo y analizar patrones de conexión, puede identificar cuellos de botella con precisión. Este enfoque va más allá de la suposición y permite mejoras arquitectónicas dirigidas que mejoran la estabilidad y velocidad del sistema.
Recuerde que el diagrama es un documento vivo. Debe evolucionar a medida que crece el sistema. Revisar periódicamente el mapa garantiza que las nuevas características no introduzcan nuevos cuellos de botella. Con una visión clara del flujo, puede mantener un sistema sano y de alto rendimiento.