











Der Aufbau zuverlässiger Software-Systeme erfordert mehr als nur funktionellen Code zu schreiben. Es erfordert ein klares Verständnis dafür, wie sich das System unter verschiedenen Bedingungen verhält. Zustandsmaschinen-Diagramme, die oft einfach als Zustandsdiagramme bezeichnet werden, liefern die Baupläne für dieses Verhalten. Sie zeigen die unterschiedlichen Zustände auf, in denen sich ein System befinden kann, sowie die Regeln für Übergänge zwischen ihnen. Wenn jedoch Systeme an Komplexität gewinnen, steigt die Wahrscheinlichkeit logischer Fehler. Die Fehlerbehebung erfordert einen strukturierten Ansatz, tiefes Verständnis der zugrundeliegenden Logik und eine systematische Eliminierung von Variablen.
Diese Anleitung beschreibt die wesentlichen Strategien zur Identifizierung und Behebung logischer Fehler in zustandsbasierten Architekturen. Durch das Verständnis der Struktur von Zustandsübergängen und gängiger Fallen können Ingenieure die Integrität des Systems gewährleisten, ohne sich auf Vermutungen zu stützen.
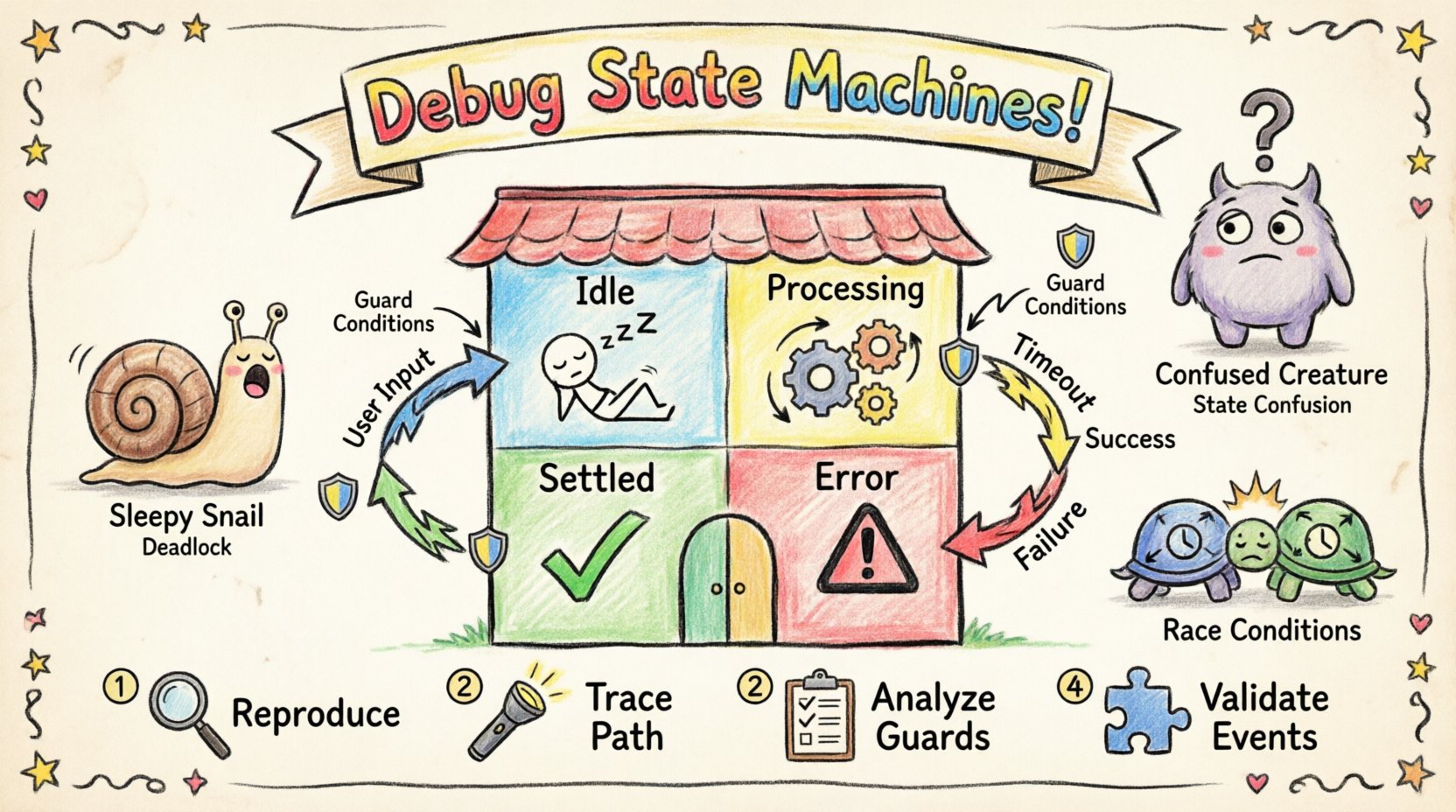
🔍 Verständnis der Struktur einer Zustandsmaschine
Bevor man Fehler behebt, muss man die Komponenten verstehen, die die Zustandsmaschine antreiben. Ein Zustandsdiagramm ist nicht nur eine visuelle Darstellung; es ist ein logischer Vertrag, der den Lebenszyklus des Systems definiert. Jedes Element hat eine spezifische Aufgabe bei der Steuerung von Ablauf und Daten.
- Zustände: Unterschiedliche Modi oder Zustände, in denen sich das System befinden kann. Beispiele sind Wartend, Verarbeitung, oder Fehler.
- Übergänge: Die Pfade, die Zustände verbinden. Ein Übergang tritt ein, wenn ein bestimmtes Ereignis eine Änderung von einem Zustand in einen anderen auslöst.
- Ereignisse: Signale oder Aktionen, die Übergänge auslösen. Dies können interne Aktionen oder externe Eingaben sein.
- Wächter: Boolesche Bedingungen, die während eines Übergangs überprüft werden. Der Übergang findet nur statt, wenn der Wächter den Wert wahr ergibt.
- Aktionen: Operationen, die beim Betreten, Verlassen oder während eines Übergangs ausgeführt werden. Dazu können Protokollierung, Datenaktualisierungen oder das Auslösen externer Dienste gehören.
- Anfangs-/Endzustände: Der Ausgangspunkt und der Endpunkt des Lebenszyklus.
Beim Debuggen ist es entscheidend, sicherzustellen, dass diese Komponenten korrekt miteinander interagieren. Ein logischer Fehler stammt oft aus einer Diskrepanz zwischen dem im Diagramm definierten erwarteten Verhalten und dem tatsächlichen Verhalten in der Laufzeitumgebung.
🚨 Häufige logische Fehler und ihre Symptome
Komplexe Systeme leiden häufig an bestimmten Arten logischer Ausfälle. Die frühzeitige Erkennung der Symptome kann erhebliche Zeit während des Debugging-Prozesses sparen. Die folgende Tabelle gliedert gängige Probleme nach Art, beobachtbaren Symptomen und wahrscheinlichen Ursachen.
| Fehlertyp | Symptom | Ursache |
|---|---|---|
| Falsche Übergänge | Das System wechselt in einen unerwarteten Zustand ohne klaren Auslöser. | Fehlende Wächterbedingungen oder sich überlappende Ereignishandler. |
| Totlager | Das System hält an und reagiert nicht auf gültige Eingaben. | Keine ausgehenden Übergänge aus einem bestimmten Zustand für bestimmte Ereignisse. |
| Unerreichbare Zustände | Bestimmte Zustände werden während des normalen Betriebs nie betreten. | Falsche Eingangspfade oder Logik, die bestimmte Zustände umgeht. |
| Zustandsverwirrung | Das System verhält sich im selben Zustand unterschiedlich abhängig von der Historie. | Fehlschlag beim Zurücksetzen des Kontexts oder beim korrekten Verwalten von Historiezuständen. |
| Konkurrierende Rennbedingungen | Widersprüchliche Aktionen treten gleichzeitig in parallelen Zuständen auf. | Fehlende Synchronisation zwischen konkurrierenden Untermaschinen. |
🧪 Schritt-für-Schritt-Debugging-Methode
Die Behebung von Zustandsmaschinenproblemen erfordert einen disziplinierten Arbeitsablauf. Schnelllösungen führen oft zu neuen Fehlern. Folgen Sie diesem systematischen Ansatz, um Logikfehler zu isolieren und zu beheben.
1. Problem reproduzieren
Bevor Sie eine Korrektur versuchen, müssen Sie den Fehler zuverlässig reproduzieren. Wenn das Problem intermittierend auftritt, dokumentieren Sie die Ereignisfolge, die zum Ausfall führt.
- Identifizieren Sie die spezifische Eingabe oder das Ereignis, das das fehlerhafte Verhalten auslöst.
- Notieren Sie den aktuellen Zustand des Systems, bevor das Ereignis eintritt.
- Notieren Sie den Zustand, in den das System nach dem Ereignis wechselt.
- Prüfen Sie, ob das Problem konsistent auftritt oder nur unter bestimmten Bedingungen (z. B. bestimmte Datenwerte).
2. Ausführungsverlauf verfolgen
Verwenden Sie Protokollierungsmechanismen, um den Ausführungsverlauf zu verfolgen. Jeder Übergang sollte mit relevantem Kontext protokolliert werden.
- Ein- und Ausgangsprotokollierung:Protokollieren Sie, wann ein Zustand betreten und verlassen wird.
- Übergangsprotokollierung:Protokollieren Sie das Ereignis, das den Übergang ausgelöst hat.
- Wächterauswertung:Protokollieren Sie, ob Wächterbedingungen bestanden oder fehlgeschlagen sind und warum.
- Aktionenprotokollierung: Protokollieren Sie, wenn Aktionen ausgeführt und ihre Ausgabe erzeugt wird.
Diese Daten erstellen eine Ereignischronologie. Vergleichen Sie diese Chronologie mit dem Zustandsdiagramm. Suchen Sie nach Abweichungen, bei denen der Code von der Gestaltung abweicht.
3. Prüfen Sie die Wächterbedingungen
Wächterbedingungen sind häufige Quellen für Logikfehler. Eine Übergangsmöglichkeit könnte im Diagramm sichtbar erscheinen, aber eine versteckte Bedingung verhindert, dass sie ausgelöst wird.
- Überprüfen Sie alle Wächterbedingungen, die mit dem problematischen Übergang verbunden sind.
- Stellen Sie sicher, dass die in der Wächterbedingung verwendeten Variablen mit den zur Ereigniszeit verfügbaren Daten übereinstimmen.
- Prüfen Sie auf Nebenwirkungen bei der Auswertung der Wächterbedingung, die den Zustand unerwartet verändern könnten.
- Stellen Sie sicher, dass Wächter nicht zu restriktiv sind und gültige Übergänge blockieren.
4. Überprüfen Sie die Ereignisbehandlung
Ereignisse sind die Auslöser für Veränderungen. Wenn ein Ereignis nicht korrekt behandelt wird, kann das System es ignorieren oder in einem falschen Zustand verarbeiten.
- Stellen Sie sicher, dass der Ereignisname zwischen der Quelle und der Zustandsmaschine exakt übereinstimmt.
- Stellen Sie sicher, dass das Ereignis an die richtige Instanz der Zustandsmaschine gesendet wird.
- Stellen Sie sicher, dass das Ereignis nicht von einem übergeordneten Zustand verbraucht wird, wenn ein untergeordneter Zustand es behandeln sollte.
- Bestätigen Sie, dass die Ereigniswarteschlange Ereignisse in der erwarteten Reihenfolge verarbeitet.
🔄 Umgang mit Konkurrenz und parallelen Zuständen
Fortgeschrittene Zustandsmaschinen nutzen häufig konkurrierende Zustände. Dadurch können mehrere unabhängige Zustandsmaschinen innerhalb eines zusammengesetzten Zustands gleichzeitig laufen. Obwohl dies leistungsstark ist, führt es zu Komplexität bezüglich Synchronisation und Datenfreigabe.
1. Synchronisationspunkte
In konkurrierenden Umgebungen müssen Übergänge synchronisiert werden, um Rennbedingungen zu vermeiden. Ein Übergang in einem parallelen Zustand könnte von der Fertigstellung eines Übergangs in einem anderen abhängen.
- Definieren Sie klare Synchronisationsbarrieren, an denen parallele Zustände ausgerichtet sein müssen.
- Verwenden Sie Flags oder Statusvariablen, um die Bereitschaft paralleler Zweige anzugeben.
- Stellen Sie sicher, dass die Endzustände in parallelen Zweigen erreicht sind, bevor der zusammengesetzte Zustand abgeschlossen wird.
2. Integrität gemeinsam genutzter Daten
Parallele Zustände greifen oft auf gemeinsam genutzte Ressourcen zu. Wenn zwei Zustände dieselben Daten gleichzeitig ändern, kann es zu Beschädigungen kommen.
- Implementieren Sie Sperreinrichtungen, wenn auf gemeinsam genutzte Zustandsvariablen zugegriffen wird.
- Verwenden Sie, wenn möglich, unveränderliche Datensstrukturen, um versehentliche Änderungen zu verhindern.
- Prüfen Sie alle Aktionen daraufhin, ob sie globale oder gemeinsam genutzte Zustände verändern.
🛡️ Verifizierungs- und Validierungstechniken
Debuggen ist reaktiv; Verifizierung ist proaktiv. Die Implementierung von Strategien zur Validierung der Zustandsmaschine vor der Bereitstellung verringert die Belastung bei der Fehlerbehebung.
1. Statische Analyse
Statische Analysetools können die Zustandsdiagrammdefinition ohne Ausführung des Codes scannen. Sie können strukturelle Probleme identifizieren.
- Überprüfen Sie auf nicht erreichbare Zustände.
- Identifizieren Sie Übergänge, die durch kein Ereignis ausgelöst werden können.
- Stellen Sie sicher, dass alle Zustände gültige Ausgangspfade haben.
- Stellen Sie sicher, dass alle Ereignisse behandelt werden (keine unbehandelten Ereignisfehler).
2. Modellprüfung
Die Modellprüfung beinhaltet die mathematische Überprüfung, ob der Zustandsautomat bestimmte Eigenschaften erfüllt. Dies ist besonders nützlich für sicherheitskritische Systeme.
- Definieren Sie Eigenschaften wie „das System gelangt niemals in einen toten Zustand“.
- Führen Sie Algorithmen aus, um diese Eigenschaften anhand des Zustandsübergangsgraphen zu überprüfen.
- Verwenden Sie diese Werkzeuge, um komplexe Konkurrenz-Szenarien zu validieren.
3. Unit-Tests für Zustandsmaschinen
Jeder Zustand und jeder Übergang sollte so weit wie möglich unabhängig getestet werden.
- Schreiben Sie Tests, die das System in einen bestimmten Zustand bringen und ein bestimmtes Ereignis auslösen.
- Stellen Sie sicher, dass das System in den korrekten nächsten Zustand übergeht.
- Stellen Sie sicher, dass die erwarteten Aktionen ausgelöst werden.
- Testen Sie Grenzbedingungen, wie das Auslösen eines Ereignisses in einem Zustand, in dem es nicht erlaubt sein sollte.
📝 Dokumentation für zukünftige Wartung
Ein Zustandsautomat, der schwer zu verstehen ist, ist schwer zu debuggen. Klare Dokumentation stellt sicher, dass zukünftige Ingenieure effektiv Fehler beheben können, ohne die Logik rückwärts zu analysieren.
- Code kommentieren:Fügen Sie Inline-Kommentare hinzu, die komplexe Übergänge oder nicht offensichtliche Wächterbedingungen erklären.
- Diagramme pflegen:Halten Sie die visuellen Zustandsdiagramme mit dem Code synchron. Ein veraltetes Diagramm ist eine Gefahr.
- Randfälle dokumentieren:Notieren Sie bekannte Einschränkungen oder spezifische Szenarien, die der Automat anders behandelt.
- Versionskontrolle:Behandeln Sie Zustandsdefinitionen wie Code. Verwenden Sie Versionskontrolle, um Änderungen an der Logik im Laufe der Zeit zu verfolgen.
⚙️ Realitätsnahe Szene: Die Zahlungsverarbeitungskette
Betrachten Sie ein Zahlungsverarbeitungssystem. Die Zustandsmaschine verwaltet den Lebenszyklus einer Transaktion:Initiiert, Autorisiert, Abgeschlossen, oder Fehlgeschlagen.
Stellen Sie sich eine Situation vor, in der eine Transaktion in den Abgeschlossen Zustand eintritt, aber die Datenbank zeigt an, dass es immer noch Autorisiert. Dies ist ein klassischer Zustandsinkonsistenzfehler.
- Diagnose: Der Übergang von Autorisiert zu Abgeschlossen wurde ausgelöst, aber die Zustandsaktualisierungslogik hat versagt, die Änderung im dauerhaften Speicher zu committen.
- Auswirkung: Der Benutzer sieht Erfolg, aber der Hintergrund erwartet, dass die Mittel reserviert sind.
- Lösung: Implementieren Sie eine Transaktionshülle, die sicherstellt, dass die Zustandsaktualisierung und der Datenbankcommit atomar erfolgen.
- Verhinderung: Fügen Sie einen Abgleichjob hinzu, der den Zustand der Zustandsmaschine regelmäßig mit dem Datenbankzustand vergleicht.
🔧 Erweiterte Fehlerbehebungstools
Während die manuelle Verfolgung wirksam ist, können bestimmte Tools den Debugging-Prozess beschleunigen.
- Interaktive Zustandsvisualisierer: Werkzeuge, die es Ihnen ermöglichen, Zustände visuell in Echtzeit Schritt für Schritt zu durchlaufen.
- Log-Aggregatoren: Zentralisierte Protokollsysteme, die eine Filterung nach Zustands-ID oder Ereignistyp ermöglichen.
- Debug-Protokolle: Schnittstellen, die es externen Systemen ermöglichen, den aktuellen Zustand der Maschine abzurufen, ohne sie neu starten zu müssen.
- Simulationsumgebungen:Sandkästen, in denen Sie Ereignissequenzen wiederholen können, um Fehler sicher nachzustellen.
🧠 Kognitiver Aufwand und Zustandskomplexität
Je mehr Zustände es gibt, desto exponentiell steigt der kognitive Aufwand, um die Logik aufrechtzuerhalten. Dies wird als Zustands-Explosionsproblem bekannt.
- Modularisieren:Teilen Sie große Zustandsmaschinen in kleinere, handhabbare Teilmaschinen auf.
- Abstrahieren:Verwenden Sie zusammengesetzte Zustände, um Komplexität von der höheren Logik zu verbergen.
- Beschränken:Beschränken Sie streng die Anzahl gleichzeitiger Zustände, um die Synchronisationskosten zu reduzieren.
- Refaktorisieren:Überprüfen Sie regelmäßig das Zustandsdiagramm, um überflüssige oder überlappende Zustände zu identifizieren.
🛑 Umgang mit unerwarteten Eingaben
Robuste Systeme müssen Eingaben verarbeiten können, die im Zustandsdiagramm nicht definiert sind. Dies wird oft als „Fehlerzustand“ bezeichnet.
- Standardübergänge:Definieren Sie einen Allgemeinübergang für Ereignisse, die in unerwarteten Zuständen auftreten.
- Protokollierung:Protokollieren Sie unerwartete Ereignisse mit hoher Schwere, um Entwickler zu warnen.
- Wiederherstellung:Stellen Sie sicher, dass das System aus einem Fehlerzustand wiederhergestellt werden kann, anstatt abzustürzen.
- Benachrichtigung:Benachrichtigen Sie den Benutzer oder das Überwachungssystem, wenn ein unerwartetes Ereignis auftritt.
📊 Metriken für die Gesundheit der Zustandsmaschine
Um ein gesundes System zu erhalten, verfolgen Sie spezifische Metriken im Zusammenhang mit der Zustandsmaschine.
- Übergangshäufigkeit:Wie oft bestimmte Übergänge auftreten. Plötzliche Änderungen könnten auf einen Fehler hindeuten.
- Zustandsdauer:Wie lange das System in einem bestimmten Zustand verbleibt. Lange Dauern könnten auf eine Blockade hindeuten.
- Fehlerquote: Der Prozentsatz der Ereignisse, die zu Fehlerübergängen führen.
- Anzahl der Verklemmungen: Die Anzahl der Male, bei denen das System in einen Zustand mit keinen ausgehenden Übergängen gelangt.
🚀 Schlussfolgerung zur Systemintegrität
Die Aufrechterhaltung der Integrität eines Zustandsautomaten ist ein fortlaufender Prozess. Er erfordert Aufmerksamkeit, klare Dokumentation und ein tiefes Verständnis der Logikflüsse. Durch die Einhaltung der oben beschriebenen Methoden können Ingenieure Logikfehler effektiv beheben und sicherstellen, dass komplexe Systeme vorhersehbar funktionieren.
Denken Sie daran, dass das Ziel nicht nur darin besteht, den unmittelbaren Fehler zu beheben, sondern auch die Gesamtrobustheit der Architektur zu verbessern. Ein gut gestalteter Zustandsautomat dokumentiert sich selbst und ist widerstandsfähig gegenüber Änderungen. Investieren Sie Zeit in die Entwurfsphase, um die Kosten für die spätere Fehlerbehebung zu senken.
Wenden Sie diese Prinzipien konsequent an. Überprüfen Sie Ihre Diagramme regelmäßig. Testen Sie Ihre Übergänge gründlich. Mit Disziplin können Sie die Komplexität beherrschen und stabiles, zuverlässiges Software liefern.