











Backend-Debugging ist oft ein einsamer Kampf gegen eine Wand aus Protokollen. Ingenieure starren auf Terminal-Bildschirme, filtern Textzeilen und versuchen, eine Anfrage zu verfolgen, während sie von Dienst zu Dienst springt. Die Daten sind vorhanden, aber der Kontext fehlt. Hier setzt die visuelle Modellierung ein. Insbesondere bietet das Kommunikationsdiagramm gegenüber Standard-Sequenzdiagrammen einen deutlichen Vorteil bei der Analyse von Systemwechselwirkungen. Es verlagert den Fokus von der zeitbasierten Reihenfolge auf Objektbeziehungen und Verbindungsstrukturen.
Wenn ein System unter Last ausfällt oder unerwartet reagiert, können Textprotokolle überwältigend werden. Ein Kommunikationsdiagramm verdichtet diese Komplexität zu einer Karte von Verbindungen. Es zeigt die Topologie des Ausfalls auf. Dieser Leitfaden untersucht, wie die Nutzung dieser Diagramme den Debugging-Prozess verbessert, die durchschnittliche Zeit bis zur Behebung (MTTR) verringert und eine bessere Teamzusammenarbeit fördert.
🧩 Das Kommunikationsdiagramm verstehen
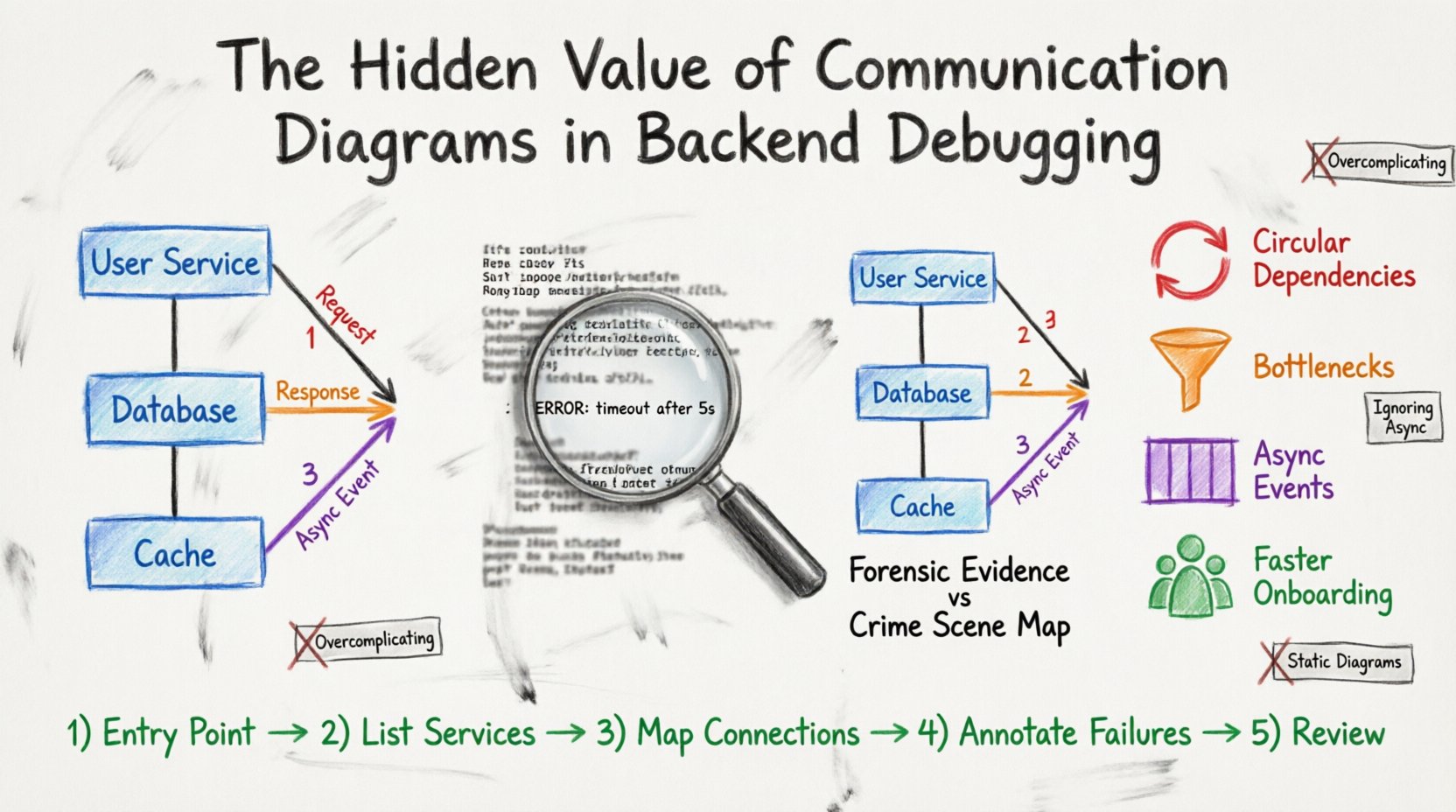
Ein Kommunikationsdiagramm ist eine Art von Unified Modeling Language (UML)-Diagramm. Es zeigt Interaktionen zwischen Objekten oder Systemen, indem es die Verbindungen zwischen ihnen und die Nachrichten, die entlang dieser Verbindungen übermittelt werden, darstellt. Im Gegensatz zu einem Sequenzdiagramm, das die chronologische Reihenfolge der Nachrichten betont, legt ein Kommunikationsdiagramm den Fokus auf die strukturelle Organisation des Systems.
- Objekte:Dargestellt als Felder, handelt es sich um die beteiligten Komponenten (z. B. Benutzerdienst, Datenbank, Cache-Schicht).
- Verbindungen:Linien, die Objekte verbinden und eine physische oder logische Verbindung darstellen.
- Nachrichten:Pfeile, die den Datenfluss anzeigen. Dazu gehören Aktivierungsleisten, um die Verarbeitungsdauer anzuzeigen.
- Reihenfolgennummern:Zahlen auf Pfeilen klären die Reihenfolge der Operationen, ohne eine strenge vertikale Zeitleiste zu erfordern.
Im Backend-Bereich stellen diese Objekte oft Mikrodienste, Datenbank-Instanzen oder Middleware-Komponenten dar. Das Diagramm liefert einen Schnappschuss davon, wie Daten durch die Architektur zu einem bestimmten Zeitpunkt fließen.
🐞 Das Debugging-Dilemma in modernen Backends
Moderne Backend-Architekturen sind selten monolithisch. Sie sind verteilte Systeme, die aus zahlreichen Diensten bestehen. Wenn eine Anfrage fehlschlägt, könnte sie fünf verschiedene Sprünge durchlaufen. Protokolle werden bei jedem Sprung generiert und verteilen sich über verschiedene Container oder Server.
Hier sind die häufigen Probleme, mit denen Ingenieure konfrontiert sind:
- Gestörter Kontext:Protokolle aus Dienst A lassen sich ohne eine eindeutige Korrelations-ID nicht leicht mit Protokollen aus Dienst B verknüpfen.
- Zustandsblindheit:Protokolle zeigen Aktionen, zeigen aber selten den Zustand der Verbindung zum Zeitpunkt des Ausfalls.
- Netzwerkambiguität:Es ist schwierig, Netzwerk-Latenzen oder Timeout-Ketten rein durch Text darzustellen.
- Kognitive Belastung:Der menschliche Geist verarbeitet visuelle Muster schneller als sequenzielle Textströme.
Wenn ein Ingenieur versucht, den Ablauf mental wiederherzustellen, besteht die Gefahr, eine kritische Abhängigkeit zu übersehen. Ein Kommunikationsdiagramm macht dieses mentale Modell sichtbar und ermöglicht es dem Team, den gesamten Interaktionspfad auf einen Blick zu sehen.
🚀 Warum Visualisierungen allein Logs übertrumpfen
Protokolle sind für die Auditierung und die detaillierte Datenüberprüfung unverzichtbar. Sie sind jedoch schlecht darin, Beziehungen zu zeigen. Ein Kommunikationsdiagramm hingegen ist hervorragend darin, Beziehungen darzustellen.
1. Erkennen von zyklischen Abhängigkeiten
In komplexen Systemen hängen Dienste manchmal in einer Schleife voneinander ab. Dienst A ruft Dienst B auf, der wiederum Dienst A aufruft. Protokolle könnten einen Stapelüberlauf oder einen Timeout anzeigen, doch die Ursache ist die Schleife. Ein Diagramm macht diese Schleife sofort sichtbar als geschlossenen Kreis aus Pfeilen.
2. Visualisierung von Engpässen im Datenfluss
Wenn ein bestimmter Link im Diagramm eine hohe Nachrichtenanzahl oder eine lange Dauer aufweist, deutet dies auf einen Engpass hin. Sie können erkennen, welcher Dienst der Engpasspunkt ist, ohne jeden Protokolleintrag einzeln nachzuverfolgen.
3. Klärung asynchroner Ereignisse
Backend-Systeme verwenden häufig Nachrichtenwarteschlangen. Protokolle zeigen eine gesendete und eine empfangene Nachricht, aber die Lücke zwischen ihnen ist unsichtbar. Ein Diagramm kann die Warteschlange als eigenständiges Objekt kennzeichnen und den Übergabepunkt deutlich darstellen.
4. Reduzierung der Einarbeitungszeit für neue Ingenieure
Wenn ein neues Teammitglied an einer Debugging-Sitzung teilnimmt, muss es den Ablauf verstehen. Ein Diagramm zu zeigen ist schneller als, ihnen eine Protokolldatei vorzuführen. Es bietet dem Team ein gemeinsames mentales Modell.
🛠️ Kernkomponenten eines wirksamen Diagramms
Um ein Kommunikationsdiagramm für das Debuggen nutzbar zu machen, muss es bestimmte Elemente enthalten. Verschwommene Skizzen helfen nicht. Präzision ist erforderlich.
- Klare Objektbezeichnungen:Verwenden Sie konsistente Namenskonventionen. Vermeiden Sie „Service 1“. Verwenden Sie stattdessen „Zahlungsgateway“ oder „Bestands-API“.
- Nachrichtentypen:Unterscheiden Sie zwischen synchronen (blockierenden) und asynchronen (Feuer-und-Vergehe) Aufrufen. Verwenden Sie bei Bedarf unterschiedliche Linienstile oder Pfeilspitzen.
- Fehlerzustände:Markieren Sie Fehlerstellen. Wenn an einem bestimmten Link ein Timeout auftritt, notieren Sie dies direkt im Diagramm.
- Schwellenwerte:Geben Sie erwartete gegenüber tatsächlichen Latenzen an. Wenn ein Link normalerweise 50 ms benötigt, aber 5000 ms dauerte, heben Sie diese Abweichung hervor.
- Externe Systeme:Markieren Sie Drittanbieter-APIs oder externe Datenbanken deutlich. Diese sind oft die Ursache für versteckte Probleme.
💡 Praktische Szenarien für die Backend-Debugging
Hier sind spezifische Szenarien, in denen ein Kommunikationsdiagramm während einer Debugging-Sitzung unmittelbaren Nutzen bietet.
Szenario 1: Die Timeout-Kette
Ein Benutzer meldet eine langsame Seitenladezeit. Protokolle zeigen, dass die Frontend-Anwendung wartet, der API-Gateway abläuft und der Backend-Dienst beschäftigt ist. Ein Kommunikationsdiagramm zeigt die Kette auf: Frontend → Gateway → Authentifizierungsdienst → Datenbank. Das Diagramm zeigt, dass der Authentifizierungsdienst auf die Datenbank wartet. Die Visualisierung bestätigt, dass der Datenbank-Verbindungs-Pool erschöpft ist, nicht die Gateway-Konfiguration.
Szenario 2: Dateninkonsistenz
Bestellungen werden aufgegeben, aber der Bestand wird nicht aktualisiert. Protokolle zeigen, dass der Bestellungs-Dienst eine Nachricht gesendet hat. Der Bestands-Dienst hat sie empfangen. Warum wird der Bestand nicht abgezogen? Das Diagramm zeigt einen sekundären Pfad, bei dem der Bestands-Dienst eine Bestätigung an den Bestellungs-Dienst zurücksendet, die jedoch stumm fehlschlägt. Die Visualisierung hebt die fehlende Bestätigungslinie hervor.
Szenario 3: Rennbedingungen
Zwei Benutzer versuchen, die gleiche Ressource zu aktualisieren. Die Protokolle zeigen gleichzeitige Schreibvorgänge. Das Diagramm visualisiert die beiden gleichzeitigen Datenströme, die auf dasselbe Objekt treffen. Es hilft dem Team, über Sperremechanismen oder Strategien zur optimistischen Konkurrenzsteuerung zu diskutieren.
Szenario 4: Abhängigkeitsfehler
Ein Drittanbieter-Zahlungsdienst ist ausgefallen. Der Backend versucht es dreimal erneut. Das Diagramm zeigt die Wiederholungsschleife. Es zeigt, dass die Fehlerbehandlungslogik in einer Schleife gefangen ist und Ressourcen verschwendet. Das Team kann visuell erkennen, dass ein Schaltkreis-Unterbrecher-Muster erforderlich ist.
📝 Erstellen eines Diagramms während eines laufenden Vorfalls
Wenn ein Produktionsvorfall auftritt, ist die Spannung hoch. Ein Diagramm von Grund auf zu zeichnen, dauert Zeit. Es ist jedoch entscheidend, über eine Vorlage oder eine schnelle Methode zu verfügen.
Folgen Sie diesen Schritten, um während einer Debug-Sitzung ein Diagramm zu erstellen:
- Schritt 1: Identifizieren Sie den Einstiegspunkt:Beginnen Sie mit dem Benutzer oder dem auslösenden Ereignis.
- Schritt 2: Aktive Dienste auflisten:Notieren Sie jeden Dienst, der in die aktuelle Anforderung involviert ist.
- Schritt 3: Verbindungen abbilden:Zeichnen Sie Linien zwischen den Diensten basierend darauf, was Sie aus den Protokollen wissen.
- Schritt 4: Fehler markieren:Markieren Sie, wo der Prozess gestoppt hat oder wo Fehler aufgetreten sind.
- Schritt 5: Mit Kollegen besprechen:Fragen Sie andere, ob die Verbindungen mit ihrer Vorstellung des Codes übereinstimmen.
Dieser Prozess erfordert keine komplexe Software. Eine Tafel, ein Notizblock oder ein digitales Skizzierwerkzeug reichen aus. Ziel ist Klarheit, nicht künstlerische Perfektion.
📊 Vergleich: Protokolle vs. Kommunikationsdiagramme
Um das Wertversprechen zu verstehen, vergleichen Sie die beiden Methoden direkt.
| Funktion | Textprotokolle | Kommunikationsdiagramm |
|---|---|---|
| Datengranularität | Hoch (jede Zeile) | Niedrig (abstrahierter Fluss) |
| Zusammenhang | Niedrig (fragmentiert) | Hoch (systemische Sicht) |
| Geschwindigkeit der Analyse | Langsam (Scannen erforderlich) | Schnell (Mustererkennung) |
| Sichtbarkeit von Abhängigkeiten | Versteckt im Text | Explizit (Verbindungen) |
| Zusammenarbeit | Schwer, Kontext zu teilen | Einfach, visuell zu teilen |
| Am besten geeignet für | Tiefgang zur Ursachenanalyse | Verständnis des Flows und Topologie |
Logs liefern die forensischen Beweise. Das Diagramm liefert die Karte des Tatorts. Beides ist für eine vollständige Untersuchung erforderlich.
🚧 Häufige Fehler, die vermieden werden sollten
Selbst mit guten Absichten können Diagramme irreführend werden, wenn sie sorglos erstellt werden.
- Überkomplizierung: Schließen Sie nicht jede einzelne Variable ein. Konzentrieren Sie sich auf den Steuerungs- und Datenfluss zwischen Diensten.
- Ignorieren der Asynchronität: Wenn eine Nachricht in einer Warteschlange steht, zeichnen Sie sie nicht als sofortige Pfeilrichtung. Kennzeichnen Sie sie als Warteschlangen-Interaktion.
- Statisches Denken: Backend-Systeme ändern sich. Ein Diagramm aus sechs Monaten zurück könnte Dienste zeigen, die nicht mehr existieren. Halten Sie Diagramme aktuell.
- Ein-Größe-passt-alle: Verwenden Sie nicht dasselbe Diagramm für eine Übersicht auf hoher Ebene und einen spezifischen Fehler. Erstellen Sie eine detaillierte Version für die Fehlersuche und eine Übersichtsversion für die Architektur.
- Überspringen des Rückwegs: Bei der Fehlersuche geht es oft darum, wie Fehler zurückpropagiert werden. Stellen Sie sicher, dass Antwortpfade gezeichnet werden, nicht nur Anfragepfade.
🔧 Integration in Ihren Arbeitsablauf
Wie machen Sie dies zu einem festen Bestandteil Ihrer Fehlersuchroutine? Dazu ist eine Veränderung des Prozesses notwendig.
1. Planung vor der Analyse (Pre-Mortem)
Bevor eine Bereitstellung erfolgt, skizzieren Sie den erwarteten Kommunikationspfad. Wenn Sie den Fluss kennen, wissen Sie, wo Sie suchen müssen, wenn etwas ausfällt. Das ist proaktive Fehlersuche.
2. Dokumentation nach der Analyse (Post-Mortem)
Nach der Behebung eines Vorfalls aktualisieren Sie das Kommunikationsdiagramm mit dem tatsächlichen Ausfallpfad. Dadurch entsteht ein lebendiges Dokument über den Systemzustand und bekannte Probleme.
3. Paarweise Fehlersuche
Wenn zwei Ingenieure gemeinsam debuggen, sollte einer die Logs lesen, während der andere das Diagramm zeichnet. Dieser zweifache Ansatz stellt sicher, dass das visuelle Modell mit den Rohdaten übereinstimmt.
4. Automatisierte Generierung (falls möglich)
Einige Tracing-Plattformen können Visualisierungen aus Spurdaten generieren. Obwohl manuelle Diagramme mehr Kontrolle bieten, kann die Nutzung automatisierter Spuren als Grundlage für ein Kommunikationsdiagramm Zeit sparen.
📈 Der langfristige Einfluss auf die Team-Effizienz
Die Investition von Zeit in die Erstellung von Kommunikationsdiagrammen zahlt sich im Laufe der Zeit aus. Es schafft institutionelles Wissen.
- Schnelleres Onboarding: Neue Mitarbeiter können die Systemtopologie verstehen, ohne Tausende von Codezeilen lesen zu müssen.
- Bessere Code-Reviews:Reviewer können potenzielle Kommunikationsengpässe erkennen, bevor der Code zusammengeführt wird.
- Geringerer Nacharbeit:Das Verständnis des gesamten Flows verhindert, dass ein Symptom behoben wird, während ein anderes ignoriert wird.
- Verbesserte Incident-Response: Wenn ein System ausfällt, kann das Team schnell den betroffenen Bereich anhand der visuellen Karte identifizieren.
Dieser Ansatz verwandelt das Debugging von einer reaktiven Tätigkeit in eine strukturierte ingenieurwissenschaftliche Praxis. Er verlagert den Fokus von „den Fehler beheben“ hin zu „das System verstehen“.
🎨 Fazit
Das Backend-Debugging ist eine komplexe Aufgabe, die sowohl Tiefgang als auch Breite erfordert. Textprotokolle bieten den Tiefgang, um spezifische Fehler zu verstehen. Kommunikationsdiagramme bieten die Breite, um Systemwechselwirkungen zu verstehen. Durch die Kombination dieser Werkzeuge können Ingenieure komplexe Architekturen mit Vertrauen navigieren.
Es gibt kein einziges Werkzeug, das jedes Problem löst. Dennoch bleibt die visuelle Darstellung des Datenflusses eine der effektivsten Möglichkeiten, technische Probleme zu kommunizieren. Sie schließt die Lücke zwischen abstraktem Code und konkreter Realität. Beginnen Sie mit dem Skizzieren Ihrer nächsten Debugging-Sitzung. Vielleicht finden Sie die Lösung, die sich die ganze Zeit in den Zeilen versteckt hat.
Denken Sie daran, das Ziel ist Klarheit. Egal ob Sie eine Tafel, ein digitales Werkzeug oder Stift und Papier verwenden – die Tätigkeit, den Fluss zu kartieren, zwingt Sie dazu, langsamer zu werden und nachzudenken. Diese Pause ist oft der Moment, in dem der Durchbruch erfolgt.