











Verteilte Systeme verlassen sich stark auf den Informationsfluss zwischen isolierten Komponenten. Beim Aufbau von Microservices geht es nicht nur darum, den Code zu trennen; es geht vielmehr darum, zu orchestrieren, wie Daten über ein Netzwerk fließen. Das Verständnis der Datenflusslogik ist entscheidend, um die Integrität, Leistungsfähigkeit und Zuverlässigkeit eines Systems zu gewährleisten. Ohne eine klare Karte, wo Daten entstehen, wie sie sich verändern und wo sie verbleiben, werden Systeme undurchsichtig und schwer zu debuggen.
Dieser Leitfaden untersucht die Methodik zur Abbildung dieser Flüsse. Wir werden die strukturellen Komponenten, die Logik hinter dem Datenfluss und die Muster betrachten, die die Kommunikation zwischen Diensten steuern. Ziel ist es, eine durchsichtige Architektur zu schaffen, in der jeder Transaktion nachgekommen werden kann.
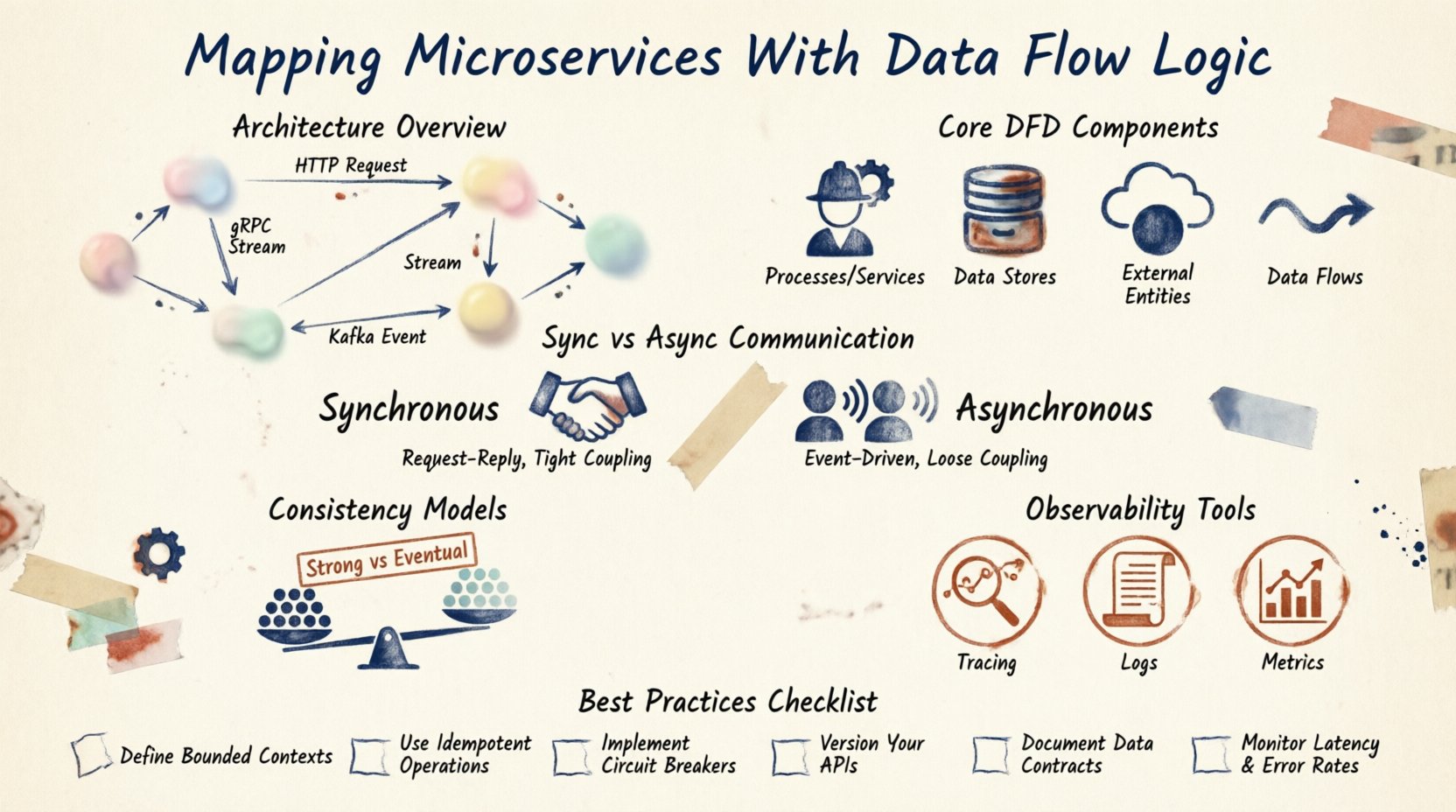
Verständnis der Architektur 🏗️
Die Microservices-Architektur zerlegt eine monolithische Anwendung in kleinere, unabhängige Einheiten. Jede Einheit verarbeitet eine spezifische Geschäftsleistung. Diese Unabhängigkeit bringt jedoch Komplexität hinsichtlich der Zustandsverwaltung und der Kommunikation mit sich. Daten existieren nicht im Vakuum; sie bewegen sich.
Wenn Sie diese Dienste abbilden, zeichnen Sie im Grunde einen Bauplan des Nervensystems des Systems. Sie müssen die Erzeuger von Daten und die Verbraucher identifizieren. Sie müssen die für die Übertragung verwendeten Protokolle verstehen. Kommunizieren die Dienste direkt über HTTP? Verwenden sie eine Nachrichtenwarteschlange? Greifen sie auf eine gemeinsam genutzte Datenbank zu?
Klarheit in diesem Bereich verhindert Kopplung. Wenn Dienst A von Dienst B abhängt, um zu funktionieren, muss diese Abhängigkeit in Ihren Abbildungen explizit sein. Versteckte Abhängigkeiten führen zu kettenartigen Ausfällen. Durch die Visualisierung des Flusses können Sie Engpässe identifizieren, bevor sie die Leistung in der Produktion beeinträchtigen.
Wichtige Treiber für die Abbildung
- Beobachtbarkeit:Sie können nicht debuggen, was Sie nicht sehen können. Eine klare Karte hilft dabei, Anfragen über die verteilte Umgebung hinweg nachzuverfolgen.
- Sicherheit:Das Verständnis des Datenflusses ermöglicht es Ihnen, Verschlüsselung und Zugriffssteuerungen an den richtigen Grenzen anzuwenden.
- Leistung:Die Identifizierung von hochlatenzbehafteten Pfaden hilft dabei, Netzwerkaufrufe und Datenbankabfragen zu optimieren.
- Compliance:Vorschriften verlangen oft, dass man weiß, wo vertrauliche Daten gespeichert sind und wie sie sich bewegen.
Wichtige Komponenten von Datenflussdiagrammen 📊
Ein Datenflussdiagramm (DFD) bietet eine standardisierte Methode zur Darstellung dieser Interaktionen. Im Kontext von Microservices unterscheiden sich die Komponenten leicht von traditionellen DFDs der Softwareentwicklung.
1. Prozesse (Dienste)
Dies sind die aktiven Elemente. Jeder Microservice stellt einen Prozess dar, der Eingabedaten in Ausgabedaten umwandelt. Zum Beispiel empfängt ein Bestell-Dienst Bestelldetails und wandelt sie in eine Lagerreservierung um.
2. Datenbanken
Daten verbleiben nicht immer im Speicher. Sie werden oft in Datenbanken, Caches oder Objektspeichern persistiert. In einer Microservices-Umgebung verfügen Dienste typischerweise über private Datenbanken. Dies gewährleistet eine lose Kopplung. Wenn sich die Datenbank-Schema ändert, muss sich nur der Dienst, der dafür verantwortlich ist, anpassen.
3. Externe Entitäten
Dies sind Akteure außerhalb des Systems. Es könnten ein Drittanbieter-Zahlungsgateway, eine mobile Anwendung oder ein Benutzer sein. Sie initiieren Anfragen oder erhalten Benachrichtigungen. Die Abbildung dieser Grenzen ist entscheidend für die Gestaltung des API-Gateways.
4. Datenflüsse
Dies sind die Pfeile, die die Komponenten verbinden. Sie stellen die Bewegung von Informationen dar. Jeder Fluss sollte eine Beschriftung haben, die die übertragenen Daten beschreibt. Ist es ein JSON-Payload? Ist es eine Binärdatei? Ist es eine Ereignisbenachrichtigung?
Schritt-für-Schritt-Abbildungsmethode 🗺️
Die Erstellung einer Karte ist eine systematische Aufgabe. Sie erfordert die schrittweise Zerlegung des Systems. Hier ist ein logischer Ansatz zur Erstellung dieser Diagramme.
- Grenzen festlegen:Definieren Sie, was innerhalb des Systems und was außerhalb liegt. Damit legen Sie den Umfang Ihres Diagramms fest.
- Dienste auflisten:Listen Sie jeden Microservice auf, der im spezifischen Geschäftsprozess, den Sie analysieren, beteiligt ist.
- Daten-Eingangspunkte definieren: Wo tritt die Daten in das System ein? Ist es ein API-Endpunkt? Ein geplanter Job? Ein Nachrichtenwarteschlangen-Verbraucher?
- Verfolge den Pfad:Verfolge ein einzelnes Datenstück von der Eingabe bis zur Ausgabe. Notiere jeden Dienst, den es berührt.
- Identifiziere die Speicherung:Markiere an jedem Schritt, wo die Daten gelesen oder geschrieben werden.
- Validiere die Logik:Prüfe die Karte mit dem Entwicklerteam, um sicherzustellen, dass sie der tatsächlichen Implementierung entspricht.
Kommunikationsmuster 📡
Wie Dienste miteinander kommunizieren, bestimmt die Flusslogik. Es gibt zwei Hauptmodi: synchron und asynchron.
Synchrones Kommunikation
Dienst A ruft Dienst B auf und wartet auf eine Antwort. Dies wird oft über REST oder gRPC implementiert. Es bietet sofortige Rückmeldung, erzeugt aber enge Kopplung. Wenn Dienst B langsam ist, hängt Dienst A.
Asynchrones Kommunikation
Dienst A sendet eine Nachricht und setzt die Arbeit fort. Dienst B nimmt sie auf, wenn er bereit ist. Hierbei werden Nachrichtenbroker oder Ereignisströme verwendet. Es verbessert die Robustheit, macht das Verfolgen des Zustands aber schwieriger.
| Aspekt | Synchron | Asynchron |
|---|---|---|
| Latenz | Höher (Blockierend) | Niedriger (Nicht blockierend) |
| Kopplung | Eng | Locker |
| Komplexität | Einfach nachzuverfolgen | Erfordert Ereignisquellen |
| Fehlerbehandlung | Sofort erneut versuchen | Tote-Brief-Warteschlangen |
Konsistenzmodelle 🤝
In einem verteilten System ist die Datenkonsistenz eine große Herausforderung. Sie können sich nicht auf eine einzelne Transaktion über mehrere Datenbanken verlassen. Sie müssen sich für ein Konsistenzmodell entscheiden.
Starke Konsistenz
Jeder Lesevorgang erhält die zuletzt geschriebenen Daten. Dies ist schwer zu erreichen, ohne innerhalb von Mikrodiensten zu blockieren. Es erfordert oft verteilte Sperrmechanismen.
Eventuelle Konsistenz
Daten werden nach einer gewissen Zeit konsistent sein. Aktualisierungen werden asynchron propagiert. Dies ist die Norm für die meisten Mikrodienste. Es ermöglicht eine hohe Verfügbarkeit, erfordert jedoch, dass die Anwendung temporäre Dateninkonsistenzen behandelt.
Beobachtbarkeit und Tracing 🔍
Sobald die Karte gezeichnet ist, benötigen Sie Werkzeuge, um sie zu überwachen. Verteiltes Tracing ermöglicht es Ihnen, eine Anforderungs-ID durch jeden Dienst zu verfolgen. Dies ist entscheidend für das Debuggen.
Logs sollten korreliert werden. Wenn eine Anforderung fehlschlägt, müssen die Logs aus dem Gateway, dem Bestell-Service und dem Zahlungs-Service miteinander verknüpft sein. Diese Verknüpfung ist das digitale Abbild Ihres Datenflussdiagramms.
Metriken sind ebenfalls Teil des Flusses. Sie sollten das Volumen der Nachrichten, die Latenz der Aufrufe und die Fehlerquoten verfolgen. Diese Metriken validieren die Gesundheit der von Ihnen entworfenen Datenpfade.
Best Practices für die Wartung 🛠️
Eine Diagramm ist nur dann nützlich, wenn es aktuell bleibt. Systeme entwickeln sich weiter, und die Karte muss sich mit ihnen weiterentwickeln.
- Generierung automatisieren: Wo immer möglich, sollten Diagramme aus dem Code oder als Infrastruktur als Code generiert werden. Dadurch werden manuelle Fehler reduziert.
- Versionskontrolle: Speichern Sie Ihre Diagramme im selben Repository wie Ihren Code. Überprüfen Sie sie während Pull Requests.
- Regelmäßige Audits: Planen Sie vierteljährliche Überprüfungen, um sicherzustellen, dass die Karte dem laufenden System entspricht.
- Protokolle dokumentieren: Definieren Sie die Datenformate klar. Verwenden Sie Schemata, um die Struktur über alle Dienste hinweg durchzusetzen.
Herausforderungen bei verteilten Flüssen ⚠️
Das Abbilden dieser Systeme ist nicht ohne Schwierigkeiten. Netze fallen aus. Dienste werden neu gestartet. Daten gehen verloren.
Netzwerk-Latenz:Der physische Abstand zwischen Diensten kann die Leistung beeinflussen. Sie müssen dies in Ihrer Zeitlogik berücksichtigen.
Datenfragmentierung:Daten sind über viele Speicher verteilt. Um ein vollständiges Bild einer Entität zu rekonstruieren, ist die Zusammenführung von Daten aus verschiedenen Quellen erforderlich. Dies erhöht die Komplexität der Abfragen.
Orchestrierung versus Choreografie: Sie müssen entscheiden, wer den Fluss steuert. Die Orchestrierung verwendet einen zentralen Koordinator. Die Choreografie stützt sich auf Ereignisse. Beide haben Kompromisse hinsichtlich Sichtbarkeit und Kontrolle.
Zukunftssicherung des Designs 🔮
Technologie ändert sich. Protokolle entwickeln sich weiter. Ihre Karte sollte abstrakt genug sein, um diesen Veränderungen standzuhalten.
Konzentrieren Sie sich auf die Geschäftslogik und nicht auf die Implementierungsdetails. Beschreiben Sie, was die Daten bedeuten, nicht nur, wie sie codiert sind. Diese Abstraktion ermöglicht es Ihnen, die zugrundeliegenden Technologien zu wechseln, ohne die gesamte Architektur neu schreiben zu müssen.
Berücksichtigen Sie Skalierbarkeit. Kann der Fluss zehnmal mehr Last bewältigen? Zeigt die Karte, wo Engpässe auftreten könnten? Gestalten Sie von Anfang an für Wachstum.
Abschließende Gedanken zur Datenlogik
Das Abbilden von Mikrodiensten mit Datenflusslogik ist eine grundlegende Fähigkeit für Architekten. Es verlegt das Gespräch von abstraktem Code zu konkretem Fluss. Durch die Visualisierung des Flusses können Teams bessere Entscheidungen bezüglich Resilienz, Sicherheit und Leistung treffen.
Es erfordert Disziplin, die Karten aktuell zu halten. Es erfordert Zusammenarbeit, um sicherzustellen, dass alle die Wege verstehen. Doch das Ergebnis ist ein System, das einfacher zu bauen, einfacher zu debuggen und einfacher zu skalieren ist. Die Daten fließen klar, und das System bleibt unter Druck stabil.
Investieren Sie die Zeit in diese Diagramme. Sie dienen als Dokumentation für das Lebensblut Ihres Systems. Wenn die Lichter auf einem Produktionsserver ausgehen, sind dies die Karten, die die Wiederherstellung leiten.