








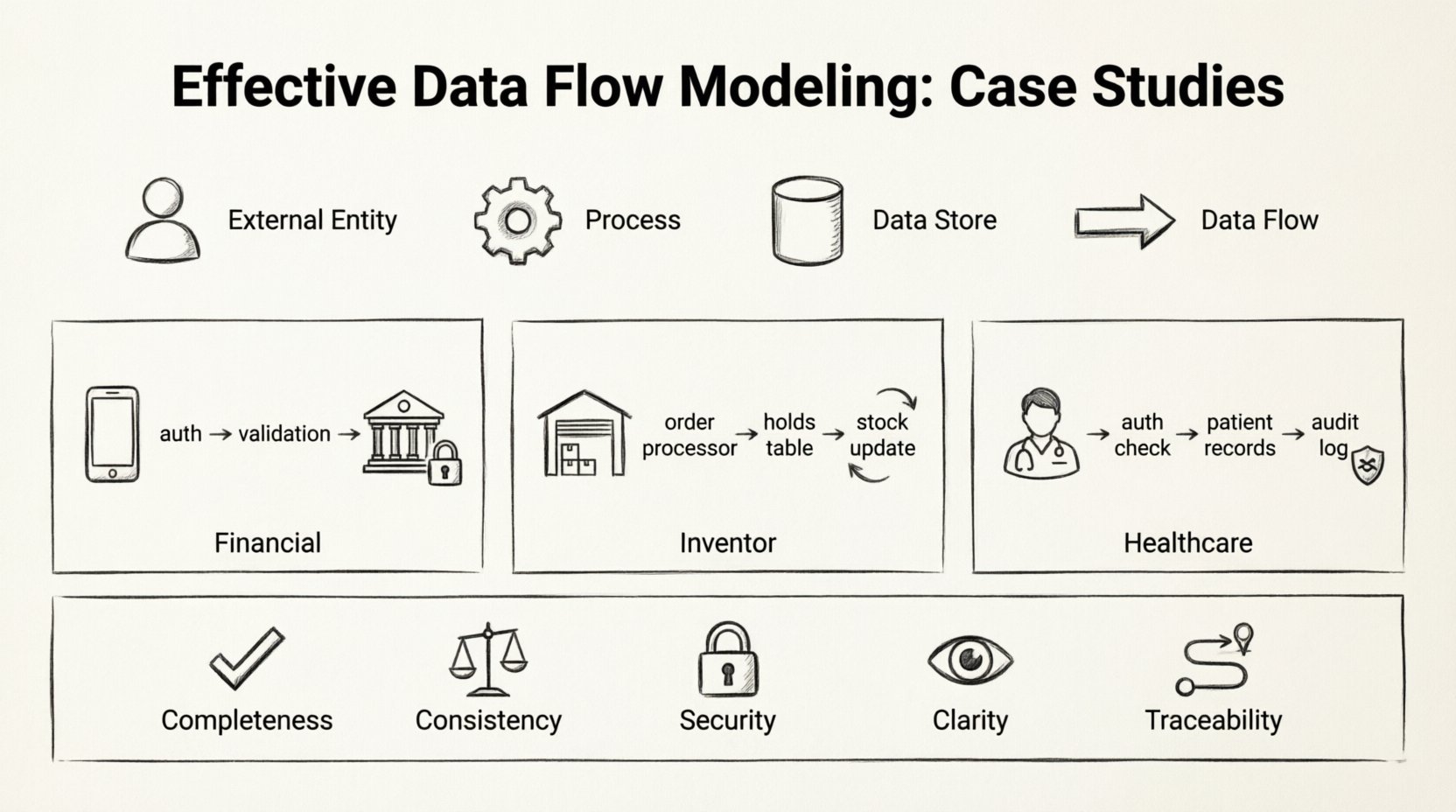
Datenflussdiagramme (DFDs) dienen als Bauplan für Informationssysteme. Sie zeigen die Bewegung von Daten zwischen Prozessen, Datenspeichern, externen Entitäten und den Daten selbst. Ein gut gestaltetes Diagramm zeigt nicht nur, wohin Daten fließen, sondern offenbart auch die Logik, Integrität und Sicherheit der Systemarchitektur. In diesem Artikel werden drei unterschiedliche Szenarien untersucht, um zu veranschaulichen, wie ein strenges Modellieren zu stabilen, wartbaren Systemen führt.
🗺️ Verständnis der Kernkomponenten
Bevor man sich spezifischen Implementierungen zuwendet, ist es unerlässlich, die Standardelemente zu definieren, die in jedem Datenflussmodell beteiligt sind. Diese Komponenten bleiben unabhängig von der Branche oder der Komplexität des Systems konstant.
- Externe Entitäten:Quellen oder Ziele von Daten außerhalb der Systemgrenze. Dazu können Benutzer, andere Systeme oder Aufsichtsbehörden gehören.
- Prozesse:Transformationen, die Eingabedaten in Ausgabedaten umwandeln. Jeder Prozess muss mindestens eine Eingabe und eine Ausgabe haben.
- Datenspeicher:Orte, an denen Daten für spätere Verwendung gespeichert werden. Dazu gehören Datenbanken, Dateisysteme oder physische Archive.
- Datenflüsse:Die Pfeile, die die Komponenten verbinden und die Richtung sowie den Inhalt der Datenbewegung anzeigen.
Die Genauigkeit bei der Darstellung dieser Elemente ist entscheidend. Eine falsche Kennzeichnung eines Datenspeichers als Prozess beispielsweise kann zu Verwirrung darüber führen, wo Daten gespeichert werden und wo sie transformiert werden.
🏦 Fallstudie 1: Verarbeitung von Finanztransaktionen
Die Finanzbranche verlangt hohe Genauigkeit hinsichtlich Datenintegrität und Sicherheit. In diesem Szenario untersuchen wir ein System, das Zahlungsanfragen von einer mobilen Anwendung an ein Bankkernsystem verarbeitet.
🔍 Systemkontext
Das primäre Ziel besteht darin sicherzustellen, dass Geld nur dann übertragen wird, wenn bestimmte Bedingungen erfüllt sind. Das System muss die Verfügbarkeit von Mitteln prüfen, die Identität des Benutzers bestätigen und die Transaktion zur Prüfung protokollieren.
🔄 Datenfluss-Aufschlüsselung
Der Modellierungsprozess begann mit einem Level-0-Diagramm, das einen Überblick über das System bietet. Dabei zeigten sich drei Hauptprozesse:Authentifizierung, Validierung:, undBuchung.
- Authentifizierung:Wenn ein Benutzer eine Überweisung startet, werden ihre Zugangsdaten an den Sicherheitsdienst gesendet. Das System prüft den Status des Benutzers anhand desAktive BenutzerDatenspeichers.
- Validierung: Sobald die Authentifizierung abgeschlossen ist, wird die Anforderung dem Überprüfungsprozess zugeführt. Hier prüft das System die KontoständeSpeicher, um ausreichende Mittel zu gewährleisten. Außerdem überprüft es die TransaktionsgrenzenTabelle.
- Buchung: Wenn die Überprüfung erfolgreich ist, wird die Transaktion im TransaktionsprotokollDatenbank gespeichert. Die Kontoständewerden aktualisiert, und ein Bestätigungs-Signal wird an den Benutzer zurückgesendet.
Eine entscheidende Entscheidung in diesem Modell war die Trennung der Überprüfung und BuchungProzesse. Die Zusammenführung würde einen einzigen Fehlerpunkt erzeugen. Durch die Trennung können die Prozesse unabhängig voneinander behandelt werden, sodass das System den Überprüfungsstatus zurücksetzen kann, ohne das dauerhafte Protokoll zu beschädigen, falls ein Netzwerkunterbrechung auftritt.
📊 Komponenten-Zuordnung
| Komponente | Typ | Rolle im System |
|---|---|---|
| Mobile App | Externe Entität | Initiiert die Anforderung und empfängt die Bestätigung. |
| Sicherheitsdienst | Prozess | Überprüft die Anmeldeinformationen anhand des gespeicherten Hash-Werts. |
| Kontostände | Datenbank | Liest die aktuellen Mittel und schreibt die neuen Gesamtbeträge. |
| Transaktionsprotokoll | Datenbank | Unveränderlicher Protokoll aller Bewegungen. |
📦 Fallstudie 2: Bestandsverwaltungssystem
Bestandssysteme erfordern eine Synchronisierung über mehrere Standorte. Die Herausforderung besteht nicht nur darin, Daten zu bewegen, sondern sicherzustellen, dass die Darstellung des physischen Bestands in Echtzeit mit der digitalen Aufzeichnung übereinstimmt.
🔍 Systemkontext
Dieses System verbindet einen Lagerverwaltungs-Terminal mit einem Online-Verkaufsportal. Die Datenflüsse sind bidirektional: Verkäufe verringern den Bestand, eingehende Lieferungen erhöhen ihn. Das Modell muss Konkurrenzbehandlung unterstützen, um Überverkäufe zu verhindern.
🔄 Datenfluss-Aufschlüsselung
Das Level-1-Diagramm zeigte ein komplexes Netzwerk von Interaktionen, die beteiligt sindAuftragsverarbeiter und der Bestandskontroller.
Wenn ein Auftrag platziert wird:
- Der Auftragsverarbeiter prüft die Bestandsdatenbank.
- Wenn Bestand verfügbar ist, wird ein Reservierungs-Token erstellt und in einer temporären Holds-Tabelle.
- Der Auftrag wird dem Kunden bestätigt.
- Ein separater Prozess, Bestandsabstimmung, läuft periodisch, um abgelaufene Reservierungen zu löschen und die Bestandsdatenbank.
Dieser Ansatz verhindert, dass das System die gesamte Datenbank bei jedem Klick sperren muss. Die Verwendung einer temporären Sperrtabelle ermöglicht es dem System, Konkurrenzsituationen zu verwalten, ohne dass andere Benutzer daran gehindert werden, Bestandsstände einzusehen.
📊 Parallelverarbeitung
| Szenario | Datenflussaktion | Ergebnis |
|---|---|---|
| Einzelner Benutzer | Bestand prüfen → Reservieren → Bestätigen | Erfolg |
| Zwei Benutzer (dieselbe Artikelnummer) | Benutzer A reserviert → Benutzer B prüft (Bestand niedrig) | Benutzer B sieht den aktualisierten Bestand |
| Reservierungszeitüberschreitung | Sperrtabelle → Bereinigungsprozess | Bestand wird zurück in den Pool gegeben |
Das Modell hebt die Bedeutung der Bereinigungsprozess. Ohne dies würde die Sperrtabelle unendlich wachsen, Speicher verbrauchen und Abfragen verlangsamen.
🏥 Fallstudie 3: Gesundheitspatientenakten
Bei der Modellierung von Gesundheitsdaten hat die Privatsphäre und der Zugriffsschutz oberste Priorität. Der Informationsfluss muss streng nach der Rolle des Benutzers und der Sensibilität der Daten reguliert werden.
🔍 Systemkontext
Dieses System verwaltet die Patientenverläufe für ein Netzwerk von Kliniken. Die Daten umfassen personenbezogene Identifikation, medizinische Vorgeschichte und Laborergebnisse. Das Modell muss sicherstellen, dass nur autorisiertes Personal bestimmte Akten einsehen kann.
🔄 Datenflussanalyse
Der DFD für dieses System führt das Konzept von Zugriffskontrolle als eigenständige Prozessschicht ein. Die Daten fließen nicht direkt von der Patientenakte auf den Bildschirm des Arztes.
- Anfrage: Der Arzt wählt eine Patienten-ID aus.
- Autorisierung: Das System prüft die Benutzerberechtigungen Speicher, um festzustellen, ob der Arzt Zugriff auf die Daten dieser spezifischen Klinik hat.
- Abruf: Wenn autorisiert, holt die Abfrage-Engine Daten aus dem Patientenakten Speicher ab.
- Protokollierung: Eine Aufzeichnung des Zugriffsereignisses wird in das Audit-Protokoll geschrieben, bevor die Daten angezeigt werden.
Diese Trennung stellt sicher, dass selbst wenn der Datenspeicher kompromittiert wird, die Zugriffsprotokolle eine Spur davon liefern, wer welche Daten angefordert hat. Das Audit-Protokoll ist in diesem Modell ein kritischer Datenspeicher, der oft mit höherer Sicherheitsfreigabe behandelt wird als die medizinischen Aufzeichnungen selbst.
📊 Datenschutzebenen
| Rolle | Datenzugriff | Datenflusspfad |
|---|---|---|
| Rezeptionist | Nur Terminplanung | Terminspeicher → Anzeige |
| Pflegefachkraft | Lebenszeichen & Medikamente | Medizinischer Speicher → Authentifizierung überprüfen → Anzeige |
| Spezialist | Vollständige Geschichte | Medizinischer Speicher → Authentifizierung überprüfen → Anzeige |
Das Diagramm unterscheidet deutlich zwischen den Rezeptionist und den SpezialistWegen. Obwohl beide auf einen Patienten zugreifen, werden die Datenströme unterschiedlich gefiltert. Diese Feinheit ist für die Einhaltung der Datenschutzvorschriften unerlässlich.
🛠️ Methodik für eine effektive Modellierung
Eine erfolgreiche Modellierung erfordert einen disziplinierten Ansatz. Es geht nicht nur darum, Kästchen und Pfeile zu zeichnen; vielmehr geht es darum, die Geschäftslogik zu verstehen und sie in eine technische Darstellung zu übersetzen.
1. Definieren Sie den Umfang eindeutig
Beginnen Sie damit, die Grenzen des Systems zu bestimmen. Was ist intern und was extern? In der Finanz-Fallstudie war der Bankenkern eine externe Entität für die Mobile-App-Ebene. Die Klärung dieses Punktes verhindert Scope Creep während der Entwicklung.
2. Zerlegen Sie schrittweise
Beginnen Sie mit einem hochwertigen Kontextdiagramm. Erweitern Sie dann jeden Prozess in ein Level-1-Diagramm. Fahren Sie fort, bis die Prozesse einfach genug sind, um direkt zu codieren. Dieser hierarchische Ansatz hält das Modell lesbar.
3. Überprüfen Sie die Datenbanken
Jeder Datenbestand muss einen klaren Zweck haben. Fragen Sie: Warum wird diese Daten gespeichert? Wird sie für einen zukünftigen Prozess benötigt? Wenn ein Datenbestand keine eingehenden oder ausgehenden Ströme hat, ist er nutzlos. In der Lagerfallstudie war die Holds-Tabelledurch die Notwendigkeit der Konkurrenzsteuerung gerechtfertigt.
4. Überprüfen Sie auf Konsistenz
Stellen Sie sicher, dass die Daten, die in einen Prozess eintreten, mit den Daten übereinstimmen, die der nächste Prozess erwartet. Falsche Formate oder fehlende Felder sind häufige Ursachen für Systemfehler. Konsistenzprüfungen sollten innerhalb der Datenflussetiketten dokumentiert werden.
🔄 Wartung und Evolution
Systeme entwickeln sich weiter, und die Datenflussmodelle müssen sich mit ihnen entwickeln. Ein statisches Diagramm wird bereits dann obsolet, wenn sich die Geschäftsanforderungen ändern.
Beim Einführen einer neuen Funktion sollten die neuen Datenströme mit dem bestehenden Diagramm abgeglichen werden. Suchen Sie nach Konflikten. Zum Beispiel könnte die Hinzufügung einer Benachrichtigungsfunktion zum Finanzsystem einen neuen Prozess zur Verwaltung der E-Mail-Versendung und eine neue Datenbank für Nachrichtenvorlagen erfordern.
Regelmäßige Audits des DFD werden empfohlen. Vergleichen Sie die tatsächlichen Systemprotokolle mit den geplanten Datenströmen. Abweichungen deuten entweder auf eine Abweichung in der Implementierung oder auf ein veraltetes Modell hin. Die Aktualisierung des Modells stellt sicher, dass neue Entwickler die Architektur verstehen können, ohne den Code rückwärts zu analysieren.
📋 Zusammenfassung der wichtigsten Überlegungen
Die folgende Prüfliste stellt sicher, dass Datenflussmodelle während des gesamten Projektzyklus wirksam und genau bleiben.
- Vollständigkeit: Hat jeder Prozess Eingaben und Ausgaben?
- Konsistenz: Stimmen die Datenströme in Format und Typ über alle Prozesse hinweg überein?
- Sicherheit: Werden sensible Datenströme durch Autorisierungsprozesse geschützt?
- Klarheit:Sind die Beschriftungen beschreibend und eindeutig?
- Nachverfolgbarkeit:Kann jeder Datenbestand zurückverfolgt werden zu seiner Quelle und seinem Ziel?
Durch die Einhaltung dieser Prinzipien können Organisationen Systeme aufbauen, die robust, sicher und leicht wartbar sind. Die Investition in detailliertes Modellieren bringt während der Test- und Bereitstellungsphasen Erträge, wodurch die Wahrscheinlichkeit kritischer Ausfälle sinkt.
Die Datenflussmodellierung ist eine Grundfertigkeit für Systemarchitekten. Sie schließt die Lücke zwischen abstrakten Anforderungen und konkreter Umsetzung. Unabhängig davon, ob Finanztransaktionen, Lagerbestände oder Patientenakten verwaltet werden, bleibt die Logik gleich: Daten müssen präzise erfasst, transformiert, gespeichert und abgerufen werden. Die Muster, die in diesen Fallstudien etabliert wurden, bieten einen zuverlässigen Rahmen für die Gestaltung komplexer Informationssysteme.
🚀 Letzte Gedanken zur Architektur
Die Qualität eines Systems wird oft bestimmt, bevor eine einzige Codezeile geschrieben wurde. Die Diagramme, die in der Planungsphase erstellt werden, bestimmen die Leistungsfähigkeit und Zuverlässigkeit des Endprodukts. Indem Architekten sich auf die Bewegung von Daten konzentrieren, anstatt nur auf die Speicherung, können sie Engpässe und Sicherheitslücken frühzeitig erkennen.
Denken Sie daran, dass ein Modell ebenso ein Kommunikationsinstrument wie eine technische Spezifikation ist. Es ermöglicht den Beteiligten, das Verhalten des Systems zu visualisieren. Wenn das Diagramm klar ist, folgt der Code natürlich. Wenn das Diagramm unklar ist, wird der Code zu einem Wartungs-Alptraum.
Wenden Sie diese Prinzipien auf Ihr nächstes Projekt an. Beginnen Sie mit dem Kontext, zerlegen Sie die Prozesse und überprüfen Sie die Datenbanken. Ein disziplinierter Ansatz zur Datenflussmodellierung ist das Kennzeichen einer reifen Ingenieurpraxis.