








Диаграммы потоков данных (DFD) служат чертежом информационных систем. Они отображают перемещение данных между процессами, хранилищами данных, внешними сущностями и самими данными. Хорошо построенная диаграмма делает больше, чем просто показывает, куда идут данные; она раскрывает логику, целостность и безопасность архитектуры системы. В этой статье рассматриваются три разных сценария, чтобы проиллюстрировать, как строгое моделирование приводит к стабильным и поддерживаемым системам.
🗺️ Понимание основных компонентов
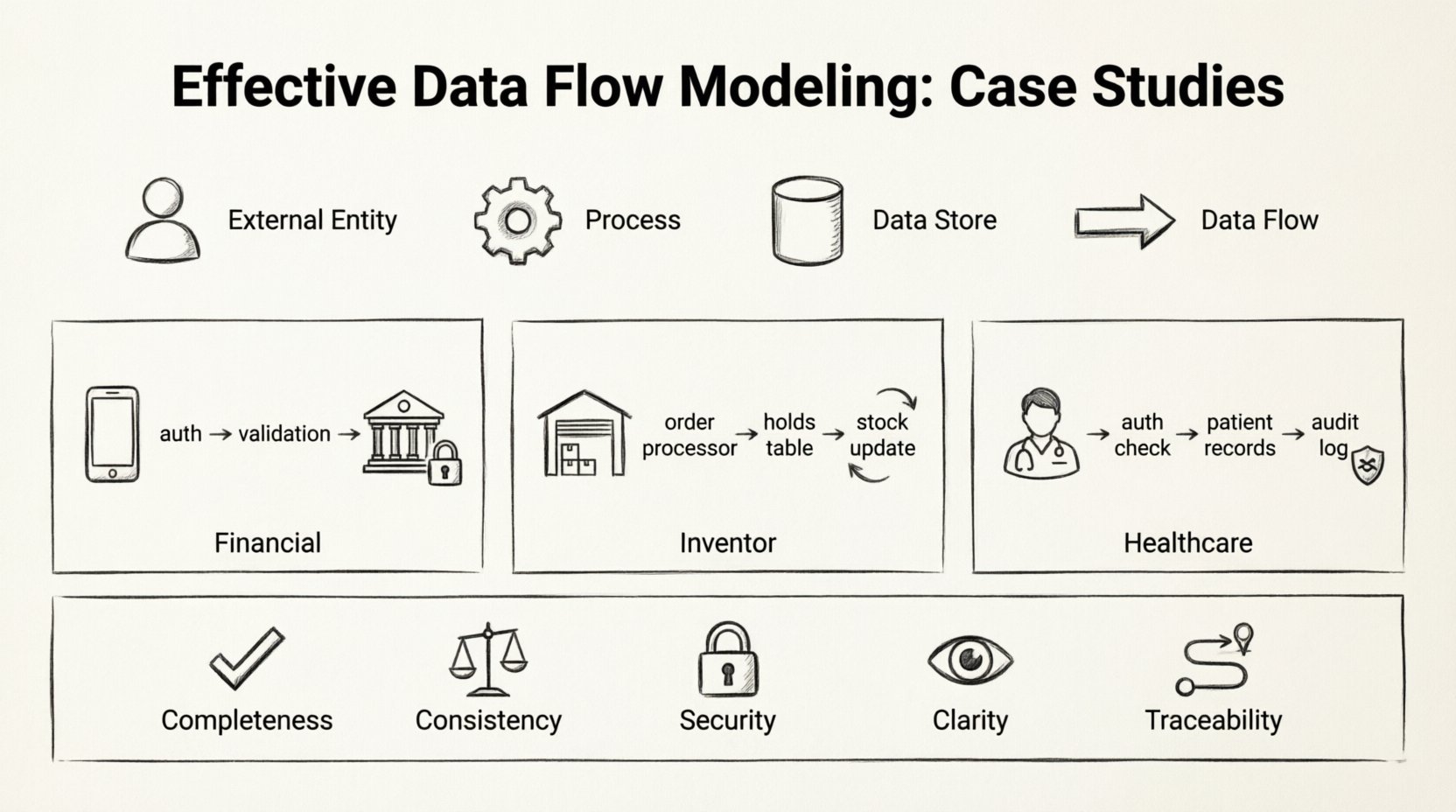
Прежде чем приступать к конкретным реализациям, необходимо определить стандартные элементы, участвующие в любой модели потока данных. Эти компоненты остаются неизменными независимо от отрасли или сложности системы.
- Внешние сущности:Источники или пункты назначения данных за пределами границ системы. К ним могут относиться пользователи, другие системы или регулирующие органы.
- Процессы:Преобразования, превращающие входные данные в выходные. Каждый процесс должен иметь хотя бы один вход и один выход.
- Хранилища данных:Места, где хранятся данные для последующего использования. К ним относятся базы данных, файловые системы или физические архивы.
- Потоки данных:Стрелки, соединяющие компоненты, указывающие направление и содержание перемещения данных.
Точность отображения этих элементов имеет критическое значение. Например, неправильная метка хранилища данных как процесса может привести к путанице относительно того, где данные сохраняются, а где преобразуются.
🏦 Исследование случая 1: Обработка финансовых транзакций
Финансовый сектор требует высокой точности в отношении целостности и безопасности данных. В этом сценарии мы рассматриваем систему, предназначенную для обработки запросов на платежи от мобильного приложения до банковского ядра.
🔍 Контекст системы
Основная цель — обеспечить, чтобы деньги перемещались только при выполнении определённых условий. Система должна проверять наличие средств, подтверждать личность пользователя и фиксировать транзакцию для аудита.
🔄 Разбор потоков данных
Процесс моделирования начался с диаграммы уровня 0, предоставляющей общий обзор системы. Было выявлено три основных процесса:Аутентификация, Проверка:, иЗапись.
- Аутентификация:Когда пользователь инициирует перевод, его учетные данные отправляются в службу безопасности. Система проверяет статус пользователя по сравнению сАктивные пользователихранилищем данных.
- Проверка: После аутентификации запрос переходит к процессу проверки. Здесь система проверяет Сальдо счетов хранилище, чтобы убедиться в наличии достаточных средств. Также проверяется Ограничения транзакций таблица.
- Запись: Если проверка пройдена, транзакция записывается в Журнал транзакций хранилище данных. Состояние Сальдо счетов обновляется, и подтверждение отправляется обратно пользователю.
Критическое решение в этой модели — разделение процессов Проверки и Записи процессов. Объединение их создало бы единую точку отказа. Сохраняя их раздельными, система может откатить состояние проверки без повреждения постоянного журнала при возникновении сетевого сбоя.
📊 Сопоставление компонентов
| Компонент | Тип | Роль в системе |
|---|---|---|
| Мобильное приложение | Внешняя сущность | Инициирует запрос и получает подтверждение. |
| Служба безопасности | Процесс | Проверяет учетные данные по хэшу, хранящемуся в системе. |
| Сальдо счетов | Хранилище данных | Читает текущие средства и записывает новые итоги. |
| Журнал транзакций | Хранилище данных | Неизменяемая запись всех перемещений. |
📦 Кейс 2: Система управления запасами
Системы учета запасов требуют синхронизации между несколькими местоположениями. Проблема здесь заключается не только в перемещении данных, но и в обеспечении того, чтобы отображение реального количества товара соответствовало цифровой записи в режиме реального времени.
🔍 Контекст системы
Эта система соединяет терминал управления складом с онлайн-порталом продаж. Данные передаются в обоих направлениях: продажи уменьшают запасы, а поступающие поставки увеличивают их. Модель должна управлять одновременным доступом, чтобы избежать перепродажи.
🔄 Разбор потока данных
Диаграмма уровня 1 показала сложную сеть взаимодействий, включающихОбработчик заказов и Контроллер запасов.
Когда заказ помещается:
- Обработчик заказовОбработчик заказов проверяет Базы данных учета запасов.
- Если запасы доступны, создается Токен резервирования и сохраняется во временной Таблице резервирования.
- Заказ подтверждается клиенту.
- Отдельный процесс, Сверка запасов, выполняется периодически для очистки устаревших резервирований и обновления Базы данных учета запасов.
Этот подход предотвращает блокировку всей базы данных при каждом клике. Использование временнойТаблица удержаний позволяет системе управлять конкуренцией без блокировки других пользователей при просмотре уровней запасов.
📊 Обработка параллелизма
| Сценарий | Действие потока данных | Результат |
|---|---|---|
| Один пользователь | Проверить наличие → Забронировать → Подтвердить | Успех |
| Два пользователя (один и тот же товар) | Пользователь А бронирует → Пользователь Б проверяет (низкий остаток) | Пользователь Б видит обновленное количество |
| Тайм-аут бронирования | Таблица удержаний → Процесс очистки | Запас возвращен в пул |
Модель подчеркивает важность Процесс очистки. Без этого Таблица удержаний будет расти неограниченно, потребляя память и замедляя запросы.
🏥 Кейс 3: Медицинские записи пациентов
Моделирование медицинских данных ставит во главу угла конфиденциальность и контроль доступа. Поток информации должен строго регулироваться в зависимости от роли пользователя и чувствительности данных.
🔍 Контекст системы
Эта система управляет историей пациентов для сети клиник. Данные включают личную идентификацию, медицинскую историю и результаты лабораторных исследований. Модель должна обеспечивать, чтобы только уполномоченный персонал мог просматривать определенные записи.
🔄 Разбор потока данных
DFD для этой системы вводит концепцию Контроль доступа как отдельный слой процессов. Данные не поступают напрямую из записи пациента на экран врача.
- Запрос: Врач выбирает идентификатор пациента.
- Авторизация: Система проверяет Разрешения пользователя хранилище, чтобы убедиться, что врач имеет доступ к данным конкретной клиники.
- Извлечение: Если авторизовано, то Движок запросов извлекает данные из Хранилище медицинских записей хранилища.
- Ведение журнала: Запись о событии доступа записывается в Журнал аудита до отображения данных.
Это разделение обеспечивает, что даже если хранилище данных будет скомпрометировано, журналы доступа предоставляют следующую информацию о том, кто запрашивал какие данные. Журнал аудита Журнал аудита является критически важным хранилищем данных в этой модели, зачастую с более высоким уровнем безопасности, чем сами медицинские записи.
📊 Уровни конфиденциальности
| Роль | Доступ к данным | Путь передачи данных |
|---|---|---|
| Регистратор | Только расписание | Хранилище расписания → Отображение |
| Медсестра | Показатели жизнедеятельности и лекарства | Хранилище медицинских данных → Проверка авторизации → Отображение |
| Специалист | Полная история | Хранилище медицинских данных → Проверка авторизации → Отображение |
На диаграмме четко различаются Регистратор и Специалист пути. Несмотря на то, что оба они получают доступ к пациенту, потоки данных фильтруются по-разному. Такая детализация необходима для соблюдения требований по защите данных.
🛠️ Методология эффективного моделирования
Успешное моделирование требует дисциплинированного подхода. Речь идет не просто о рисовании прямоугольников и стрелок; важно понимать бизнес-логику и переводить ее в техническое представление.
1. Четко определите границы модели
Начните с определения границ системы. Что является внутренним, а что внешним? В исследовании финансовой системы ядра банковской системы считались внешними объектами по отношению к слою мобильного приложения. Уточнение этого момента предотвращает расширение границ системы во время разработки.
2. Постепенно декомпозируйте
Начните с диаграммы контекста высокого уровня. Затем расширьте каждый процесс до диаграммы уровня 1. Продолжайте декомпозицию до тех пор, пока процессы не станут достаточно простыми для прямой кодировки. Такой иерархический подход сохраняет читаемость модели.
3. Проверьте хранилища данных
Каждое хранилище данных должно иметь четкую цель. Задайте себе вопрос: зачем сохраняется эта информация? Нужна ли она для будущего процесса? Если хранилище данных не имеет входящих или исходящих потоков, оно является бессмысленной нагрузкой. В случае с инвентарем таблица хранения была оправдана необходимостью контроля параллелизма.
4. Проверьте согласованность
Убедитесь, что данные, поступающие в процесс, соответствуют тем, которые ожидаются следующим процессом. Несоответствие форматов или отсутствие полей — распространенные причины сбоев в системе. Проверки согласованности должны быть зафиксированы в метках потоков данных.
🔄 Обслуживание и эволюция
Системы развиваются, и модели потоков данных должны развиваться вместе с ними. Статическая диаграмма становится устаревшей уже при изменении бизнес-требований.
При внедрении новой функции сопоставьте новые потоки данных с существующей диаграммой. Ищите конфликты. Например, добавление функции уведомлений в финансовую систему может потребовать нового процесса для обработки доставки электронной почты и нового хранилища данных для шаблонов сообщений.
Рекомендуется регулярно проводить аудит диаграмм потоков данных. Сравните фактические журналы системы с запланированными потоками данных. Расхождения указывают либо на отклонение в реализации, либо на устаревшую модель. Обновление модели обеспечивает, что новые разработчики смогут понять архитектуру без необходимости обратного инжиниринга кода.
📋 Обобщение ключевых аспектов
Следующий чек-лист гарантирует, что модели потоков данных остаются эффективными и точными на протяжении всего жизненного цикла проекта.
- Полнота: Каждый процесс имеет входные и выходные данные?
- Согласованность: Соответствуют ли потоки данных по формату и типу между процессами?
- Безопасность: Защищены ли чувствительные потоки данных процессами авторизации?
- Четкость: Являются ли метки описательными и однозначными?
- Следуемость:Можно ли отследить каждый фрагмент данных до его источника и назначения?
Соблюдая эти принципы, организации могут создавать системы, которые устойчивы, защищены и легко поддаются обслуживанию. Вложения в детальное моделирование окупаются на этапах тестирования и развертывания, снижая вероятность критических сбоев.
Моделирование потоков данных — это фундаментальный навык для архитекторов систем. Оно устраняет разрыв между абстрактными требованиями и конкретной реализацией. Независимо от того, управляете ли вы финансовыми операциями, уровнями запасов или медицинскими записями, логика остается неизменной: данные должны быть захвачены, преобразованы, сохранены и извлечены с высокой точностью. Следование шаблонам, установленным в этих кейсах, обеспечивает надежную основу для проектирования сложных информационных систем.
🚀 Заключительные мысли об архитектуре
Качество системы часто определяется еще до написания первого строки кода. Диаграммы, созданные на этапе планирования, определяют производительность и надежность конечного продукта. Сосредоточившись на перемещении данных, а не только на их хранении, архитекторы могут выявить узкие места и уязвимости безопасности на ранних этапах.
Помните, что модель — это не только техническое описание, но и инструмент коммуникации. Она позволяет заинтересованным сторонам визуализировать поведение системы. Когда диаграмма понятна, код следует логично. Когда диаграмма неясна, код превращается в кошмар обслуживания.
Примените эти принципы к вашему следующему проекту. Начните с контекста, разбейте процессы и проверьте хранилища данных. Дисциплинированный подход к моделированию потоков данных — признак зрелой инженерной практики.