











数据流图(通常简称为DFD)是系统分析与设计中的基础工具。它们以可视化的方式展示信息在系统中的流动过程。与关注控制逻辑或硬件的其他图表不同,DFD特别强调数据本身的流动。这种方法有助于利益相关者理解数据从输入到输出的转换过程,而不会陷入实现细节的困扰。
无论你是规划新的软件架构,还是分析现有的业务流程,一个构建良好的DFD都能清晰地阐明各组件之间的关系。它既是开发人员的蓝图,也是业务所有者之间的沟通桥梁。本指南探讨了创建有效图表所需的核心原则、符号、层级和最佳实践。
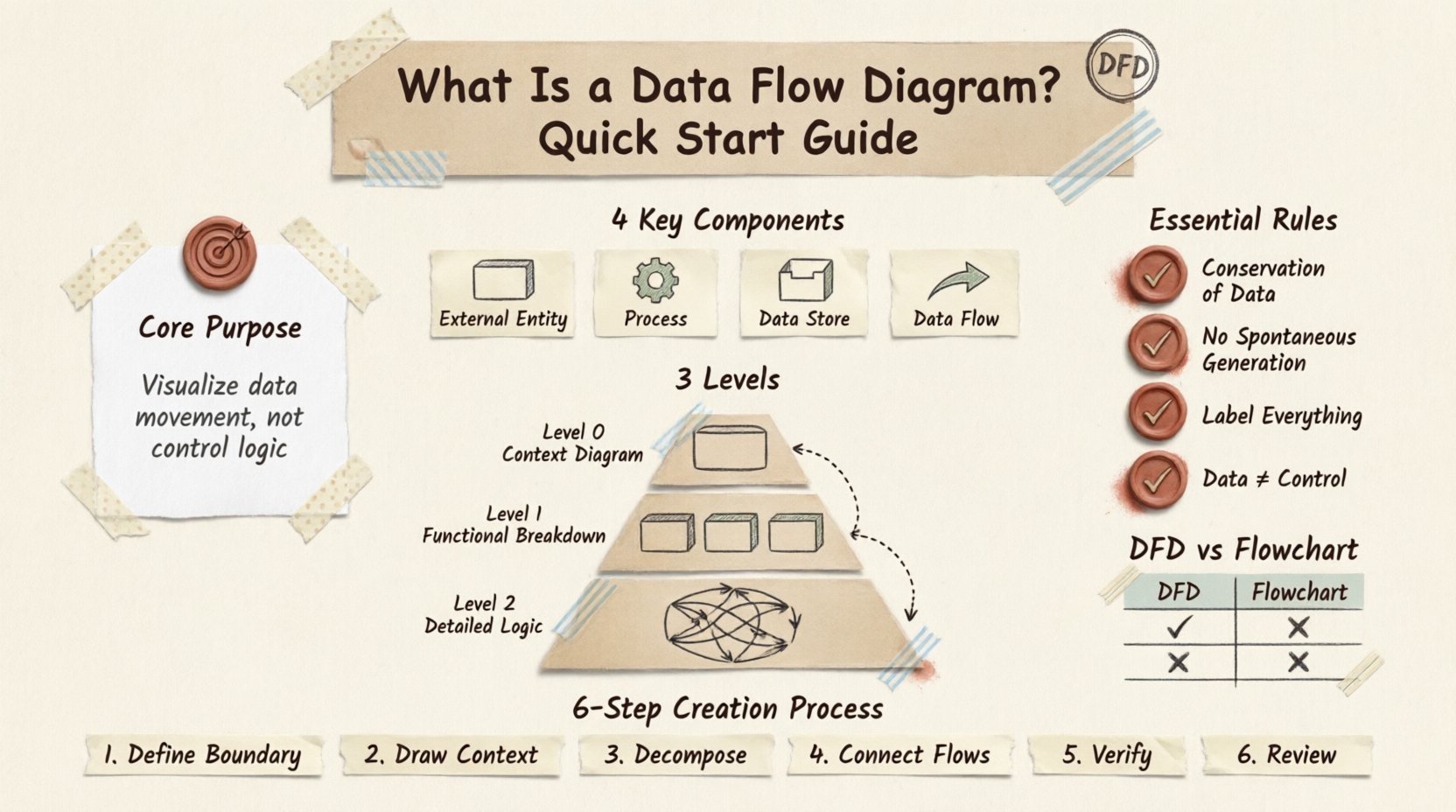
理解核心目的 🎯
数据流图的主要功能是可视化数据的流动。它不展示操作的顺序或事件的时间点,而是回答这样一个问题:“数据从哪里来,去往何处,以及如何被改变?”在区分逻辑设计与物理实现时,这一区别至关重要。
在构建系统时,团队常常面临复杂性的挑战。DFD将这种复杂性分解为可管理的部分。通过隔离特定流程,你可以分析数据的完整性,确保数据在传输过程中不会丢失或被破坏。它使分析人员能够发现数据无谓积聚或流向不必要的位置的瓶颈。
在需求收集阶段,DFD尤其具有价值。它们有助于确认所有必要的输入和输出都已考虑在内。如果某个流程产生了输出,但没有明确的来源,图表就会揭示设计中的漏洞。相反,如果数据进入系统却从未被使用,这表明存在冗余。
DFD的关键组成部分 🧩
每个数据流图都是由一组特定符号构成的。尽管不同方法论(如Gane和Sarson或Yourdon和Coad)之间的符号表示略有差异,但基本元素保持一致。理解这四个核心组成部分对于准确绘图至关重要。
1. 外部实体 🚪
外部实体代表系统边界之外的数据来源或目的地。这些是与所建模流程交互的用户、其他系统或组织。它们通常以矩形或方形表示。
-
来源: 向系统提供数据的实体(例如,客户下订单)。
-
接收者: 从系统接收数据的实体(例如,政府机构接收税务报告)。
需要记住的是,这些实体存在于当前系统的范围之外。它们是界定系统控制范围与非控制范围的边界标记。
2. 处理过程 ⚙️
处理过程代表转换数据的活动。它们是系统内部所执行的“工作”。一个处理过程接收输入数据,执行操作,然后生成输出数据。在DFD符号中,这些通常以圆角矩形或圆形表示。
每个处理过程都必须有一个名称,用动词和宾语来描述其功能。例如,“计算利息”或“更新库存”。一个处理过程若没有数据流入或流出,就无法存在。如果一个圆圈没有输入或输出连线,它在图中就没有实际作用。
3. 数据存储 🗄️
数据存储是信息被保存以备后续使用的地点。它们代表数据库、文件或物理档案。与处理过程不同,数据存储不会改变数据,只是将其保留。它们通常以开口的矩形或平行线表示。
绘制DFD时,应确保每个数据存储在一段时间内至少有一个输入流和一个输出流,除非它是终端存储点。这可以确保数据被访问和更新,从而维护存储信息的完整性。
4. 数据流 🔄
数据流是连接各组件的箭头。它们表示数据移动的方向。每个箭头都必须有一个标签,描述数据包的内容。例如,从“客户”到“处理过程”的箭头可能标注为“订单请求”,而从“处理过程”到“数据存储”的箭头可能标注为“销售记录”。
至关重要的是,数据流必须保持一致。如果一个处理过程输出“客户详情”,那么接收该数据的处理过程或存储必须能够接受这种特定的数据结构。在没有转换步骤的情况下,不能让“财务数据”流入一个仅用于处理“文本输入”的过程。
数据流图的层级 📉
一个完整的系统很少会用单一图表来表示。为了管理复杂性,DFD被分解为多个层级。这种分层方法使你能够从高层次概览开始,逐步深入到具体细节。
第0层:上下文图 🌍
第0层图,通常称为上下文图,提供了最宏观的视角。它将整个系统表示为一个单一的处理过程。所有外部实体都被展示为与这一中心过程进行交互。
该图清晰地界定了系统边界。它回答了这样一个问题:“系统是什么,谁与它交互?”它不展示内部的处理过程或数据存储,仅关注系统与外部世界之间的主要输入和输出。
第1级:功能分解 🔍
第1级将上下文图中的单一过程扩展为多个主要子过程。这是系统内部结构开始显现的地方。您将看到多个过程、数据存储以及连接它们的流程。
第1级图的输入和输出必须与上下文图保持一致。如果上下文图显示来自“用户”的输入,第1级图仍需显示该输入进入系统,即使它进入的是某个特定子过程。这确保了各层级之间的数据一致性。
第2级:详细逻辑 🧠
第2级图进一步分解第1级中的特定过程。该级别用于需要详细逻辑的复杂操作。并非每个过程都需要第2级图;只有那些足够复杂、值得进一步分解的过程才需要。
在此阶段,重点转向所需的特定数据转换。您可能会看到对数据存储的多次访问,或通过多个流程表示的复杂分支逻辑。这一级别通常是开发人员开始将需求映射到实际代码结构的阶段。
一致性与准确性规则 ✅
创建有效的DFD需要遵守特定规则。违反这些规则会导致混淆和设计错误。以下是指导DFD构建的基本原则。
数据守恒
数据在过程中不能被创造或销毁。它必须流入并流出。如果一个过程输出“报告”,则生成该报告所需的数据必须进入该过程。如果数据进入后消失,该图在逻辑上就是错误的。
无自发生成
一个过程不能在没有数据输入的情况下存在。不能存在一个没有输入就“自动发生”的过程。系统中的每个动作都是由数据或事件触发的。确保每个过程至少有一个输入数据流。
控制与数据
DFD不显示控制流,例如“如果/否则”逻辑或时序信号。虽然一个过程可能做出决策,但DFD只显示该决策所产生的数据,而不显示决策机制本身。对于控制逻辑,其他建模技术更为合适。
标注标准
每个箭头都必须标注。未标注的箭头无法提供关于数据内容的信息。同样,每个过程都必须使用动词-名词短语命名。标注不明确会导致开发阶段出现误解。
DFD与流程图的区别 🆚
人们常常将数据流图与流程图混淆。尽管两者都使用箭头和形状,但它们的作用不同。理解这一区别可以防止在系统文档中误用。
|
特性 |
数据流图(DFD) |
流程图 |
|---|---|---|
|
重点 |
数据的流动与转换 |
步骤顺序与逻辑流程 |
|
控制 |
不显示控制逻辑(循环、判断) |
明确显示判断和循环 |
|
时间 |
不表示时间或顺序 |
通常表示时间或执行顺序 |
|
组件 |
实体、过程、存储、流 |
开始/结束、过程、决策、输入/输出 |
当需要编程算法逻辑时,请使用流程图。当需要记录系统架构和数据需求时,请使用数据流图。它们是互补工具,而非可互换工具。
创建数据流图:逐步指南 🛠️
遵循此结构化方法,为您的项目构建一个可靠的图表。此过程从一开始就确保逻辑一致性。
-
定义系统边界:确定系统内部和外部的内容。识别与系统交互的主要外部实体。
-
绘制上下文图:绘制代表系统的单一过程。用箭头表示主要输入和输出,并连接到外部实体。
-
分解过程:将主过程分解为子过程。识别支持这些过程所需的数据存储。
-
连接数据流:在实体、过程和存储之间绘制连线。用具体传输的数据为每条线标注标签。
-
验证守恒性:检查各层级的输入和输出是否平衡。确保没有数据凭空消失或出现。
-
审查与优化:与利益相关者一起走查图表。确保视觉表示与他们对业务流程的理解一致。
逻辑型与物理型数据流图 🧠🖥️
根据抽象程度,数据流图可分为两类。理解这一区别有助于与不同受众进行沟通。
逻辑型数据流图:此图表关注系统做什么,而非如何实现。它忽略硬件、软件或人员角色。它描述业务需求。例如,“处理订单”是一个逻辑步骤,无论由人工职员还是自动脚本处理,都如此。
物理型数据流图:此图表描述系统实际的实现方式。它包含具体的硬件、软件模块和人员角色。如果逻辑型数据流图中写的是“处理订单”,物理型数据流图可能显示为“Web服务器API调用数据库以检查库存”。物理型数据流图通常在开发周期后期使用,当实现细节确定后。
数据流图设计中的常见挑战 🚫
即使经验丰富的分析师在建模复杂系统时也会遇到问题。了解这些挑战有助于生成更清晰的图表。
-
过度拥挤:试图将过多细节塞入单一图表会使图表难以阅读。使用分解方法,将复杂区域拆分为独立的图表。
-
缺少数据存储:有时会假设数据存在,但并未实际存储。确保每条需要持久化的信息都与一个数据存储相关联。
-
交叉的线条:尽管在复杂系统中不可避免,但应尽量减少线条交叉。这能提高视觉清晰度。如果图表跨越多个页面,请使用页面外连接器。
-
术语使用不当:在面向业务用户的图表中使用技术术语会造成混淆。应使用所建模领域中的专业词汇。
将DFD与其他模型集成 📚
数据流图很少孤立存在。它们是系统文档更大生态系统的一部分。将其与其他模型集成可以提升其价值。
实体-关系图(ERD):虽然DFD展示数据如何流动,但ERD展示数据如何结构化。DFD中的数据存储通常对应于ERD中的表。同时使用两者可确保数据流与数据结构保持一致。
统一建模语言(UML):在现代面向对象设计中,DFD可以映射到用例图或活动图。尽管UML更为全面,但DFD能更清晰地展示特定子系统的数据持久性和转换过程。
视觉清晰度的价值 🌟
有效的系统设计依赖于清晰的沟通。数据流图充当分析人员、开发人员和利益相关者之间的通用语言。它消除了关于数据需求和系统边界的模糊性。
通过遵循标准规范并专注于数据流动而非控制逻辑,你可以创建一份经得起时间考验的文档。即使技术栈发生变化,数据的流动通常仍保持不变。这使得DFD成为未来维护和扩展的持久资产。
从上下文图开始,谨慎地进行分解,并始终验证数据守恒。通过实践,你会发现DFD成为探索和记录任何复杂系统架构的直观方式。