











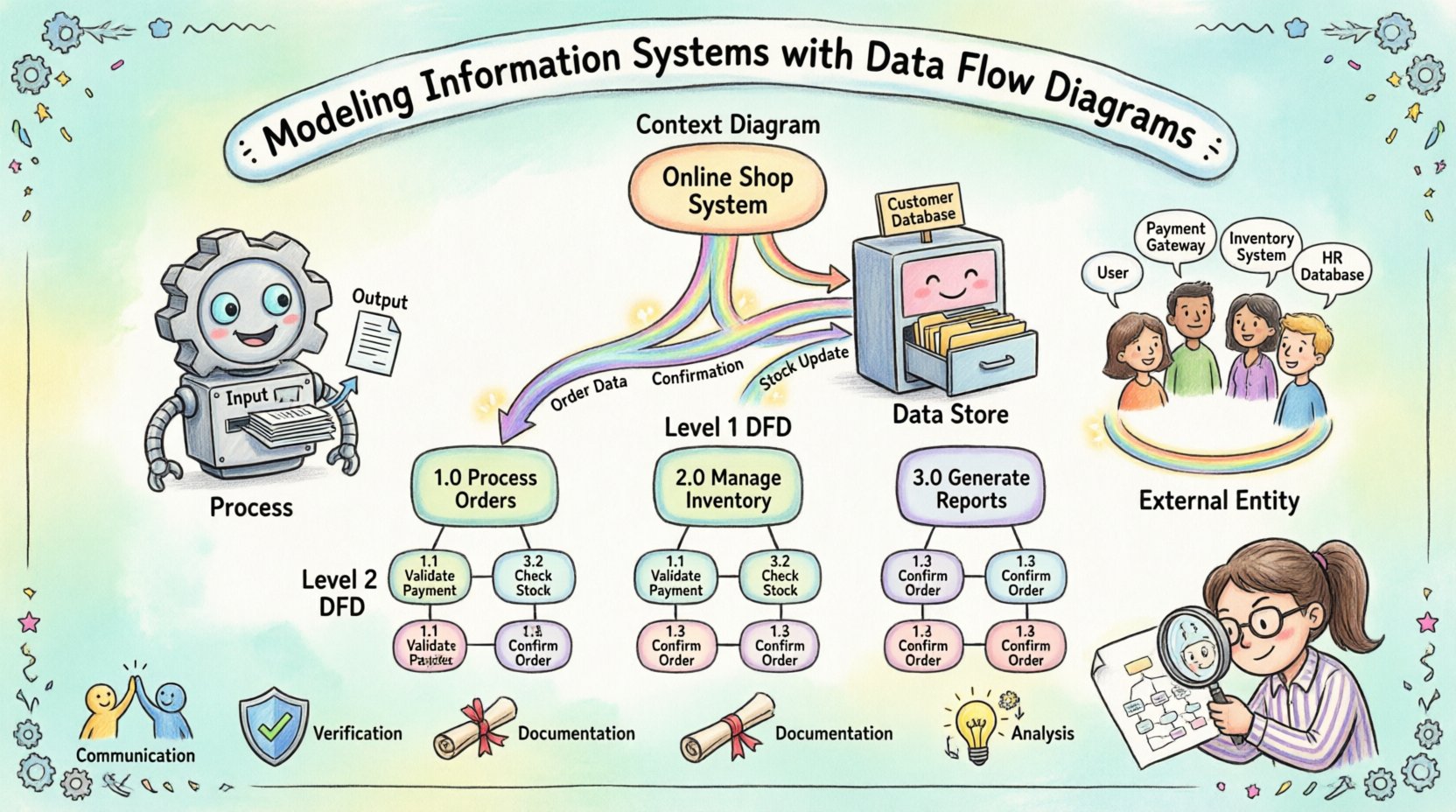
有效的系统设计始于理解组织内部数据的流动。当团队在没有清晰蓝图的情况下尝试构建复杂软件时,常常会出现业务需求与技术实现之间的脱节。对信息系统进行建模提供了一种结构化的方法来可视化这些交互。这一实践的核心是数据流图(DFD),这是一种强大的工具,用于记录信息如何被处理、存储和传输。
本文将通过数据流图(DFD)的视角探讨信息系统建模的原则。我们将研究构成要素、抽象层次以及创建稳健系统模型所需的分析技术。通过专注于数据流动的逻辑而非物理实现,分析师可以在编写任何代码之前确保清晰性和准确性。
理解系统建模的目的 🧩
在深入研究具体符号之前,理解我们为何要建模系统至关重要。信息系统不仅仅是数据库或用户界面;它是一个将输入转化为有用输出的流程网络。建模使利益相关者能够看到整体图景,而不会陷入技术细节中。
- 沟通:视觉图表弥合了技术团队与业务用户之间的鸿沟。每个人都能看到相同的信息流动。
- 验证:模型有助于在开发开始前验证所有业务需求都已考虑在内。
- 文档: 它们作为系统运行方式的持久记录,对未来的维护和培训非常有用。
- 分析: 图表揭示了瓶颈、冗余流程以及数据处理中的潜在安全漏洞。
当你对信息系统进行建模时,实际上就是在创建一份蓝图。正如建筑师不会在没有计划的情况下建造房屋一样,系统架构师也不应在没有地图的情况下编写逻辑。这种方法可以减少返工,并确保最终产品与组织目标保持一致。
数据流图的核心组件 🏗️
数据流图依赖于四个主要元素来表示系统。每个元素都有其特定的角色和视觉表现形式。理解这些基本构件是创建有效模型的第一步。
1. 处理过程 ⚙️
处理过程代表转换数据的操作。它们是系统的引擎。一个处理过程接收输入数据,执行某种操作,并产生输出数据。在图中,处理过程通常以圆形或圆角矩形表示。它必须有一个描述该操作的名称,例如“计算税款”或“验证登录”。
每个处理过程都必须至少有一个输入和一个输出。一个处理过程不能在不转换数据的情况下存在。如果数据进入一个处理过程但没有任何输出,那么模型就是不完整的。如果数据在没有输入的情况下离开,那么输出就无法解释。这一守恒原则确保了逻辑的一致性。
2. 数据存储 🗄️
数据存储表示信息被保存以供后续使用的地点。这些可以是物理数据库、文件,甚至是实体文件柜。在DFD中,数据存储通常以开放的矩形或两条平行线表示。与处理过程不同,数据存储不会转换数据;它们只是保留数据。
区分处理过程和数据存储至关重要。处理过程会改变数据的状态,而数据存储则保持其不变。处理过程与数据存储之间的连接表示数据正在被读取或写入存储。这一区别有助于明确信息是正在被主动处理,还是仅仅被归档。
3. 外部实体 👥
外部实体是系统边界之外的数据来源或目的地。它们与系统交互,但不属于系统内部逻辑。例如包括客户、供应商、监管机构或其他系统。在图中,这些通常以方形或矩形表示。
在建模时,必须明确界定范围。系统内部是什么,外部又是什么?外部实体是指在当前模型范围内无法直接控制或修改的任何事物。这有助于将分析聚焦于责任边界。
4. 数据流 🔄
数据流表示信息在处理过程、存储和实体之间的流动。它们由箭头表示。每个箭头都必须有一个标签,描述所传输的数据,例如“订单详情”或“付款收据”。
数据流不表示控制信号或时间顺序。它们代表实际的信息内容。数据流可以分叉或合并,但必须始终携带有意义的数据。箭头不应无谓交叉,以保持可读性。如果一个数据流连接两个处理过程,表示信息的直接交接。
抽象层次与分解 🔍
复杂系统无法通过单一视图来理解。为了管理复杂性,分析师使用分解法,将系统拆分为可管理的层级。这种分层方法可根据受众和目的提供不同层次的细节。
上下文图(第0层)
上下文图提供了最高层次的抽象。它将整个系统表示为一个单一的处理过程,并标识出所有与之交互的外部实体。这一视图回答了“系统是什么?”的问题,并清晰地定义了边界。
在此图中,你不会看到内部处理过程或数据存储。你只能看到系统边界以及数据的流入和流出。这通常是第一个创建的图表,用于获得利益相关者对范围的一致意见。
第1层图
第1层图将上下文图中的单一处理过程扩展为多个主要子过程。它揭示了系统的主功能区域。例如,“管理订单”过程可能分解为“接收订单”、“检查库存”和“处理付款”。
这一层级引入了数据存储,并展示了数据在主要功能之间的流动方式。它足够详细,使技术团队能够理解架构,但又足够抽象,避免陷入具体逻辑的细节中。
第2层及更高层次
进一步分解会持续进行,直到每个过程都简单到无需再分解即可理解。这通常是记录特定业务规则的地方。在此层级上,图表可直接作为开发人员编写代码的参考。
分解必须保持平衡。父过程的输入和输出必须与子过程的输入和输出相匹配。如果一个过程分解为三个子过程,进入父过程的数据仍必须由子过程共同接收,而子过程输出的数据也必须共同返回到父过程。
符号标准与一致性 📏
尽管数据流图(DFD)的概念是通用的,但所使用的符号可能有所不同。行业中存在两种主要符号体系。选择一种并坚持使用,对于保持清晰至关重要。
| 功能 | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| 过程 | 圆或圆角矩形 | 圆角矩形 |
| 数据存储 | 开放矩形 | 开放矩形(带粗线) |
| 外部实体 | 矩形 | 矩形 |
| 数据流 | 弯曲或直线箭头 | 直线箭头 |
一致性可以防止混淆。如果团队在项目中途更换符号体系,文档将变得支离破碎。最好尽早确立标准,并将其记录在样式指南中。
此外,命名规范也应保持一致。过程使用动词(例如“更新记录”),数据流使用名词(例如“记录数据”)。这种语法上的区分有助于读者快速识别每个元素的功能。
系统优化分析 🛠️
创建图表不仅仅是文档工作;它本质上是一种分析。一旦模型建立,你就可以对其进行深入探究,以发现效率低下或潜在风险。
识别瓶颈
寻找那些接收多个输入但仅产生单一输出的过程。这些区域往往是工作积压的瓶颈。两点之间存在高流量数据流,可能表明需要优化或采用并行处理。
检查数据完整性
审查数据的存储与读取方式。敏感的数据流在模型中是否已加密?数据存储在写入前是否经过验证?一个设计良好的系统应在每一步都确保数据质量。如果数据在未经验证的情况下直接流入存储,模型就揭示了一个潜在风险。
消除冗余
你是否在图表的不同部分看到相同的过程被重复?这表明存在冗余。你可能能够将这些功能合并为单一服务。减少重复可以节省资源并简化维护。
验证完整性
确保每个外部实体都有相应的数据流。如果存在客户但没有数据流入或流出,模型就是不完整的。同样,检查每个数据存储是否都有写入者和读取者。孤立的数据存储可能意味着存在未使用的存储空间。
维护与演进的最佳实践 🌱
信息系统并非一成不变。随着业务需求的变化,它们会不断演进。今天准确的模型,明天可能就过时了。因此,维护文档与创建文档同样重要。
版本控制
跟踪图表的变更。版本号或日期应清晰可见。这有助于团队理解发生了什么变化以及原因。如果新设计出现问题,还可以进行回滚。
利益相关者评审
定期与业务用户一起评审模型。他们是最可靠的依据,可以判断系统是否符合其工作流程。如果一个流程与现实不符,那么无论它看起来多么合理,模型都是错误的。
与其他模型的集成
DFD并非孤立存在。它们通常与实体关系图(ERD)关联以表示数据结构,与状态转换图关联以表示系统行为。确保这些模型保持一致,可以避免流程逻辑与数据结构之间的矛盾。
分析师的角色 🧑💼
建模的成功在很大程度上取决于分析师。他们必须充当业务语言与技术逻辑之间的翻译者。这需要出色的沟通能力以及对领域的深刻理解。
有效的分析师会提出深入的问题:“这些数据来自哪里?”“如果缺少这个输入会发生什么?”“谁负责这个更新?”这些问题能够揭示利益相关者可能忽略的隐藏需求。
耐心同样至关重要。建模是一个迭代过程。最初的图表很可能会出错或不完整。目标是通过反馈不断优化它们。如果某个图表行不通,不要害怕放弃;应从中学到经验,构建更优的模型。
结论与最终思考 🚀
使用数据流图对信息系统进行建模,是任何参与系统设计人员的基本技能。它提供了一种清晰、直观的语言,用于讨论复杂流程。通过关注数据流动而非实现细节,团队可以确保一致性并减少错误。
从简单的上下文图到详细的二级模型,这一过程需要纪律和细致入微的关注。然而,回报是显而易见的:系统将更易于理解、维护和改进。随着组织持续依赖数字解决方案,能够准确描绘其逻辑的能力,始终是一项关键资产。
从基础开始。明确你的边界。分解你的流程。审查你的工作。通过不断练习,创建这些模型将变得自然而然,从而打造出更稳健、更高效的信息化系统。