











В современных распределенных системах надежность сервиса бэкенда часто зависит от того, насколько хорошо он справляется с одновременными запросами и общими ресурсами. Одной из самых устойчивых и трудно воспроизводимых проблем в этой области является взаимоблокировка. Взаимоблокировка возникает, когда два или более процесса не могут продолжать работу, потому что каждый ожидает освобождения ресурса другим. Это состояние постоянной блокировки может полностью остановить всю систему, вызывая несогласованность данных, недоступность сервиса и разочарование пользователей. Чтобы снизить эти риски, архитекторы и инженеры должны выходить за рамки простого обзора кода и внедрять визуальный подход к проектированию системы. Диаграммы взаимодействия предоставляют структурированный способ отображения взаимодействий, выявления потенциальных точек конфликта и внедрения паттернов устойчивости еще до написания кода.
В этом руководстве рассматриваются механизмы взаимоблокировок в средах бэкенда и показано, как диаграммы взаимодействия могут выступать в качестве профилактического инструмента. Визуализируя поток управления и приобретение ресурсов, команды могут выявлять циклические зависимости и внедрять стратегии для их разрыва. Мы рассмотрим теоретические основы, практические методы визуализации и конкретные архитектурные паттерны, способствующие устойчивости системы.
Понимание механизмов взаимоблокировки 🛑
Прежде чем решать вопрос профилактики, необходимо понимать условия, которые приводят к взаимоблокировке. В информатике взаимоблокировка — не случайное событие; она является результатом одновременного возникновения определенного набора условий. Их часто называют условиями Кофмана. Для того чтобы взаимоблокировка существовала, должны выполняться все четыре следующих условия:
- Взаимное исключение: По крайней мере один ресурс должен удерживаться в режиме, недоступном для совместного использования. В любой момент времени только один процесс может использовать этот ресурс.
- Удержание и ожидание: Процесс должен удерживать хотя бы один ресурс, одновременно ожидая приобретения дополнительных ресурсов, находящихся в распоряжении других процессов.
- Невозможность принудительного освобождения: Ресурсы не могут быть принудительно изъяты у процесса. Они должны быть освобождены добровольно процессом, который их удерживает.
- Циклическое ожидание: Существует набор процессов, в котором P1 ожидает P2, P2 ожидает P3 и так далее, пока Pn не ожидает P1.
В однопоточном приложении взаимоблокировка встречается редко. Однако в системах бэкенда, обрабатывающих тысячи одновременных запросов, эти условия легко выполняются. Например, если Сервис A удерживает блокировку на Ресурсе X и ожидает Ресурс Y, а Сервис B удерживает Ресурс Y и ожидает Ресурс X, образуется циклическое ожидание. Без возможности принудительного освобождения или тщательной очередности система замораживается.
Роль диаграмм взаимодействия 📊
Диаграммы взаимодействия — это тип диаграммUnified Modeling Language (UML). В то время как диаграммы последовательности фокусируются на хронологии сообщений, диаграммы взаимодействия акцентируют внимание на структурной организации объектов и связях между ними. В контексте устойчивости бэкенда этот структурный взгляд имеет решающее значение. Он позволяет дизайнерам увидетьктообщается скемикакиекакие ресурсы обмениваются, а не просто порядок поступления сообщений.
При проектировании архитектуры микросервисов или сложного монолитного бэкенда диаграммы взаимодействия помогают ответить на ключевые вопросы:
- Какие сервисы требуют эксклюзивного доступа к одной и той же таблице базы данных?
- Существуют ли двунаправленные зависимости между двумя обрабатывающими модулями?
- Цепочка запросов возвращается к инициатору до завершения?
- Какова максимальная глубина вложенных блокировок ресурсов?
Отображая эти взаимодействия на ранних этапах проектирования, команды могут выявить потенциальные сценарии взаимоблокировок, которые могут остаться незамеченными при чисто код-ориентированном обзоре. Диаграмма выступает в роли контракта на взаимодействие, делая неявные предположения явными.
Отображение зависимостей ресурсов 🗺️
Чтобы эффективно использовать диаграммы взаимодействия для предотвращения взаимоблокировок, диаграмма должна отображать ресурсы, а не только поток данных. Стандартные диаграммы взаимодействий часто показывают вызовы между сервисами. Однако для анализа блокировок необходимо аннотировать связи идентификаторами ресурсов. Это требует небольшого повышения уровня абстракции, при котором узлы представляют процессы или потоки, а связи — общие ресурсы или каналы связи.
Шаги по созданию диаграммы, осведомлённой о взаимоблокировках
- Определите критически важные ресурсы: Перечислите все общие состояния, такие как строки базы данных, дескрипторы файлов или буферы памяти. Назначьте им уникальные идентификаторы.
- Определите владение: Определите, какой сервис или поток в настоящее время управляет каким ресурсом. Отметьте это на диаграмме.
- Отслеживайте пути получения ресурсов: Нарисуйте стрелки, указывающие на запрос ресурса. Подпишите стрелку названием ресурса.
- Выделите состояния ожидания: Используйте специальную нотацию для отображения того, когда процесс заблокирован и ожидает ресурс.
- Анализируйте циклы: Ищите замкнутые петли на диаграмме, где Процесс А ожидает Процесс Б, который, в свою очередь, ожидает Процесс А.
Выявление шаблонов циклического ожидания 🔁
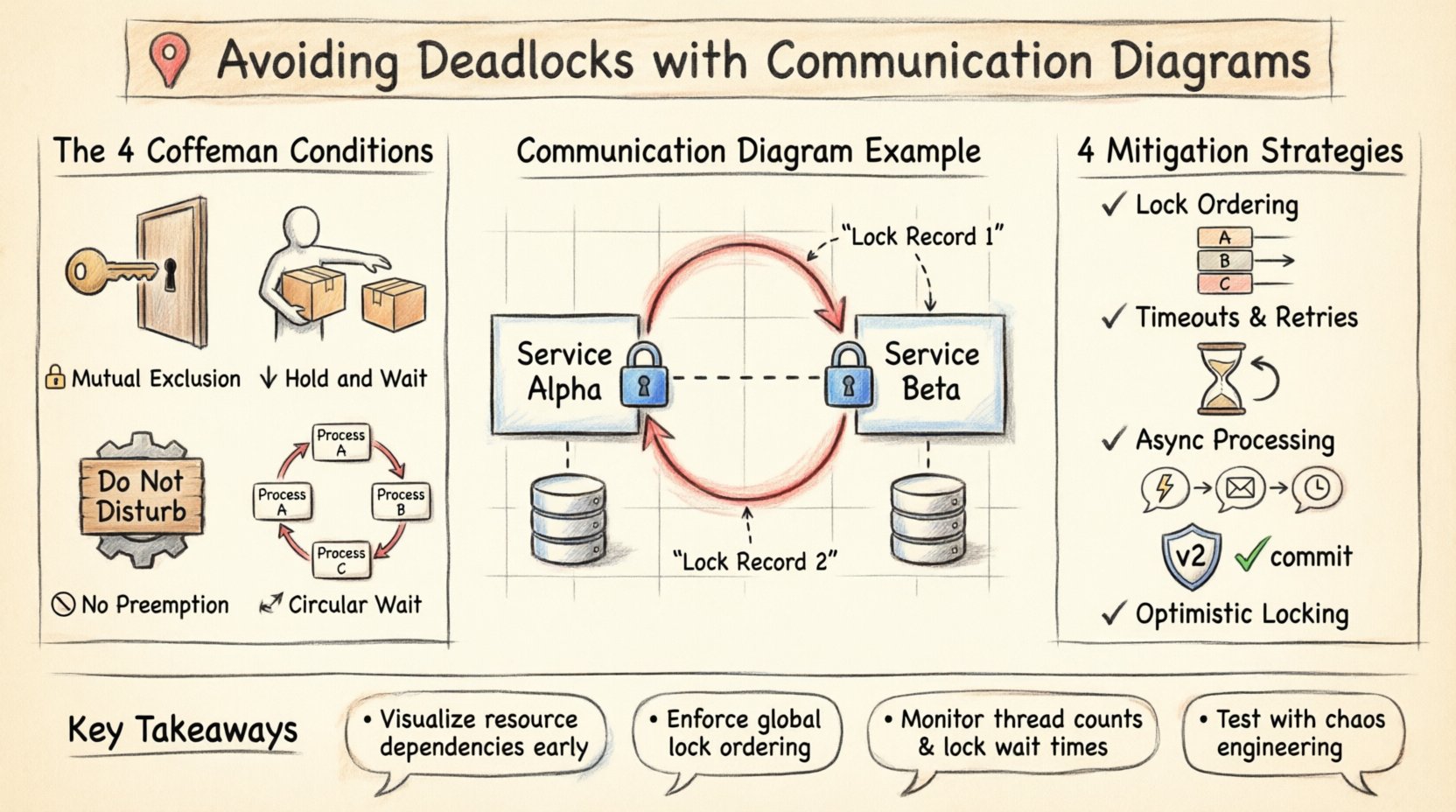
Самый опасный шаблон в проектировании систем — циклическая зависимость. На диаграмме взаимодействия она проявляется как замкнутая петля взаимодействий. Рассмотрим сценарий, включающий два сервиса — Service Alpha и Service Beta.
- Сервис Alpha инициирует транзакцию и блокирует Запись 1.
- Сервис Alpha запрашивает блокировку Записи 2 у сервиса Beta.
- Сервис Beta уже владеет блокировкой Записи 2, но ему необходимо обновить Запись 1, которая заблокирована сервисом Alpha.
На визуальном представлении эта петля сразу бросается в глаза. Диаграмма показывает, что Alpha указывает на Beta, а Beta указывает обратно на Alpha, каждый из них требует ресурс, удерживаемый другим. Без диаграммы этот логический конфликт может быть обнаружен только во время сбоя в продакшене или сложного теста нагрузки.
Распространённые сценарии, приводящие к цикличности
- Распространение транзакций: Когда распределённая транзакция требует, чтобы несколько сервисов зафиксировали изменения в определённом порядке, но этот порядок не соблюдается.
- Вложенные вызовы: Функция вызывает другую функцию, которая в конечном итоге вызывает исходную функцию, создавая рекурсивную цепочку блокировок.
- Общий кэш: Несколько сервисов пытаются одновременно обновить одну и ту же запись кэша без механизма распределённой блокировки.
- Внешние ключи базы данных: Обновления в связанных таблицах, требующие блокировок в обеих таблицах, при этом порядок обновления различается между сервисами.
Стратегические методы смягчения 🛠️
Как только диаграмма взаимодействия выявляет потенциальную взаимоблокировку, требуются конкретные архитектурные изменения. Не существует единого решения, подходящего для каждой системы, но существует несколько проверенных стратегий, позволяющих разорвать условия Кофмана.
1. Порядок блокировок
Это наиболее эффективный метод предотвращения циклического ожидания. Система должна обеспечивать глобальный порядок ресурсов. Если каждый процесс запрашивает ресурсы в одном и том же порядке (например, Ресурс A перед Ресурсом B), цикл не может возникнуть. На диаграмме взаимодействия это означает, что все связи, запрашивающие Ресурс X, должны быть установлены до того, как какая-либо связь запросит Ресурс Y.
2. Тайм-ауты и повторные попытки
Даже при соблюдении порядка возможны конфликты. Внедрение тайм-аута при получении ресурсов гарантирует, что процесс не будет ждать бесконечно. Если блокировка не может быть получена в течение указанного времени, процесс освобождает свои текущие ресурсы и повторяет попытку. Это предотвращает постоянную блокировку системы, хотя может привести к задержкам.
3. Асинхронная обработка
Переход от синхронных запросов к асинхронным архитектурам, основанным на событиях, может снизить конкуренцию. Вместо ожидания освобождения блокировки сервис публикует событие и продолжает обработку. Когда ресурс становится доступным, потребитель обрабатывает обновление. Это разделяет временные рамки использования ресурсов.
4. Оптимистическая блокировка
Вместо получения блокировки перед чтением или изменением данных система проверяет конфликты на момент фиксации. Если другой процесс изменил данные с момента чтения, транзакция завершается неудачно и должна быть повторена. Это уменьшает время удержания блокировок, минимизируя окно для возникновения взаимоблокировки.
Сравнение стратегий предотвращения
| Стратегия | Предотвращает условие | Сложность | Влияние на производительность |
|---|---|---|---|
| Порядок блокировок | Круговая ожидание | Высокая | Низкая |
| Тайм-ауты | Удержание и ожидание (косвенно) | Низкая | Средняя (повторные попытки) |
| Оптимистическая блокировка | Взаимное исключение (долгосрочное) | Средняя | Переменное |
| Асинхронный поток | Удержание и ожидание | Высокая | Низкая |
Шаги реализации для анализа на основе диаграмм
Чтобы интегрировать этот подход в ваш рабочий процесс разработки, следуйте этим шагам:
- Проведите обзор архитектуры: Перед написанием кода создайте диаграмму взаимодействия для новых функций. Сфокусируйтесь на путях доступа к данным.
- Примечание использования ресурсов:Отметьте каждый запрос к базе данных, обновление кэша или операцию с файлом на диаграмме.
- Запустите алгоритм обнаружения циклов: Если используются автоматизированные инструменты, примените алгоритмы графов для обнаружения циклов в графе зависимостей, полученном из диаграммы.
- Рефакторинг для независимости: Если цикл найден, рефакторьте код для разрыва зависимости. Это может потребовать введения посреднического сервиса или изменения модели данных.
- Проверка с помощью тестирования нагрузки:Имитируйте высокую конкуренцию, чтобы убедиться, что паттерны взаимоблокировки не проявляются под нагрузкой.
Мониторинг и наблюдаемость 🧪
Даже при тщательном проектировании условия во время выполнения могут меняться. Инструменты мониторинга должны быть настроены для обнаружения признаков взаимоблокировки. Ключевые метрики включают:
- Количество потоков:Резкий рост заблокированных потоков может указывать на конкуренцию за ресурсы.
- Время ожидания блокировки: Если среднее время получения блокировки значительно увеличивается, конкуренция растёт.
- Откаты транзакций: Высокая частота откатов транзакций из-за таймаута или конфликта указывает на чрезмерную агрессивность стратегий блокировки.
- Журналы обнаружения взаимоблокировок: Некоторые базы данных и операционные системы ведут журналы событий взаимоблокировок. Эти журналы должны быть интегрированы в централизованную систему ведения журналов.
Кейс: поток взаимодействия сервисов
Рассмотрим типовой backend электронной коммерции, обрабатывающий заказы и инвентарь. Сервис A отвечает за заказы, а сервис B — за инвентарь.
Сценарий: Сервис A создаёт заказ и блокирует идентификатор заказа. Затем он вызывает сервис B для резервирования инвентаря. Сервис B блокирует идентификатор инвентаря. Чтобы обновить статус заказа, сервис B должен отправить обратный вызов сервису A, что требует повторной блокировки идентификатора заказа.
Взаимоблокировка: Если сервис A удерживает идентификатор заказа и ожидает, пока сервис B освободит идентификатор инвентаря, но сервис B не может завершиться без освобождения сервисом A идентификатора заказа (через обратный вызов), возникает взаимоблокировка. Это сценарий вложенной блокировки.
Решение: С помощью диаграммы взаимодействия этот цикл становится очевидным. Решение заключается в разрыве зависимости. Сервис B должен обновлять инвентарь асинхронно или использовать отдельный идентификатор транзакции, который не требует повторной блокировки идентификатора заказа, удерживаемого сервисом A. Диаграмма тогда покажет односторонний поток от A к B без обратного пути, требующего исходной блокировки.
Рассмотрение распределённой блокировки
В распределённых средах блокировки часто управляются внешними сервисами, а не самим приложением. Это вводит задержки в сети и риск частичных сбоев. Диаграммы взаимодействия должны учитывать сетевое соединение как потенциальную точку отказа. Если соединение между сервисом A и менеджером блокировок выйдет из строя, сервис A может считать, что удерживает блокировку, в то время как другой сервис её удерживает.
Чтобы решить эту проблему, диаграмма должна включать узел «Менеджер блокировок». Взаимодействия с этим узлом должны быть идемпотентными и ограниченными по времени. Проектирование должно обеспечивать, что при сбое сервиса блокировка будет автоматически освобождена после истечения срока аренды. Это предотвращает бесконечное существование условия «удержание и ожидание».
Тестирование на устойчивость
Диаграммы проектирования являются теоретическими. Для проверки устойчивости необходимы тесты в реальных условиях. Это включает:
- Хаос-инжиниринг:Сознательно вводите задержки или сбои в сетевых соединениях, показанных на диаграмме, чтобы проверить, восстанавливается ли система или происходит зависание.
- Тестирование на нагрузку:Запуск одновременных запросов, соответствующих шаблонам, выявленным на диаграмме, для проверки правильной работы порядка блокировок при нагрузке.
- Статический анализ:Используйте инструменты для анализа кодовой базы на наличие потенциальных нарушений порядка блокировок, соответствующих логике диаграммы.
Заключение
Избегание взаимоблокировок — это не просто упражнение по программированию; это вызов в проектировании системы. Используя диаграммы взаимодействия, команды могут визуализировать сложную сеть зависимостей ресурсов, приводящую к зависанию системы. Такой подход смещает фокус с реактивного отладки на проактивную профилактику. Понимание четырех условий возникновения взаимоблокировки, построение путей получения ресурсов и соблюдение строгого порядка или асинхронных паттернов являются необходимыми шагами при создании устойчивой инфраструктуры бэкенда. Хотя ни одна система не застрахована от проблем с параллелизмом, структурированный визуальный подход значительно снижает риск и сложность управления общими ресурсами. Последовательное применение этих принципов гарантирует, что сервисы останутся отзывчивыми, а данные — согласованными, даже при высокой нагрузке и сбоях.