











Ao modelar sistemas complexos, a clareza é o objetivo principal. Diagramas de Fluxo de Dados (DFDs) servem como uma ferramenta fundamental para visualizar como as informações se movem através de um sistema. Neste contexto, dois símbolos dominam o cenário: o Processo e o Armazenamento de Dados. Embora interajam frequentemente, eles representam conceitos fundamentalmente diferentes em relação à transformação e à persistência. Compreender essa diferença é essencial para uma análise e um design de sistema precisos.
Este guia explora os papéis funcionais, as representações visuais e as implicações lógicas desses elementos. Ao distinguir entre ação e armazenamento, os analistas podem construir diagramas que comuniquem o comportamento do sistema sem ambiguidade.
🔄 Definindo o Processo
Um processo representa uma unidade de trabalho ou transformação. É onde os dados mudam de forma, são calculados ou filtrados. Pense em um processo como uma caixa preta. Você sabe o que entra e o que sai, mas o mecanismo interno é definido pela própria lógica de transformação, e não pelo armazenamento dessa informação.
🔹 Características Principais
- Transformação: A função principal é modificar os dados. Os dados de entrada entram, regras ou lógica são aplicadas, e os dados de saída saem.
- Natureza Temporal: Os processos são ativos apenas quando acionados. Eles não retêm dados entre execuções.
- Direcionalidade: Os dados fluem para dentro e para fora de um processo. Um processo sem entrada ou saída é logicamente inválido no contexto de um DFD.
- Nomenclatura com Verbos: Os processos são geralmente rotulados com verbos ou frases verbais (por exemplo, Calcular Imposto, Validar Usuário, Gerar Relatório).
🔹 Conceito da Caixa Preta
No modelamento de alto nível, um processo é uma caixa preta. O foco está em o que acontece com os dados, e não como acontece tecnicamente. Por exemplo, um processo chamado “Processar Pedido” recebe os detalhes do pedido e cria um registro de transação. Ele não especifica se o cálculo ocorre na memória, em disco ou por meio de uma API remota. Essa abstração permite que os interessados se concentrem na lógica de negócios, e não na implementação técnica.
No entanto, à medida que os diagramas são decompostos em níveis inferiores, a lógica interna torna-se mais detalhada. Mesmo assim, o processo permanece como um motor ativo de transformação. Ele consome a entrada, realiza o trabalho e produz a saída. Ele não serve como um tanque de armazenamento para essas informações.
🗄️ Definindo o Armazenamento de Dados
Uma loja de dados representa um repositório onde as informações permanecem. Diferentemente de um processo, uma loja de dados não transforma dados. Ela aguarda. Mantém os dados em um estado persistente até que um processo os recupere ou um processo os coloque lá.
🔹 Características Principais
- Persistência: Os dados permanecem em uma loja mesmo quando nenhum processo está ativo. Esse é o diferencial principal em relação a buffers de memória ou variáveis temporárias.
- Natureza Passiva: As lojas de dados não iniciam ações. Elas exigem um processo para ler ou escrever nelas.
- Nomeação com Substantivos: As lojas geralmente são rotuladas com substantivos (por exemplo, Banco de Dados de Clientes, Arquivo de Pedidos, Registro de Estoque).
- Aberto: Os fluxos de dados podem entrar e sair de uma loja. No entanto, uma loja não pode se conectar diretamente a outra loja. Os dados devem fluir por meio de um processo para se mover entre repositórios.
🔹 O Conceito de Repositório
Imagine uma biblioteca. Os livros são os dados. As prateleiras são as lojas de dados. Um bibliotecário é o processo. O bibliotecário não cria os livros; ele os organiza. As prateleiras não movem os livros por si mesmas; elas os mantêm em seu lugar. Quando um leitor solicita um livro, o bibliotecário o recupera (operação de leitura). Quando um novo livro chega, o bibliotecário o coloca na prateleira (operação de escrita).
Na arquitetura de sistemas, uma loja de dados pode representar uma tabela de banco de dados, um arquivo plano, uma fila ou um bucket na nuvem. O símbolo DFD abstrai a tecnologia. Seja uma tabela SQL ou um arquivo de texto simples, o papel lógico é idêntico: é um local onde as informações são mantidas.
⚡ Interação e Fluxo de Dados
A relação entre um processo e uma loja de dados é regida por regras estritas de fluxo de dados. As setas em um DFD representam o movimento de dados. Essas setas determinam a direção da transferência de informações.
🔹 O Ciclo de Leitura-Escrita
Quando um processo precisa de informações, ele desenha uma seta de uma loja de dados para o processo. Isso indica uma operação de leitura. O processo extrai os dados para usá-los em sua lógica de transformação. Por outro lado, quando um processo gera novas informações, ele desenha uma seta do processo para uma loja de dados. Isso indica uma operação de escrita. Os dados agora são armazenados para uso futuro.
Crucialmente, um fluxo de dados não pode conectar duas lojas de dados diretamente. As informações não podem migrar de um repositório para outro sem serem processadas. Essa regra reforça o princípio de que o movimento de dados sempre é acompanhado por algum nível de lógica ou controle, mesmo que essa lógica seja apenas uma operação de cópia simples.
🔹 Entidades Externas
Entidades externas (fontes ou sumidouros) interagem com processos, e não diretamente com lojas de dados. Uma entidade externa pode ser um usuário humano, uma API de terceiros ou outro sistema. Elas enviam dados para um processo ou recebem dados de um processo. O processo então decide se armazena esses dados em um repositório ou os descarta.
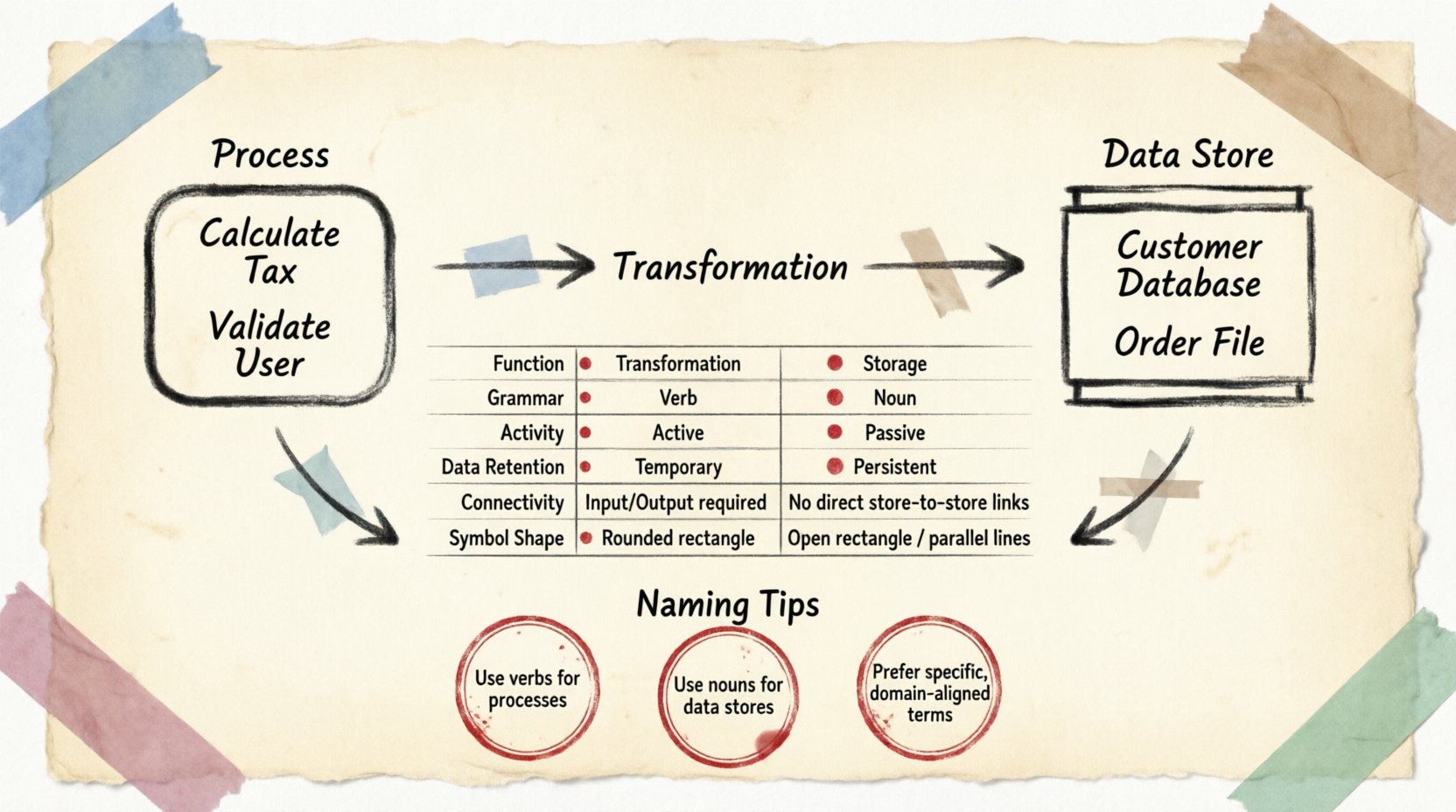
📋 Tabela de Comparação
Para resumir as diferenças estruturais, considere a seguinte análise dos atributos.
| Atributo | Processo | Loja de Dados |
|---|---|---|
| Função | Transformação / Ação | Armazenamento / Memória |
| Gramática | Verbo (por exemplo, Atualizar) | Substantivo (por exemplo, Tabela de Usuários) |
| Atividade | Ativo (Executa quando acionado) | Passivo (Permanece parado até ser acessado) |
| Retenção de Dados | Temporário (Durante a execução) | Persistente (De longo prazo) |
| Conectividade | Conecta-se a Entidades, Armazenamentos e Outros Processos | Conecta-se apenas a Processos |
| Forma do Símbolo | Retângulo arredondado ou Círculo | Retângulo aberto ou Linhas paralelas |
🧩 Convenções de Nomeação
A consistência na nomeação evita confusão durante as fases de revisão e implementação. A ambiguidade surge frequentemente quando o mesmo termo é usado tanto para armazenamento quanto para ação.
🔹 Nomeação de Processos
Os nomes devem descrever a ação realizada sobre os dados. Evite nomes genéricos como “Faça Isso” ou “Trate”. Em vez disso, use descritores específicos. Por exemplo, “Validar Credenciais de Login” é superior a “Verificar Login”. Essa clareza ajuda os desenvolvedores a entenderem imediatamente os requisitos esperados de entrada e saída.
🔹 Nomeação de Armazenamentos de Dados
Os nomes devem refletir o conteúdo armazenado. Use substantivos no plural ou identificadores claros. “Pedidos” implica uma coleção de registros de pedidos. “Pedido” pode indicar uma única instância de transação. Embora o contexto importe, substantivos no plural geralmente indicam um repositório contendo múltiplos registros.
Ao nomear armazenamentos de dados, considere o escopo. Um armazenamento chamado “Banco de Dados” é muito vago. “Banco de Dados de Clientes” ou “Registro de Transações” fornece o contexto necessário. Essa granularidade auxilia na mapeamento do diagrama para estruturas físicas de armazenamento posteriormente.
🧪 Decomposição e Níveis
Os DFDs são hierárquicos. Um diagrama de alto nível (Diagrama de Contexto) mostra o sistema como um único processo. À medida que você o decompõe em níveis inferiores, a distinção entre processo e armazenamento torna-se mais crítica.
🔹 Nível 0 vs. Nível 1
No Diagrama de Contexto, todo o sistema é um único processo. No Nível 0, esse processo é dividido em sub-processos principais. Armazenamentos de dados são introduzidos aqui para mostrar onde residem os principais componentes de dados. No Nível 1 e além, os processos são refinados ainda mais.
Durante a decomposição, certifique-se de que os armazenamentos de dados não sejam duplicados desnecessariamente. Se um armazenamento existe no Nível 0, ele geralmente deve persistir até o Nível 1, a menos que um sub-processo específico exija um cache temporário (que seria um armazenamento diferente). A consistência entre os níveis garante rastreabilidade.
🔹 Equilíbrio
Uma regra crítica na decomposição é o “Equilíbrio”. As entradas e saídas de um processo pai devem corresponder às entradas e saídas dos processos filhos no diagrama de nível inferior. Os armazenamentos de dados também devem estar alinhados. Se um armazenamento aparece no diagrama pai, o diagrama filho deve considerar corretamente esse fluxo de dados. Se um processo for dividido, o fluxo de dados para o armazenamento deve ser mantido em toda a divisão.
⚠️ Erros Lógicos a Evitar
Certos erros estruturais podem invalidar um diagrama. Reconhecer esses erros cedo economiza tempo durante a fase de desenvolvimento.
- Fluxos de Dados Fantasma: Uma seta saindo de um processo sem um fluxo de dados de entrada é impossível. Um processo não pode gerar saída do nada. Toda saída deve ser derivada de uma entrada ou dados armazenados.
- Conexões Diretas entre Armazenamentos: Como mencionado, um armazenamento não pode se conectar a outro armazenamento. Os dados devem passar por um processo. Isso garante que todo movimento de dados seja intencional e processado.
- Processos Isolados: Um processo que não possui fluxos de dados de entrada ou saída está isolado. Ele não interage com o sistema e não serve a nenhum propósito no DFD.
- Confundindo Entidades e Armazenamentos: Entidades externas estão fora da fronteira do sistema. Armazenamentos de dados estão dentro. Não coloque um símbolo de entidade externa dentro da fronteira do sistema, como se fosse um banco de dados.
🛠️ Implicações na Implementação
A distinção entre processo e armazenamento influencia como o sistema é construído. Processos mapeiam para funções, métodos ou microsserviços. Armazenamentos de dados mapeiam para tabelas, arquivos ou armazenamento de objetos.
🔹 Projeto de Banco de Dados
Ao projetar um banco de dados, os armazenamentos de dados no DFD tornam-se o plano mestre do esquema. Os atributos nas setas de fluxo de dados definem as colunas. As relações entre armazenamentos (mediadas por processos) definem chaves estrangeiras ou links transacionais.
🔹 Automação de Fluxo de Trabalho
Para motores de fluxo de trabalho, os processos representam os passos em uma pipeline. Armazenamentos de dados representam o estado do fluxo de trabalho. Um processo pode atualizar o estado no armazenamento para marcar uma tarefa como concluída. Compreender a natureza passiva do armazenamento garante que o motor de fluxo de trabalho espere pelo estado correto antes de prosseguir.
🔍 Padrões de Representação Visual
Metodologias diferentes usam símbolos ligeiramente diferentes, mas a lógica permanece consistente.
- DeMarco & Yourdon: Usa retângulos arredondados para processos e retângulos abertos para armazenamentos de dados.
- Gane & Sarson: Usa retângulos arredondados para processos e linhas paralelas para armazenamentos de dados.
Independentemente da notação escolhida, o significado semântico é idêntico. Um processo atua; um armazenamento mantém. A consistência na documentação do projeto é mais importante do que seguir uma norma específica, desde que a equipe compreenda a convenção escolhida.
🎯 Resumo dos Papéis
Construir um modelo de sistema robusto exige disciplina na atribuição de papéis. O processo é o ator. Ele realiza o trabalho. O armazenamento de dados é o palco. Ele mantém os acessórios. Sem o ator, o palco está vazio. Sem o palco, o ator não tem onde colocar seus resultados.
Mantendo uma separação clara entre transformação e armazenamento, os analistas criam diagramas que não são apenas visualmente atraentes, mas também logicamente sólidos. Esses diagramas servem como um contrato entre os stakeholders do negócio e as equipes técnicas. Eles definem os limites de responsabilidade e o fluxo de valor.
Ao revisar um DFD, faça duas perguntas para cada símbolo: “Este está realizando trabalho?” (Processo) ou “Este está armazenando informações?” (Armazenamento). Se a resposta for ambígua, refine a etiqueta ou a conexão. A clareza é o objetivo final da modelagem de sistemas.
Aderir a esses princípios garante que a arquitetura resultante seja mantida, escalável e compreensível. A distinção é simples, mas seu impacto na integridade do sistema é profundo.