











セキュリティはしばしば、既存のシステムの上に重ねられたツールやプロトコルの集合体と見なされる。ファイアウォールや暗号化は確かに重要だが、これらは反応型の対策である。真のセキュリティは、アーキテクチャそのものを理解することから始まる。システムアーキテクチャを可視化し、保護する最も効果的な方法の一つがデータフローマッピングである。このプロセスは、情報がシステム内でどのように移動するかを視覚的に表現し、情報の発生源、移動経路、最終的な保管場所を特定することを含む。
セキュリティ分析に適用すると、データフローマッピングは静的防御から動的観察への視点の転換をもたらす。脆弱性が隠れている可能性のある経路を明らかにし、攻撃者がその脆弱性を悪用する前にリスクを評価できるようにする。データの移動経路をマッピングすることで、組織は最も重要な接続点でより厳格な制御を実施できる。このアプローチは、デジタルインフラにおける信頼性と整合性の基盤を築く。
📊 セキュリティにおけるデータフローダイアグラムの理解
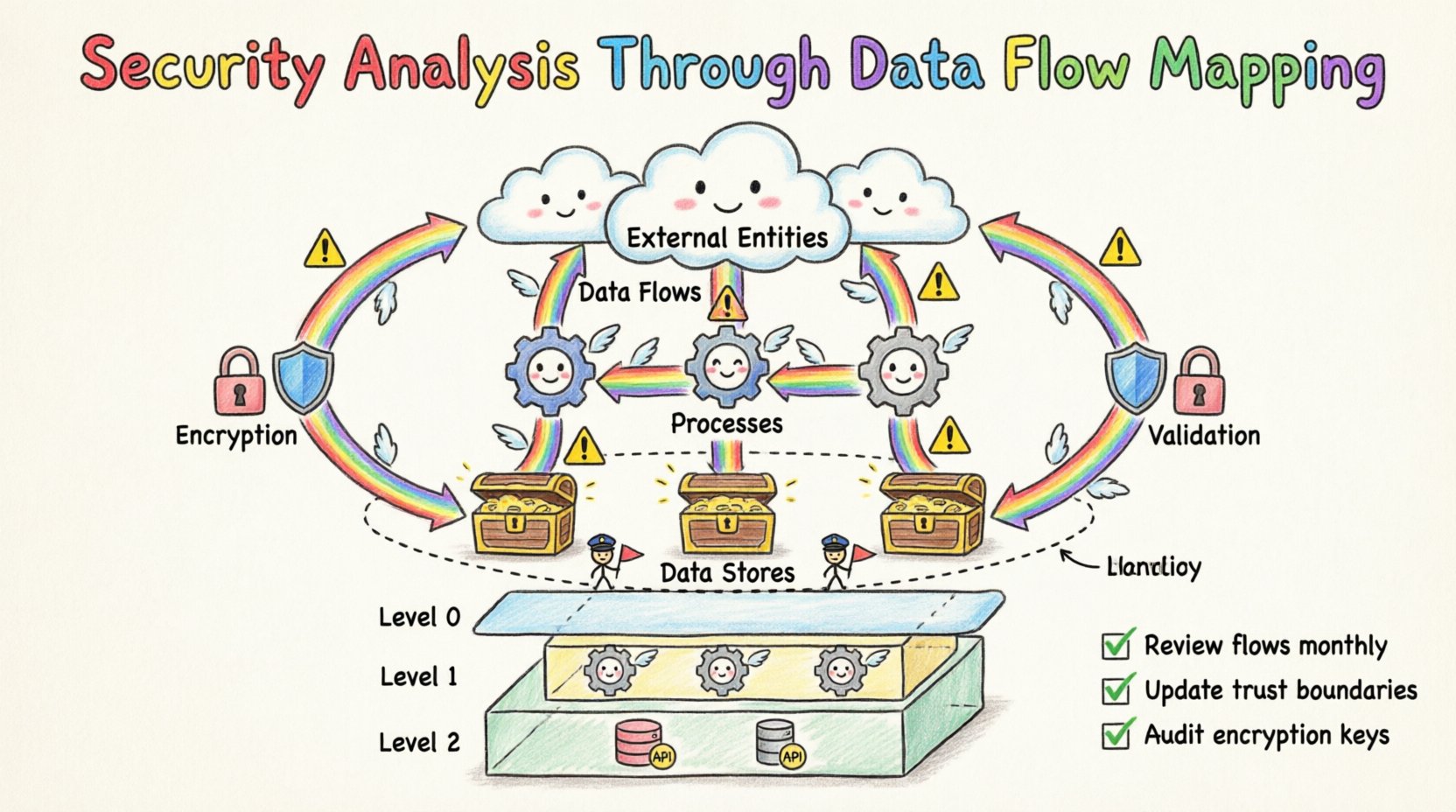
データフローダイアグラム(DFD)は、システムの構造化された表現である。DFDはプロセスのタイミングや論理ではなく、データの移動に注目する。セキュリティの文脈では、DFDはリスク評価のための設計図となる。根本的な問いに答える:このデータにアクセスするのは誰か?どこへ向かうのか?静的状態での暗号化は行われているか?送信中も暗号化されているか?
標準的なDFDは通常、4つの主要な構成要素で構成される。各構成要素は、防御的視点から分析された際に、特定のセキュリティ上の意味を持つ。
- 外部エンティティ: これらはシステム境界外のデータの発生源または到着地である。セキュリティの観点から、これらはユーザー、クライアント、またはサードパーティサービスを表す。すべての外部エンティティは、悪意ある攻撃者にとって潜在的な侵入ポイントをもたらす。これらのエンティティの身元と承認状態を検証することは、第一の防御ラインである。
- プロセス: これらはデータを変換するアクションである。プロセスは入力の検証、値の計算、アラートの発動などを行う可能性がある。セキュリティの観点から見ると、プロセスは論理的な脆弱性が存在する場所である。入力のクリーニングが行われない場合、インジェクション攻撃が可能になる。アクションのログ記録が行われない場合、不正な変更が検出されずに済む可能性がある。
- データストア: これらはデータが一時的に保管されるリポジトリである。データベース、ファイルシステム、メモリバッファのいずれであっても、データストアは高価値の標的となる。ここでのセキュリティ分析は、アクセス制御、暗号化基準、バックアップの整合性に焦点を当てる。データストアへの不正アクセスは、多くの場合、侵害の主な目的となる。
- データフロー: これらはコンポーネントをつなぐ矢印であり、データの移動を表す。これはセキュリティマッピングにおいて最も重要な要素である。データフローは露出の有無について厳密に検証されるべきである。機密データが暗号化されていないチャネルを経由して送信されているか?検証なしに信頼度の低い環境を通過しているか?すべてのフローは、潜在的な傍受ポイントを表している。
🔍 セキュリティマッピングの手法
安全なデータフローマップを作成するには、構造的なアプローチが必要である。ボックスの間に線を引くだけでは不十分である。マップは、実際に存在する論理構造とセキュリティ制御を反映しなければならない。このプロセスは通常、トップダウンの分解戦略に従う。ステップ1:範囲と境界の定義
まず、システム境界を定義する。システム内部と外部はどこか?この区別が、セキュリティ制御を適用すべき場所を定義する。境界外のすべてのものは、信頼できないものと仮定される。内部システムと外部エンティティの境界は、認証と承認のチェックが行われるべき場所である。ステップ2:外部エンティティの特定
アプリケーションとやり取りするすべてのユーザー、システム、デバイスをリストアップする。信頼度レベルごとに分類する。内部サービスは、公開向けAPIよりも信頼度が高い可能性がある。この分類により、セキュリティ監視の優先順位を決定できる。高信頼度のエンティティであっても検証は必要だが、公開クライアントとは異なる厳しさで検証される。ステップ3:データフローのマッピング
データの入力から出力までの経路を追跡する。ログインリクエストやファイルアップロードなどの初期入力を起点とする。データがすべての変換および保存ポイントを通過する様子を追う。すべての矢印にデータタイプを説明するラベルを付けること。ここでは、パスワードやクレジットカード番号などの機密情報が、ログやエラーメッセージに漏洩していないかを特定する。ステップ4:データの機密性のラベル付け
すべてのデータが同じレベルの保護を必要とするわけではない。機密性に基づいてデータフローを分類する。公開データ、内部ビジネスデータ、規制対象データはそれぞれ異なるセキュリティ要件を持つ。健康記録や個人識別情報などの規制対象データを含むフローには、特定の取り扱いプロトコルをマークする。これにより、法律フレームワークへの準拠を確保しつつ、公開データの取り扱いを過剰に設計することを防ぐ。ステップ5:信頼境界の特定信頼境界とは、セキュリティ制御のレベルが変化する論理的な境界である。クライアントアプリケーションとサーバーの間に典型的な境界が存在する。また、ウェブサーバーとデータベースサーバーの間に境界が存在する可能性もある。信頼境界を越えるには、検証、暗号化、しばしば認証が必要である。すべてのフローが適切なチェックを経ずに越えないように、これらの境界を明確にマッピングする。
⚠️ フロー分析によるリスクの特定
マップが完成したら、次の段階はリスクの特定である。これは、図面を見て、各ノードや接続で何が間違える可能性があるかを問うプロセスである。この手法は、しばしば脅威モデリングの手法と一致する。
主要なリスクカテゴリ
| リスクカテゴリ | 説明 | DFDインジケータ |
|---|---|---|
| 不正なアクセス | 許可されていないエンティティがデータにアクセスしている。 | 認証ノードのない、信頼度の低いエンティティから発生するフロー。 |
| データ改ざん | データが転送中または保存中に改ざんされている。 | 整合性チェックやデジタル署名のないフロー。 |
| 情報漏洩 | 機密データが許可されていない第三者に開示されている。 | 暗号化ラベルのないパブリックネットワークを通過するフロー。 |
| サービス拒否 | リソースの枯渇によりシステムが利用不可になる。 | 入力検証やレート制限の指標のないプロセス。 |
| 特権の昇格 | ユーザーが割り当てられた権限を超えてアクセスする。 | ロールチェックのない管理者機能を処理するプロセス。 |
これらのカテゴリに基づいて図面を分析することで、脆弱なポイントを特定できる。たとえば、ユーザーインターフェースから中間プロセスを経ずにデータベースへ直接データフローが移動している場合、ビジネスロジックの検証が欠けている可能性がある。これはインジェクション攻撃の重大なリスクである。同様に、データストアに資格情報が含まれているが、そのストアへのフローに暗号化の指示がない場合、ストレージメカニズムは脆弱である可能性が高い。
🔒 バウンダリ制御によるセキュリティ強化
データフローマップにおけるセキュリティ分析の主な目的は、境界を強化することである。データが境界を越えるたびにリスクが増加する。したがって、図面はこれらの交差点における厳格な制御の実装をガイドすべきである。
暗号化要件
信頼境界を越えるすべてのデータフローは暗号化されるべきである。図面は、暗号化が必要な場所を明確に示すべきである。これは、転送中のデータに対するトランスポート層暗号化およびサービス間を移動するデータに対するアプリケーション層暗号化を含む。フローが「パブリック」とマークされている場合、暗号化は不要な場合もあるが、機密性について監査される必要がある。フローが「機密」とマークされている場合は、暗号化が必須である。
入力検証
プロセスはデータ整合性のゲートキーパーである。検証が行われる場所を図面が強調すべきである。外部エンティティからデータを受け取るプロセスは、そのデータの形式、長さ、内容を検証しなければならない。これにより、不正なデータがシステムを破壊したり脆弱性を引き起こしたりするのを防ぐことができる。DFDは、データがデータストアに進入する前に検証チェックポイントを示すべきである。
ログ記録とモニタリング
セキュリティは予防だけでなく検出も含む。データフローはログ記録が行われる場所を示すべきである。重要なプロセスは監査ログを生成すべきである。データフローが金融取引を含む場合、DFDは将来のレビューのために取引詳細を記録するプロセスを示すべきである。これにより、侵害が発生した場合、攻撃者の経路を追跡できるようになる。
📑 レベルによる複雑さの管理
システムが拡大するにつれて、単一の図面は使いにくくなるほど複雑になる。これを管理するために、セキュリティアナリストは抽象化のレベルを使用する。これにより、初期の概要を圧倒することなく、詳細な分析が可能になる。
- レベル0(コンテキスト図):システムを単一のプロセスとして表示し、外部エンティティとの相互作用を示す。これは高レベルのセキュリティ範囲の定義に使用される。以下の問いに答える:システムとは何か、誰とやり取りしているのか?
- レベル1:主要プロセスをサブプロセスに分解する。このレベルは、主要なセキュリティ境界やデータストアを特定するのに役立つ。システムを機能モジュールに分割する。
- レベル2: レベル1のプロセスをさらに詳細に分解する。このレベルは、詳細なセキュリティ制御の実装に不可欠である。複雑なモジュール内の具体的なデータ変換および格納メカニズムを明らかにする。
複数のレベルを用いることで、セキュリティチームが適切な粒度に注目できることが保証される。上位のマネージャーはリスクプロファイルを理解するためにレベル0の図を確認するかもしれない。開発者は自分の関数がデータを安全に扱っているかを確認するためにレベル2の図を確認するかもしれない。この階層構造により、複雑なアーキテクチャにおけるセキュリティの見落としを防ぐことができる。
🔄 メンテナンスと反復
データフローマップは一度きりの成果物ではない。システムは進化する。新しい機能が追加され、古いコンポーネントは廃止される。マップが現在の状態を反映していない場合、セキュリティ分析は不正確になる。古くなったマップは、現在は露出しているセキュアなパスを示す可能性があり、あるいは最近の変更によって導入された新しい脆弱性を隠す可能性がある。
組織はデータフローマップを動的な文書として扱うべきである。アーキテクチャが変更されるたびにマップを更新すべきである。これは、新しい機能の設計フェーズ中にマップを更新することを含む。マップを開発ライフサイクルに統合することで、セキュリティは最終的なチェックではなく、継続的な活動となる。
メンテナンスのベストプラクティス:
- バージョン管理: 図面をコードと一緒にリポジトリに保存する。これにより、マップがデプロイバージョンと一致することを保証する。
- レビュー周期: データフローマップの定期的なレビューをスケジュールする。安定したシステムでは四半期ごとのレビューで十分なことが多いが、急速に変化するシステムは月次更新が必要な場合がある。
- ステークホルダーの関与: アーキテクト、開発者、セキュリティアナリストがすべて最新版にアクセスできるようにする。マップとコードの不一致は、セキュリティ負債の赤信号である。
🛡️ コンプライアンスおよび監査支援
規制フレームワークは、組織がデータをどのように保護しているかを証明することをしばしば求めている。GDPR、HIPAA、PCI-DSSなどの標準は、データ保護措置を義務づけている。適切にメンテナンスされたデータフローマップは、監査時に強力な証拠となる。
監査官がデータがどのように保護されているか尋ねたとき、マップは視覚的な回答を提供する。データの経路と各ステップで適用された制御を示す。これにより、証拠収集に費やす時間が削減され、ステークホルダーにセキュリティポジションが明確に伝わる。また、コンプライアンスが不足している可能性のあるギャップを特定するのにも役立つため、監査が行われる前に問題を是正できる。
たとえば、規制でデータの永続的保存時に暗号化が求められている場合、マップにはデータストアが表示され、暗号化が有効であることを示す必要がある。規制で一定期間後にデータを削除することが求められている場合、マップには保持プロセスが表示されるべきである。文書と現実との整合性は、規制当局および顧客との信頼関係を築く上で不可欠である。
🚀 結論
データフローマッピングによるセキュリティ分析は、レジリエントなシステムを構築するための基盤的な実践である。抽象的な概念から具体的なアーキテクチャへの議論を移行する。データの動きを可視化することで、チームはリスクを早期に特定し、最も重要な場所に制御を適用できる。
このアプローチは他のセキュリティ対策を置き換えるものではない。ツールを効果的に適用するための文脈を提供することで、それらを補完する。ファイアウォールは、どのトラフィックフローを検査すべきかを正確に把握している場合、より効果的になる。暗号化は、機密データがどこを通過するかを正確に把握している場合、より有用になる。データフローマッピングはその文脈を提供する。
正確な図面の作成と維持に時間を投資することは、リスク低減の恩恵をもたらす。セキュリティを反応型の負担から、予防型の戦略へと変える。システムがより分散化・複雑化する中で、データフローマッピングが提供する明確さは、さらに価値が高まる。データがライフサイクル全体を通じて安全であることを保証するための、最も信頼性の高い方法の一つとして、今もなおその役割を果たしている。