











信頼性の高いシステムを設計するには、単にコンポーネントを視覚的に接続するだけでは不十分であり、厳密な論理検証が求められる。データフローダイアグラムを構築する際、情報の移動を視覚的に表現するだけでは、その背後にある論理が正しければ意味がある。この設計段階での誤りは、後に重大な運用上の失敗へと波及する可能性がある。本ガイドでは、フローデザイン内の論理エラーを特定・修正する方法について詳しく解説し、データの整合性とプロセスの信頼性を確保する。 🧠
フローデザインの基盤を理解する 🏗️
エラーを特定する前に、標準的なデータフローダイアグラムの構造を理解する必要がある。これらの図は、システム内を移動するデータの流れをマッピングし、外部エンティティ、プロセス、データストア、およびそれらを結ぶフローを強調する。主な目的は、情報がシステムに入力され、変換され、出力される様子を可視化することである。これらの動きを支配する論理に問題があると、結果として得られるシステムアーキテクチャは不安定になる。
論理エラーは構文エラーとは異なる。構文エラーは、図が技術的に描画または検証できない状態を引き起こす。一方、論理エラーは図が正しく描かれているが、不可能または非効率的な現実を表していることを意味する。たとえば、出力が明確に定義されていないにもかかわらず、入力を受けるプロセスが描かれている、あるいはデータが空から出現しているといった状況である。このような異常は、情報の論理的な流れを乱す。
図がビジネスルールおよびデータ保存の法則を正確に反映していることを確認することが極めて重要である。プロセスに入力されるすべてのデータは、変換され、保存され、または次のステップに渡されるべきである。明確なメカニズムがなければ、何もない状態からデータが生成されたり、消失したりしてはならない。この原則こそが、フローデザインにおける論理的一貫性の基盤である。
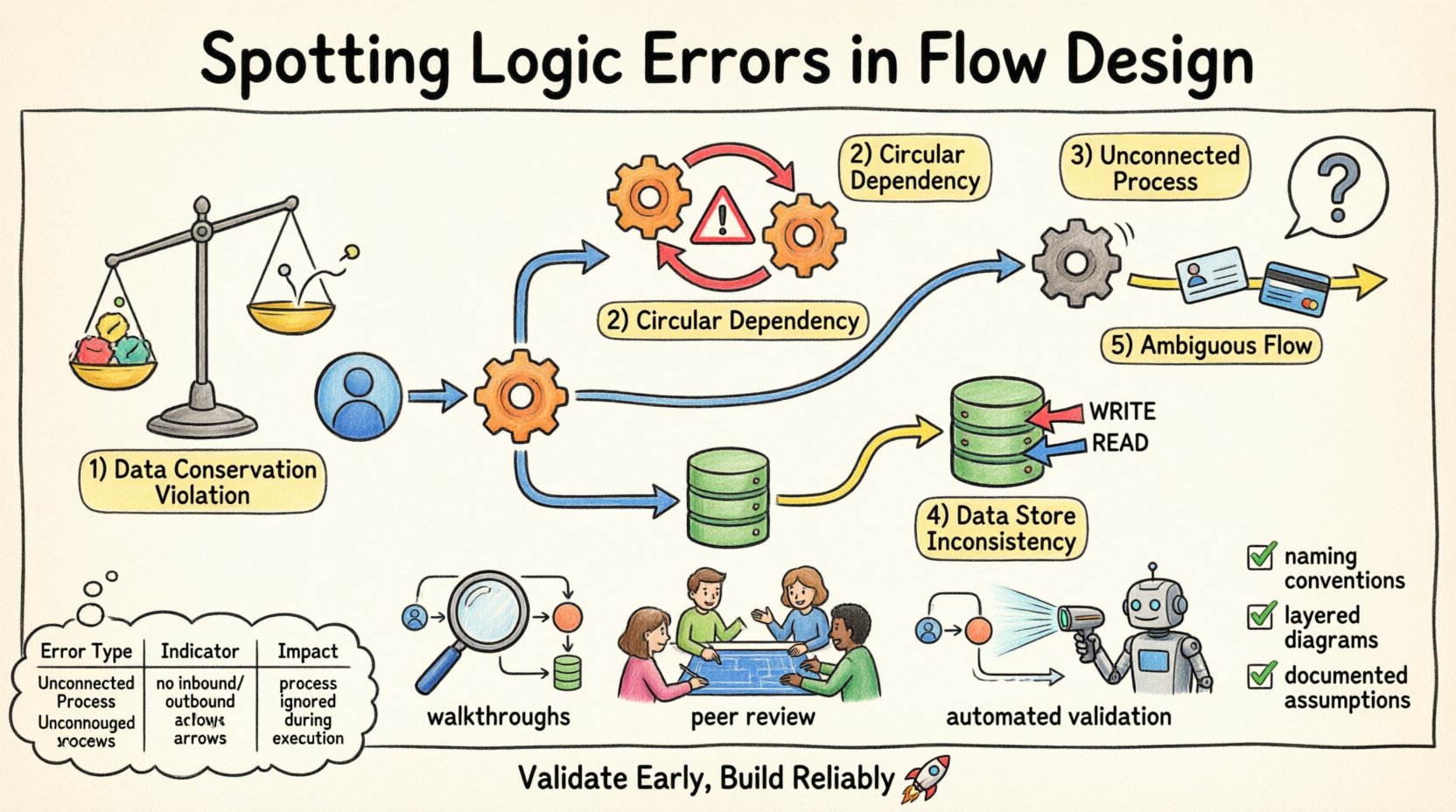
検出すべき論理エラーの種類 🔍
論理エラーは、フローデザイン内でさまざまな形で現れる。これらのカテゴリを認識することで、体系的なレビューが可能になる。以下は、設計段階で頻繁に出現する主な論理的不整合の種類である。
1. データ保存則の違反 📉
データ保存則は、プロセス内でデータが生成されたり破壊されたりしてはならないと規定している。フローダイアグラム上で、明確な出所のないデータがプロセスから出現している場合、この法則に違反している。逆に、データがプロセスに入力され、保存されたり出力されたりせずに消失している場合、データは失われたことになる。これは、設計者が出力矢印を描くのを忘れることが原因でよく起こる。
たとえば、顧客注文プロセスが注文詳細を受け取るが、確認受領書しか出力しない場合、支払い情報が欠落している。これは論理上のギャップを示している。システムはすべての入力と出力を考慮しなければ機能しない。
2. 円環依存 🔄
円環依存とは、プロセスAがプロセスBにデータを供給し、プロセスBがそのデータをプロセスAに再び供給するが、中間ステップがない状態を指す。静的図では、これを見るとループのように見える。時間ベースのシステムではループが存在するが、論理フローデザインでは、この状態はデッドロックやシステムが解決できない無限再帰を示すことが多い。
このような依存関係を特定するには、データの経路を追跡する必要がある。あるプロセスが、自分自身が待っているプロセスの出力に依存しているプロセスの出力に依存している場合、フローは停止する。これはシステム実行を停止する重大な論理エラーである。
3. 未接続プロセス 🚫
未接続プロセスとは、入力データフローを持たないプロセスを指す。入力がなければ、プロセスは実行できない。これは論理的な島である。同様に、出力フローを持たないプロセスは、システム全体の出力に貢献しない。内部プロセスは外部出力が直接不要な場合もあるが、最終的にはデータストアまたは外部エンティティに到達する連鎖に繋がる必要がある。
孤立したプロセスは、設計が不完全であることを示唆する。リソースを消費するが、価値を生まない。このようなプロセスを発見するには、図内のすべてのノードについて接続性の分析が必要である。
4. データストアの不整合 🗄️
データストアは永続的な情報を表す。プロセスが適切な承認や文脈なしにデータストアから読み取りまたは書き込みを行うと、論理エラーが生じる。たとえば、ユーザーが権限を持っているか確認せずにレコードを更新するプロセスが存在する、あるいは、まだ実行されていない別のプロセスによってのみ書き込まれるデータを読み取ろうとする場合などである。
もう一つの一般的な問題は、異なるプロセスが同期なしに同じデータストアを同時に読み書きすることである。これにより、論理モデル上でレースコンディションが発生する。図には、明確な書き込みパスと読み取りパスを示すことで、曖昧さを避ける必要がある。
5. 不明確なデータフロー 🌫️
データフローは明確に名前を付けて説明されるべきである。不明確なフローとは、区別なく複数の種類のデータを運ぶものである。たとえば、1つの矢印が「ユーザーID」と「クレジットカード番号」の両方を表している場合、論理が誤っている。なぜなら、これらのデータ要素は異なるセキュリティ要件と処理要件を持つからである。
これらのフローを分離することで、各情報がその特定のルールに従って処理されることを保証できる。曖昧さは、セキュリティ上の脆弱性や、下流での処理エラーを引き起こす。
| エラーの種類 | 兆候 | 影響 |
|---|---|---|
| データ保存則 | データが出現・消失する | データ損失または破損 |
| 円環依存 | プロセスA → プロセスB → プロセスA | システムのデッドロック |
| 未接続プロセス | 入力または出力の矢印がない | リソースの浪費 |
| データストアの不整合 | 制御のない読み取り/書き込み | データ整合性の問題 |
| 曖昧なデータフロー | 1つのフローに混在するデータ型 | セキュリティリスク |
検出のための手法 🛡️
エラーの種類が分かれば、次にそれらを発見するための手法を確立する必要があります。単なる受動的なレビューではしばしば不十分です。図の積極的な検証が求められます。
ステップバイステップのウォークスルー 🚶
図を頭の中で一歩ずつ確認してください。外部エンティティから始めて、データがすべてのプロセスを経由してデータストアまたは別のエンティティに至るまで追跡します。各ノードで質問を投げかけましょう。このプロセスは実行に必要な入力を持っているか?期待される出力を生成しているか?もし私がこの論理を実行したら、データはどこへ行くだろうか?
この手作業による追跡は、設計者がデータの動きを動的に可視化するよう強制します。静的な視点では見逃されがちなギャップを明らかにします。ウォークスルーがノードで止まってしまう場合、その場所に論理エラーがある可能性が高いです。
同僚レビュー会議 👥
別の人が図を見ることで、新鮮な視点が得られます。レビュアーは、設計者が慣れ親しんだことで見逃しているエラーを発見できます。仮定を疑問視するよう促しましょう。不要または欠落しているデータフローを見つけ出してもらうように依頼してください。
構造化されたレビュー会議は見落としの可能性を低めます。これらのレビューでは、すべてのエラーカテゴリがカバーされていることを確認するためにチェックリストを使用すべきです。
自動検証ルール 🤖
ここでは特定のソフトウェアは名指しされていませんが、論理検証ツールは図の構造的エラーをスキャンできます。これらのツールは、接続されていないノード、欠落しているデータストア、または循環参照を検出できます。基本的な論理的不整合に対する第一の防衛線として機能します。
自動チェックを使用することで、チームは構造的な文法よりも上位レベルの論理に集中できます。複雑性を追加する前に、基盤がしっかりしていることを保証します。
論理的無視のコスト 💸
なぜこれが重要なのか?設計段階での論理エラーは、最も修正コストが高いです。論理的な欠陥がコーディング段階で発見された場合、モジュールの再書き直しが必要になります。デプロイ後であれば、パッチ適用やデータ移行を伴う可能性があります。
データフローに検証ステップが欠けている状況を考えてみましょう。これにより無効なデータがシステムに流入します。その後、このデータから生成されたレポートは不正確になります。ビジネスは誤った情報をもとに意思決定を行います。このデータを修正し、信頼を回復するコストは、当初の図の修正コストよりもはるかに高くなります。
さらに、論理エラーはセキュリティ侵害を引き起こす可能性があります。フローがセキュリティチェックを回避できるようにすると、機密情報が暴露されます。これはコンプライアンス違反や法的結果を招く可能性があります。これらのエラーを防ぐことは、単なる効率性の問題ではなく、リスク管理の観点からも重要です。
予防の戦略 🛡️
予防は検出より優れています。フローデザイン作成段階で標準や実践を導入することで、エラーが発生する可能性を根本的に低減できます。
標準化された命名規則 🏷️
プロセス、データストア、フローに対して厳格な命名規則を設けましょう。プロセス名は動詞+名詞の組み合わせ(例:「注文検証」)とします。フロー名はデータの内容を説明するもの(例:「注文詳細」)とします。この一貫性により、異常を発見しやすくなります。フロー名が「データ」とだけある場合は、おそらくあまりにも曖昧であり、厳密に検討すべきです。
一貫した命名は自動検証にも役立ちます。スクリプトは名前を解析して、論理構造に準拠しているかを確認できます。
階層化された図示法 📑
複雑なシステムを複数のレベルに分けて表現しましょう。レベル0は高レベルのプロセスを示します。レベル1では、これらのプロセスをサブプロセスに分解します。この階層的なアプローチにより、図がごちゃごちゃになるのを防ぎます。ごちゃごちゃした状態は論理エラーを隠蔽します。
特定の領域にズームインすることで、設計者は全体像を失うことなく、特定のサブシステムの論理に集中できます。焦点を当てた視点では、エラーがより見つけやすくなります。
仮定の文書化 📝
すべての図には仮定が伴います。それらを明確に文書化しましょう。プロセスがデータが常に存在すると仮定している場合、その仮定を明記してください。フローが時間遅延を示唆している場合も、それを記録してください。この文書化はレビュアーに文脈を提供します。特定の論理的選択がなぜされたのかを明確にします。
仮定が文書化されれば、それらはビジネス要件に基づいて検証・検証可能になります。これにより、最終設計に隠れた論理エラーが残る可能性が低くなります。
検証チェックリスト ✅
フローデザインを最終化する前に、このチェックリストを確認してください。論理エラーが通常隠れている重要な領域を網羅しています。
- 入力の完全性:すべてのプロセスに少なくとも1つの入力フローがありますか?
- 出力の完全性:すべてのプロセスに少なくとも1つの出力フローがありますか?
- データのバランス:プロセス間でデータ量が保存されていますか?
- 行き止まりのない設計:データストアや外部エンティティに接続されていないプロセスは存在しますか?
- 明確な命名:すべてのフローとプロセスが説明的名前で命名されていますか?
- セキュリティ:機密データのフローは明確にマークされ、論理的に保護されていますか?
- 時間依存性:タイミング依存関係が明確に定義されていますか?
- 一貫性:データストアの内容は、プロセスで使用されるデータと一致していますか?
設計の最適化 🎯
エラーが発見されると、最適化プロセスが開始されます。これは論理を修正するために図を変更することを意味します。すべての要素を削除する必要があるわけではなく、時には欠けている接続を追加する必要がある場合もあります。
たとえば、プロセスに出力がない場合、データがどこへ行くべきかを確認します。適切なデータストアまたはエンティティに欠けている矢印を追加してください。循環依存関係がある場合は、ループを解除するためにバッファまたはキューを導入します。これにより、設計に中間ステップを追加する必要が生じるかもしれません。
最適化は反復的です。変更を行った後は、再びウォークスルーとチェックリストを実行してください。新しい論理が検証に耐えうるか確認してください。図がすべての検証ステップを通過するまでは、修正が完了したと仮定してはいけません。
論理的整合性についての最終的な考察 💡
フロー設計の整合性がシステムの成功を左右します。論理エラーは微細ではあるものの、破壊的です。全体のアーキテクチャの信頼性を損ないます。厳密な検出手法と予防戦略を適用することで、意図した通りに動作するシステムを設計者が構築できます。
設計段階での細部への注意は、後続の段階で時間、費用、労力を節約します。適切に検証された図は、安定したシステムの設計図です。論理的一貫性を優先することで、データが組織内で正しく、安全かつ効率的に移動することを保証します。このアプローチにより、単に機能するだけでなく、変化に耐える強靭なシステムが実現されます。 🚀
明確さと正確さに注目し続けましょう。すべての矢印が重要です。すべてのノードが意味を持ちます。これらの原則に従うことで、フローデザインは開発チームにとって信頼できる資産になります。