








データフローダイアグラム(DFD)は情報システムの設計図として機能する。これらはプロセス、データストア、外部エンティティ、およびデータ自体の間でのデータの移動をマッピングする。適切に構築された図は、データがどこへ行くかを示すだけでなく、システムアーキテクチャの論理、整合性、セキュリティを明らかにする。この記事では、厳密なモデリングが安定性と保守性の高いシステムをもたらす仕組みを示すために、3つの異なるシナリオを検討する。
🗺️ コアコンポーネントの理解
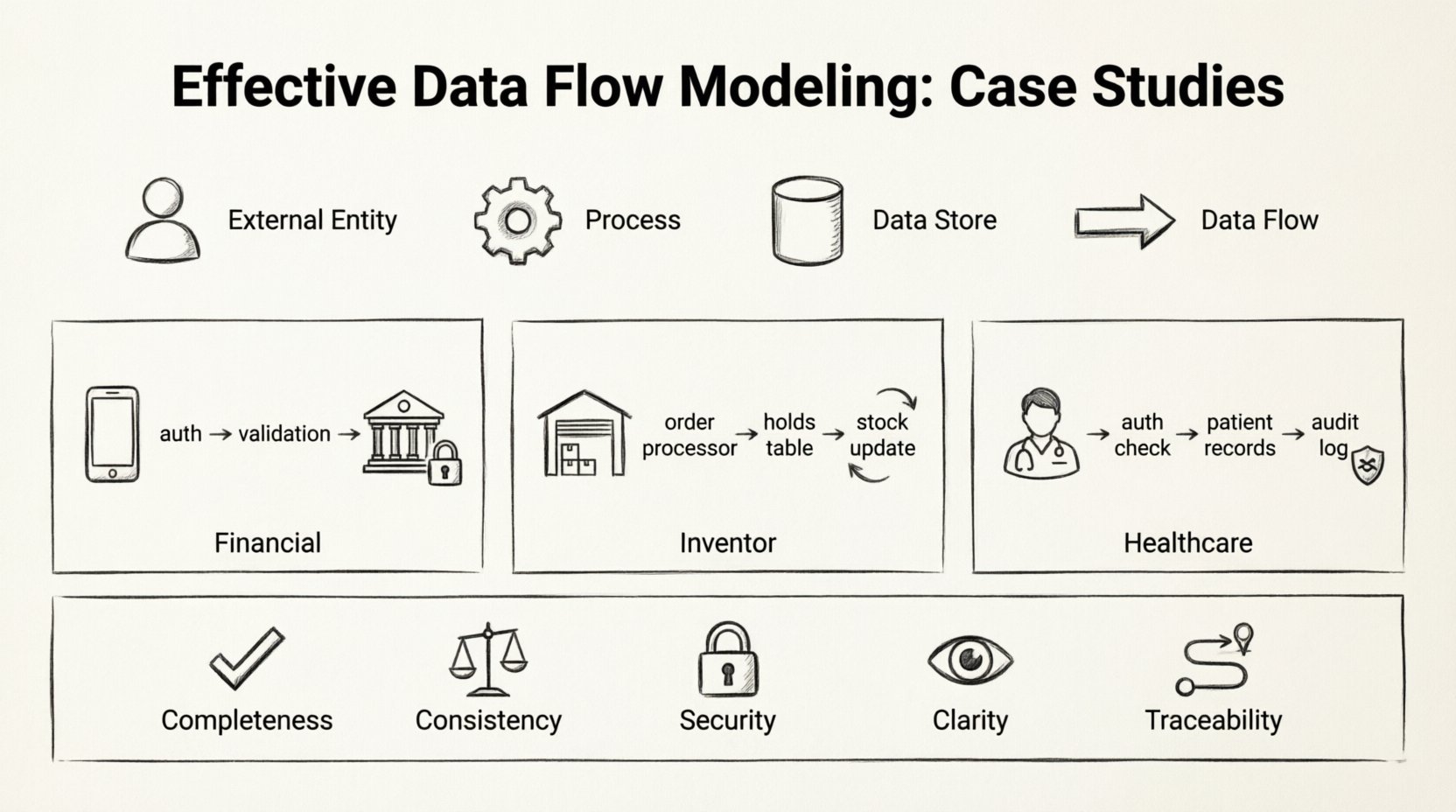
具体的な実装に移る前に、データフローモデルに関与する標準的な要素を定義することが不可欠である。これらのコンポーネントは、業界やシステムの複雑さに関係なく一貫して保持される。
- 外部エンティティ:システム境界外のデータの発生源または到着先。これらはユーザー、他のシステム、または規制機関である可能性がある。
- プロセス:入力データを出力データに変換する処理。すべてのプロセスには最低1つの入力と1つの出力が必要である。
- データストア:後で使用するためにデータを保持する場所。データベース、ファイルシステム、または物理的なアーカイブを含む。
- データフロー:コンポーネントを結ぶ矢印で、データ移動の方向と内容を示す。
これらの要素を正確に表現することは極めて重要である。たとえば、データストアをプロセスと誤ってラベル付けすると、データが永続化される場所と変換される場所についての混乱を招く可能性がある。
🏦 ケーススタディ1:金融取引処理
金融業界は、データの整合性とセキュリティに関する高い正確性を要求する。このシナリオでは、モバイルアプリケーションから銀行のコアシステムへの支払い要求を処理するように設計されたシステムを検討する。
🔍 システムの文脈
主な目的は、特定の条件が満たされた場合にのみ資金が移動することを保証することである。システムは資金の検証、ユーザーの身元確認、および監査目的での取引記録を実行しなければならない。
🔄 データフローの分解
モデリングプロセスは、システムの高レベルな視点を提供するレベル0図から始まった。これにより、3つの主要なプロセスが明らかになった:認証, 検証:、および記録.
- 認証:ユーザーが送金を開始すると、その資格情報がセキュリティサービスに送信される。システムはユーザーのステータスを「アクティブユーザー」データストアと照合する。
- 検証: 認証が完了すると、リクエストは検証プロセスに移行します。ここでシステムは、口座残高 ストアにアクセスして十分な資金があるか確認します。また、取引制限 テーブルを確認します。
- 記録: 検証が成功すれば、取引は取引ログ データストアに記録されます。口座残高 が更新され、確認信号がユーザーに送信されます。
このモデルにおける重要な決定は、検証 と記録 プロセスの分離でした。これらを統合すると単一障害点が生じます。分離することで、ネットワークの切断が発生した場合でも、永続的なログを損傷せずに検証状態をロールバックできるようになります。
📊 コンポーネントマッピング
| コンポーネント | 種類 | システム内での役割 |
|---|---|---|
| モバイルアプリ | 外部エンティティ | リクエストを開始し、確認を受け取ります。 |
| セキュリティサービス | プロセス | 保存されたハッシュと照合して資格情報を検証します。 |
| 口座残高 | データストア | 現在の資金を読み取り、新しい合計を書き込みます。 |
| 取引ログ | データストア | すべての移動の記録を変更できない状態で保持する。 |
📦 ケーススタディ2:在庫管理システム
在庫システムは、複数の場所間で同期が必要である。ここでの課題は、単にデータを移動することではなく、物理的な在庫の状態がリアルタイムでデジタル記録と一致することを保証することにある。
🔍 システムの文脈
このシステムは、倉庫管理端末とオンライン販売ポータルを接続している。データは双方向に流れ、販売は在庫を減らし、入庫は在庫を増やす。過剰販売を防ぐために、モデルは並行処理を処理しなければならない。
🔄 データフローの分解
レベル1の図は、次の要素を含む複雑な相互作用のネットワークを明らかにした。注文プロセッサ および 在庫コントローラ.
注文が行われたとき:
- この注文プロセッサ は 在庫データベース.
- 在庫が利用可能であれば、予約トークン が作成され、一時的な ホールドテーブル.
- 注文は顧客に確認される。
- 別途のプロセス、在庫調整 は定期的に実行され、期限切れの予約を削除し、在庫データベース.
このアプローチにより、システムがクリックごとにデータベース全体をロックするのを防ぐ。一時的なホールドテーブルシステムが競合状態をブロッキングせずに管理できるようにする。
📊 同時実行処理
| シナリオ | データフローのアクション | 結果 |
|---|---|---|
| 単一ユーザー | 在庫確認 → 予約 → 確認 | 成功 |
| 2ユーザー(同じアイテム) | ユーザーAが予約 → ユーザーBが確認(在庫不足) | ユーザーBは更新された在庫数を確認する |
| 予約タイムアウト | ホールドテーブル → クリーンアッププロセス | 在庫がプールに戻される |
このモデルは、クリーンアッププロセスがなければ、ホールドテーブルは無限に増大し、メモリを消費し、クエリの実行を遅らせる。
🏥 ケーススタディ3:医療分野の患者記録
医療データモデリングはプライバシーとアクセス制御を最優先する。情報の流れは、ユーザーの役割とデータの機密性に基づいて厳密に管理されなければならない。
🔍 システムの文脈
このシステムは、クリニックネットワークの患者履歴を管理する。データには個人識別情報、医療履歴、検査結果が含まれる。モデルは、特定の記録を閲覧できるのは承認された人員に限ることを保証しなければならない。
🔄 データフローの分解
このシステムのDFDは、アクセス制御を明確なプロセス層として導入する。データは患者記録からドクターの画面へ直接流れることはない。
- リクエスト:ドクターが患者IDを選択する。
- 承認: システムは次のものを確認します:ユーザー権限 ストアがその特定のクリニックのデータに医師がアクセスできるかを確認します。
- 取得: 承認された場合、クエリエンジン は次のストアからデータを取得します:患者記録 ストア。
- ログ記録: アクセスイベントの記録が次の場所に記録されます:監査ログ データが表示される前に。
この分離により、データストアが侵害された場合でも、アクセスログが誰がどのデータを要求したかを追跡できるようになります。このモデルにおいて、監査ログ は重要なデータストアであり、しばしば医療記録そのものよりも高いセキュリティ許可が与えられます。
📊 プライバシーレベル
| 役割 | データアクセス | データフロー経路 |
|---|---|---|
| 受付担当者 | スケジュールのみ | スケジュールストア → 表示 |
| 看護師 | 生命徴候および薬剤 | 医療ストア → 承認確認 → 表示 |
| 専門医 | 完全な履歴 | 医療ストア → 承認確認 → 表示 |
図は明確に「」と「」の違いを示しています。受付担当者 と「専門家のパスです。両方とも患者にアクセスしますが、データストリームのフィルタリング方法が異なります。この細分化は、データ保護規制への準拠にとって不可欠です。
🛠️ 効果的なモデリングのための手法
成功したモデリングには、厳密なアプローチが必要です。ボックスと矢印を描くことだけではなく、ビジネスロジックを理解し、それを技術的表現に変換することが重要です。
1. スコープを明確に定義する
まず、システムの境界を明確にします。内部と外部はどこか?金融の事例では、銀行コアはモバイルアプリ層にとって外部エンティティでした。この点を明確にすることで、開発中にスコープの拡大を防げます。
2. 漸進的に分解する
まず、高レベルのコンテキスト図から始めます。次に、各プロセスをレベル1の図に展開します。プロセスが直接コード化できるほど単純になるまで分解を続けます。この階層的なアプローチにより、モデルの可読性が保たれます。
3. データストアの検証
すべてのデータストアには明確な目的が必要です。尋ねてください:なぜこのデータを保存するのか?将来のプロセスに必要か?データストアに流入または流出がない場合、それは無駄な負荷です。在庫の事例では、「保有テーブル」は、同時実行制御の必要性から正当化されました。
4. 一貫性の確認
プロセスに入力されるデータが、次のプロセスで期待されるデータと一致していることを確認してください。フォーマットの不一致やフィールドの欠落は、システムエラーの一般的な原因です。一貫性のチェックは、データフローラベル内に文書化する必要があります。
🔄 メンテナンスと進化
システムは進化するため、データフローモデルもそれに合わせて進化しなければなりません。ビジネス要件が変化した瞬間、静的な図は陳腐化します。
新しい機能を導入する際は、既存の図と照らし合わせて新しいデータフローをマッピングしてください。衝突がないか確認してください。たとえば、金融システムに通知機能を追加する場合、メール配信を処理する新しいプロセスと、メッセージテンプレート用の新しいデータストアが必要になることがあります。
DFDの定期的な監査を推奨します。実際のシステムログを計画されたデータフローと比較してください。不一致は、実装のずれか、陳腐化したモデルを示しています。モデルを更新することで、新規開発者がコードを逆構成せずにアーキテクチャを理解できるようになります。
📋 主な考慮事項の要約
以下のチェックリストにより、データフローモデルがプロジェクトのライフサイクル全体にわたり効果的かつ正確であることが保証されます。
- 完全性:すべてのプロセスに入力と出力があるか?
- 一貫性:プロセス間でデータフローのフォーマットと型が一致しているか?
- セキュリティ:機密データフローは承認プロセスによって保護されているか?
- 明確性: ラベルは説明が明確で、曖昧さがないか?
- 追跡可能性: すべてのデータがその元と先に追跡可能か?
これらの原則に従うことで、組織は堅牢で、安全かつ保守しやすいシステムを構築できる。詳細なモデル化に費やした努力は、テストおよび展開フェーズで大きな成果をもたらし、重大な障害の発生確率を低下させる。
データフローのモデリングは、システムアーキテクトにとって基盤的なスキルである。抽象的な要件と具体的な実装の間のギャップを埋める。金融取引、在庫レベル、患者記録の管理に関わらず、論理は同じである。データは正確に収集され、変換され、保存され、再取得されなければならない。これらの事例研究で確立されたパターンに従うことで、複雑な情報システムを設計するための信頼できるフレームワークが得られる。
🚀 アーキテクチャに関する最終的な考察
システムの品質は、1行のコードも書かれる前からしばしば決定される。計画段階で作成された図は、最終製品のパフォーマンスと信頼性を規定する。データの移動に注目することで、単に保存に注目するのではなく、アーキテクトはボトルネックやセキュリティ上の穴を早期に特定できる。
モデルは技術的仕様であると同時に、コミュニケーションツールであることを忘れないでください。ステークホルダーがシステムの動作を視覚化できるようにする。図が明確であれば、コードも自然に作成される。図が曖昧であれば、コードは保守の地獄となる。
これらの原則を次のプロジェクトに適用しよう。まずコンテキストから始め、プロセスを分解し、データストアを検証する。データフローのモデリングに対する規律あるアプローチは、成熟したエンジニアリング実践の証である。