











データの整合性は可視性に依存する。情報がシステム内でどのように移動するかを明確に把握できない場合、組織は目隠しで運営することになる。データラインエージの追跡は、その地図を提供するものであり、データの発生源から利用に至るまでの経路を記録する。データフローダイアグラムは、この作業の基盤となる視覚的言語として機能する。複雑な技術的プロセスを理解しやすい構造に変換することで、チームが変換や依存関係を正確に追跡できる。このアプローチにより、すべてのデータが追跡可能となり、コンプライアンス、デバッグ、戦略的意思決定を支援する。
このプロセスは、ボックスの間に線を引くこと以上のものである。基盤となるアーキテクチャ、変換を駆動する論理、関与するストレージメカニズムについての深い理解が求められる。標準化された図示技術を活用することで、技術チームはインフラ構造とともに進化する「生きている」ドキュメントを作成できる。この文書では、フローダイアグラムを用いたラインエージ追跡の実装方法について、明確性、正確性、長期的な保守性を重視して説明する。
データラインエージの理解 🧬
データラインエージとは、データの履歴を指す。データがライフサイクルを通じて経験する発生源、移動、変換を記録するものである。水が川のシステムに流れ込む一滴を想像してほしい。ラインエージは、その水がどこから来たのか、どの支流を通過したのか、最終的にどこへ流れ出たのかを追跡する。デジタル環境では、レコードを生成したデータベースのテーブル、それを処理したスクリプト、最終的な指標を表示するダッシュボードを把握することを意味する。
ラインエージを確立することは、いくつかの理由から極めて重要である。第一に、トラブルシューティングを支援する。レポート内の数値が誤っているように見える場合、ラインエージによりエンジニアは値を逆方向にたどり、誤差が発生した場所を特定できる。第二に、規制遵守を支援する。データプライバシーに関する法律は、個人情報がどこに存在し、どのように使用されているかを正確に把握することが求められることが多い。最後に、信頼を構築する。数値の背後にあるデータソースや処理ロジックを理解できれば、ステークホルダーは分析結果をより信頼するようになる。
ラインエージは主に二つのタイプに分類できる:論理的ラインエージと物理的ラインエージ。論理的ラインエージは、データの概念的な移動を記述するもので、「顧客IDが営業から請求へ移動する」などが該当する。物理的ラインエージは、具体的な技術的ステップを詳細に記述するもので、「テーブルAの列5がSQLクエリBによって抽出され、テーブルCの列3に格納される」などが該当する。フローダイアグラムは、これら二つを効果的に橋渡しする。ビジネスステークホルダーと技術エンジニアの両方のニーズを満たす視覚的表現を提供する。
データフローダイアグラムの役割 📊
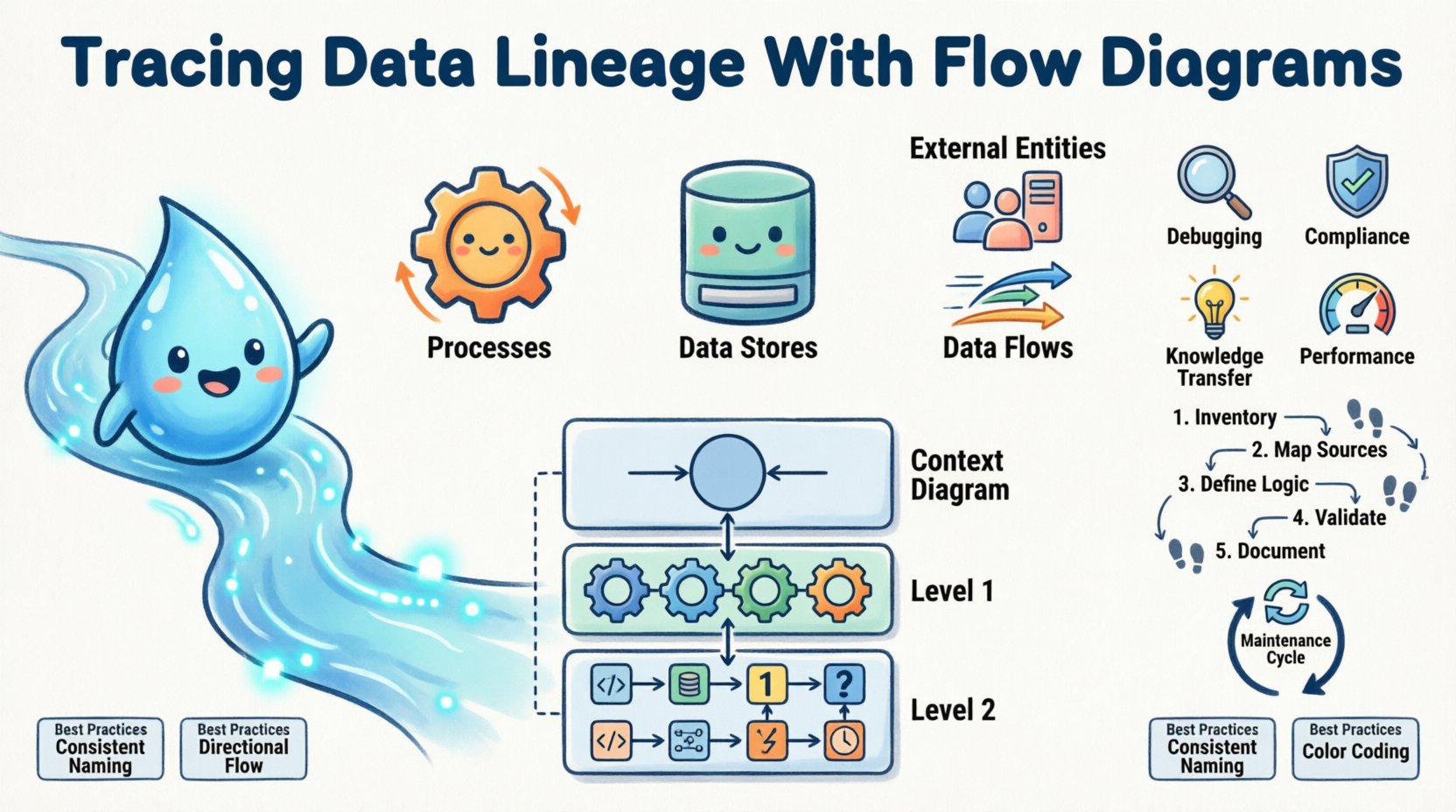
データフローダイアグラム(DFD)は、データがシステム内でどのように移動するかを視覚的に表現するものである。エンティティリレーションシップ図がデータオブジェクト間の静的な関係に注目するのに対し、DFDは情報の動的な流れと処理に焦点を当てる。複雑なシステムを扱いやすい構成要素に分解するため、ラインエージのマッピングに特に適している。
標準的なDFDは、4つの主要な要素から構成される:
- プロセス:データを変換するアクション。通常、円またはラウンドされた長方形で表される。例として「税金を計算する」や「売上データを集計する」などがある。
- データストア:データが一時的に保管される場所。開かれた長方形で、データベース、ファイル、キューなどを表す。
- 外部エントリ:システムの境界外にある情報の発生源または到着地。ユーザー、他のシステム、規制機関などがこのカテゴリに含まれる。
- データフロー: 要素を結ぶ矢印で、データ移動の方向と内容を示す。
ラインエージ追跡に使用する場合、これらの要素はより大きなグラフのノードとなる。接続関係が経路を明らかにする。DFDの標準に従うことで、一貫性が保たれる。一つの図におけるプロセスは、他の図におけるプロセスと同じ視覚的ルールに従うため、ドキュメントを確認する誰にとっても認知負荷が軽減される。
図の詳細レベル 🛠️
複雑さを管理するために、DFDはしばしば異なる抽象度のレベルで作成される。この階層構造により、ステークホルダーは全体のシステムアーキテクチャに圧倒されることなく、特定の領域に注目できる。標準的なアプローチでは、3つの深さのレベルを用いる。
| レベル | 説明 | 使用例 |
|---|---|---|
| コンテキスト図(レベル0) | システムを単一のプロセスとして示し、外部エントリとの相互作用を高レベルで概観する。 | 経営者向けの要約および高レベルのアーキテクチャ設計。 |
| レベル1図 | 主プロセスを主要なサブプロセスとデータストアに分解する。 | システム設計および主要なデータ接触ポイントの特定。 |
| レベル2図 | レベル1の特定のプロセスを、詳細なステップにさらに分解する。 | 技術的実装、コードレビュー、詳細な監査。 |
この階層的アプローチにより、図が読みにくくなるのを防ぐ。1ページにすべてのSQL結合やAPI呼び出しを表示すると、混乱する。代わりに、コンテキスト図が全体像を提示し、レベル2図はエンジニアリング作業に必要な詳細を提供する。ラインエージを追跡する際には、これらのレベルを横断的に参照することがしばしば必要となる。レベル2図のクエリは、レベル1図では単一のプロセスとして要約されることがある。
ラインエージェンス追跡の実装手順 📝
正確なラインエージェンスマップを作成するには、体系的なアプローチが必要です。急な描画は一貫性の欠如やリンクの欠落を招きます。以下のステップは、データラインエージェンスのフローダイアグラムを構築・維持するための堅牢なワークフローを示しています。
1. 既存資産のリスト化
描画する前に、何が存在するかを把握する必要があります。関与するすべてのデータベース、データウェアハウス、アプリケーションサーバー、レポートツールをリスト化してください。トランザクションシステムや外部APIなどの主要なデータソースを特定してください。このリストが図の境界を形成します。完全なリストがないと、ラインエージェンスに隙間が生じ、ガバナンス上の盲点が発生します。
2. データソースから宛先へのマッピング
ソースから始めます。データの初期エントリポイントを特定します。最初の処理ステップまでデータを追跡します。変換ロジックを文書化します。スクリプトがデータをクリーニングしていますか?ビューが特定の行をフィルタリングしていますか?この情報をプロセスレベルで記録します。最終宛先、たとえばビジネスインテリジェンスダッシュボードやアーカイブストレージシステムに到達するまで追跡を続けます。
3. 変換ロジックの定義
データはほとんど常に静的ではありません。集計、結合、計算が行われます。これらの変換がラインエージェンスの重要なポイントです。適用された具体的なルールを文書化してください。たとえば、「列XのNULL値は0に置き換えられる」や「タイムスタンプはUTCからローカルタイムに変換される」などです。この詳細レベルはデバッグに不可欠です。下流のレポートに予期しない値が表示された場合、変換ルールを知っていることで、テスト環境でエラーを再現できます。
4. 技術チームによる検証
単独で描かれた図は誤りを招きやすいです。パイプラインを構築したエンジニアやデータを使用するアナリストと図のドラフトをレビューしてください。欠落したステップや誤った仮定を特定できます。この協働により、図が理論的な設計ではなく現実を反映していることを保証します。検証は、ラインエージェンス文書の整合性を維持する上で重要なステップです。
5. メタデータの記録
図の要素にメタデータを付与してください。バージョン番号、所有者名、作成日など含まれます。データフローは時間とともに変化します。プロセスは次四半期にリファクタリングされるかもしれません。メタデータにより、図自体の履歴を追跡でき、特定の監査期間中にどのバージョンのラインエージェンスマップが有効だったかを確認できます。
構造化されたラインエージェンスの利点 🏗️
詳細なフローダイアグラムに時間を投資することで、組織全体で実質的な成果が得られます。利点は単なる文書化をはるかに超えます。
- デバッグ時間の短縮: エラーが発生した際、エンジニアは根本原因を検索する時間を短縮できます。図はガイドとして機能し、失敗の可能性が高い領域を直接示します。
- 影響分析の向上: 変更が提案された場合、たとえば列名の変更など、ラインエージェンスマップは正確にどのレポートや下流プロセスが壊れるかを示します。これにより、誤った停止を防ぎます。
- 規制対応:監査担当者はデータ取り扱いの証明を求めます。フローダイアグラムは、データプライバシーおよびセキュリティに関する要件を満たす明確で視覚的な監査証跡を提供します。
- 知識移転: 新しいチームメンバーは、システムアーキテクチャを迅速に理解できます。トライバルナレッジに頼るのではなく、図を学習することで、データが組織内でどのように流れているかを把握できます。
- パフォーマンス最適化: フローを分析することで、しばしばボトルネックが明らかになります。特定のストアやプロセスでデータが長時間待たされる場合、図は最適化の重点を置くべき場所を明確に示します。
図の維持管理 🔄
ラインエージェンスマップは一度きりの作業ではありません。システムは進化します。新しいデータソースが追加され、古いプロセスは廃止されます。図が更新されない場合、誤解を招くようになります。正確性を維持するには、変更管理に対して厳格なアプローチが必要です。
データパイプラインが変更されるたびに、図をレビューする必要があります。これはデプロイチェックリストの一部でなければなりません。新しいAPIが統合された場合、外部エンティティとデータフローを追加しなければなりません。変換ロジックが変更された場合、プロセスボックスの説明を更新しなければなりません。図をコードとして扱うことで、信頼できるリソースを維持できます。
自動化は維持管理を支援できます。一部のプラットフォームでは、メタデータリポジトリに基づいて図を生成できます。手動レビューは依然として必要ですが、自動化により視覚的表現を技術的現実と同期させる負担が軽減されます。ただし、自動化にのみ頼るとビジネスコンテキストを見逃す可能性があるため、人的監視は依然として不可欠です。
複雑性への対応 ⚖️
大手企業はしばしば複雑なデータエコシステムと向き合います。数千のテーブルや数百のプロセスがあると、単一の図は圧倒的になります。このような状況では、モジュール化が鍵となります。ラインエージェンスを論理的なドメインに分割します。売上データ、顧客データ、財務データそれぞれについて別々の図を作成し、交差する部分でリンクしますが、メインビューは焦点を絞ってください。
もう一つの課題はレガシーシステムの扱いです。古いシステムは自動トレースに必要なメタデータを欠いていることがあります。このような場合、手動での再構築が必要です。元の開発者にインタビューするか、古いドキュメントを確認してフローを推測します。これらのギャップを透明にすることが重要です。不確実な領域を図上にマークし、さらなる調査が必要な場所を示してください。
明確性を確保するためのベストプラクティス 🚀
図が目的を果たすことを確実にするために、デザインとプレゼンテーションに関する以下のガイドラインに従ってください。
- 一貫した命名規則:すべての図において、プロセスおよびデータストアに標準的な名前を使用する。読者を混乱させる省略形は避ける。
- 方向性の流れ:図を左から右、または上から下へ論理的に流れるように配置する。これは自然な読書習慣に合致する。
- 色分け:色を使ってステータスを示す。たとえば、緑はアクティブなプロセス、赤は非推奨のもの、黄色はレビューが必要なものを表す。
- レイヤリング:概要ビューと詳細ビューを分ける。メインの図にすべてのフィールドマッピングを詰め込まない。
- アクセス制御:図が必要な人にとってアクセス可能であることを確認する。セキュリティチームは機密情報を含むデータフローを確認する必要がある一方、開発者は技術的実装を把握する必要がある。
最終的な考慮事項 🔍
フローダイアグラムを用いたデータラインエージの追跡は、技術的な正確さと明確なコミュニケーションを融合する学問である。抽象的なデータの移動を具体的な視覚モデルに変換する。定められた基準に従い、厳格な更新サイクルを維持することで、組織は高いデータの透明性を達成できる。この透明性こそが現代のデータガバナンスの基盤である。
これらの図を構築・維持するために必要な努力は、リスクの低減と効率の向上という形で報われる。データ量が増加し、規制が厳しくなる中で、データの起源と移動経路を追跡できる能力は、さらに重要性を増すだろう。今日、明確で正確なフローダイアグラムに投資することは、組織が将来の課題に備えるための準備となる。目標は単にシステムを文書化することではなく、それを深く理解し、継続的に改善できるようにすることである。