











Al modelar sistemas complejos, la claridad es el objetivo principal. Los Diagramas de Flujo de Datos (DFD) sirven como una herramienta fundamental para visualizar cómo la información se mueve a través de un sistema. Dentro de este marco, dos símbolos dominan el panorama: el Proceso y el Almacén de datos. Aunque interactúan con frecuencia, representan conceptos fundamentalmente diferentes en cuanto a transformación y persistencia. Comprender esta distinción es crucial para un análisis y diseño de sistemas precisos.
Esta guía explora los roles funcionales, las representaciones visuales e implicaciones lógicas de estos elementos. Al distinguir entre acción y almacenamiento, los analistas pueden construir diagramas que comuniquen el comportamiento del sistema sin ambigüedades.
🔄 Definición del Proceso
Un proceso representa una unidad de trabajo o transformación. Es donde los datos cambian de forma, se calculan o se filtran. Piensa en un proceso como una caja negra. Sabes qué entra y qué sale, pero el mecanismo interno está definido por la lógica de transformación misma, no por el almacenamiento de esa información.
🔹 Características principales
- Transformación: La función principal es modificar los datos. Los datos de entrada entran, se aplican reglas o lógica, y los datos de salida salen.
- Naturaleza temporal: Los procesos están activos solo cuando se activan. No retienen datos entre ejecuciones.
- Direccionalidad: Los datos fluyen hacia dentro y hacia fuera de un proceso. Un proceso sin entrada o salida es lógicamente inválido en un contexto de DFD.
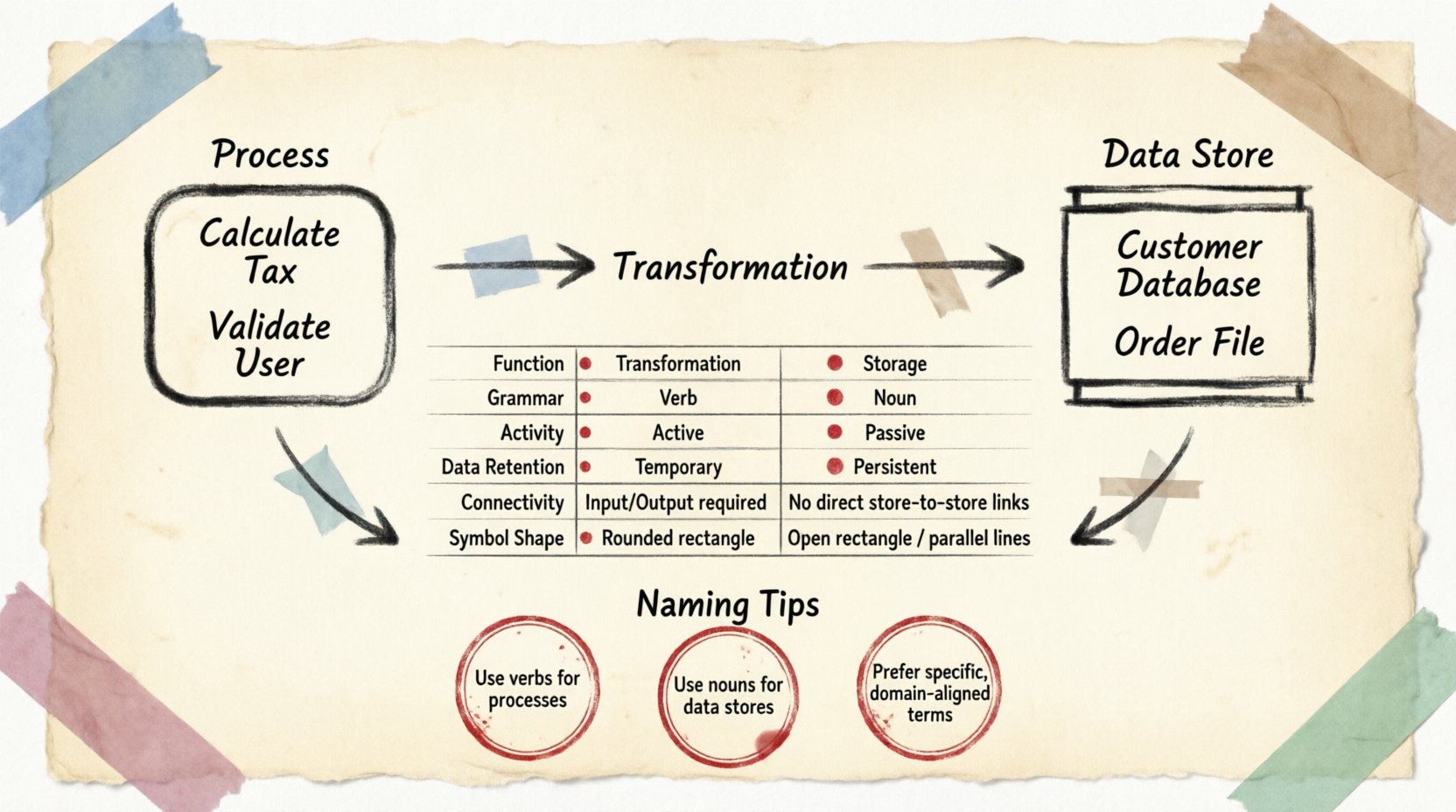
- Nombrado con verbos: Los procesos suelen etiquetarse con verbos o frases verbales (por ejemplo, Calcular impuestos, Validar usuario, Generar informe).
🔹 El concepto de caja negra
En el modelado de alto nivel, un proceso es una caja negra. La atención se centra en quéocurre con los datos, no en cómoocurre técnicamente. Por ejemplo, un proceso llamado «Procesar pedido» toma los detalles del pedido y crea un registro de transacción. No especifica si el cálculo ocurre en memoria, en disco o mediante una API remota. Esta abstracción permite a los interesados centrarse en la lógica empresarial en lugar de la implementación técnica.
Sin embargo, a medida que los diagramas se descomponen en niveles inferiores, la lógica interna se vuelve más detallada. Incluso así, el proceso sigue siendo un motor activo de transformación. Consume entrada, realiza trabajo y produce salida. No sirve como un depósito temporal para esa información.
🗄️ Definición del Almacén de datos
Una tienda de datos representa un repositorio donde descansa la información. A diferencia de un proceso, una tienda de datos no transforma datos. Espera. Mantiene los datos en un estado persistente hasta que un proceso los recupera o un proceso los coloca allí.
🔹 Características principales
- Persistencia: Los datos permanecen en una tienda incluso cuando no hay procesos activos. Esta es la diferencia clave con respecto a los búferes de memoria o las variables temporales.
- Naturaleza pasiva: Las tiendas de datos no inician acciones. Requieren un proceso para leerlos o escribir en ellos.
- Nombrado con sustantivos: Las tiendas suelen etiquetarse con sustantivos (por ejemplo, Base de datos de clientes, Archivo de pedidos, Registro de inventario).
- Abierto: Los flujos de datos pueden entrar y salir de una tienda. Sin embargo, una tienda no puede conectarse directamente con otra tienda. Los datos deben fluir a través de un proceso para moverse entre repositorios.
🔹 El concepto de repositorio
Imagina una biblioteca. Los libros son los datos. Las estanterías son las tiendas de datos. Un bibliotecario es el proceso. El bibliotecario no crea los libros; los organiza. Las estanterías no mueven los libros por sí mismas; los mantienen en su lugar. Cuando un lector solicita un libro, el bibliotecario lo recupera (operación de lectura). Cuando llega un libro nuevo, el bibliotecario lo coloca en la estantería (operación de escritura).
En la arquitectura de sistemas, una tienda de datos podría representar una tabla de base de datos, un archivo plano, una cola o un cubo en la nube. El símbolo de DFD abstrae la tecnología. Ya sea una tabla SQL o un archivo de texto simple, el papel lógico es idéntico: es un lugar donde se guarda la información.
⚡ Interacción y flujo de datos
La relación entre un proceso y una tienda de datos está regida por reglas estrictas de flujo de datos. Las flechas en un DFD representan el movimiento de datos. Estas flechas determinan la dirección de la transferencia de información.
🔹 El ciclo de lectura-escritura
Cuando un proceso necesita información, dibuja una flecha desde una tienda de datos hacia el proceso. Esto indica una operación de lectura. El proceso extrae los datos para usarlos en su lógica de transformación. Por el contrario, cuando un proceso genera nueva información, dibuja una flecha desde el proceso hacia una tienda de datos. Esto indica una operación de escritura. Ahora los datos se almacenan para su uso futuro.
Crucialmente, un flujo de datos no puede conectar dos tiendas de datos directamente. La información no puede migrar de un repositorio a otro sin ser procesada. Esta regla refuerza el principio de que el movimiento de datos siempre va acompañado de algún nivel de lógica o control, incluso si esa lógica es simplemente una operación de copia.
🔹 Entidades externas
Las entidades externas (fuentes o sumideros) interactúan con procesos, no directamente con tiendas de datos. Una entidad externa podría ser un usuario humano, una API de terceros o otro sistema. Envían datos a un proceso o reciben datos de un proceso. Luego, el proceso decide si almacenar esos datos en un repositorio o descartarlos.
📋 Tabla de comparación
Para resumir las diferencias estructurales, considere la siguiente descomposición de atributos.
| Atributo | Proceso | Tienda de datos |
|---|---|---|
| Función | Transformación / Acción | Almacenamiento / Memoria |
| Gramática | Verbo (por ejemplo, Actualizar) | Sustantivo (por ejemplo, Tabla de Usuarios) |
| Actividad | Activo (Se ejecuta cuando se activa) | Pasivo (Permanece hasta que se accede) |
| Retención de datos | Temporal (Durante la ejecución) | Persistente (a largo plazo) |
| Conectividad | Se conecta con Entidades, Almacenes y Otros Procesos | Se conecta únicamente con Procesos |
| Forma del símbolo | Rectángulo redondeado o círculo | Rectángulo abierto o líneas paralelas |
🧩 Convenciones de nomenclatura
La consistencia en la nomenclatura evita la confusión durante las fases de revisión e implementación. La ambigüedad surge con frecuencia cuando se utiliza el mismo término para almacenamiento y acción.
🔹 Nomenclatura de procesos
Los nombres deben describir la acción que se realiza sobre los datos. Evite nombres genéricos como «Hacerlo» o «Manejar». En su lugar, utilice descriptores específicos. Por ejemplo, «Validar credenciales de inicio de sesión» es superior a «Verificar inicio de sesión». Esta claridad ayuda a los desarrolladores a comprender de inmediato los requisitos esperados de entrada y salida.
🔹 Nomenclatura de almacenes de datos
Los nombres deben reflejar el contenido que se almacena. Utilice sustantivos en plural o identificadores claros. «Orders» implica una colección de registros de pedidos. «Order» podría implicar una instancia única de transacción. Aunque el contexto importa, los sustantivos en plural indican generalmente un repositorio que contiene múltiples registros.
Al nombrar almacenes de datos, considere el alcance. Un almacén denominado «Base de datos» es demasiado vago. «Base de datos de clientes» o «Registro de transacciones» proporcionan el contexto necesario. Esta granularidad ayuda a mapear el diagrama a estructuras de almacenamiento físicas más adelante.
🧪 Descomposición y niveles
Los DFDs son jerárquicos. Un diagrama de alto nivel (Diagrama de contexto) muestra el sistema como un único proceso. A medida que descomponga este diagrama en niveles inferiores, la distinción entre proceso y almacén se vuelve más crítica.
🔹 Nivel 0 frente al Nivel 1
En un Diagrama de contexto, todo el sistema es un único proceso. En el Nivel 0, este proceso se descompone en subprocesos principales. Aquí se introducen los almacenes de datos para mostrar dónde residen los componentes principales de datos. En el Nivel 1 y superiores, los procesos se refinan aún más.
Durante la descomposición, asegúrese de que los almacenes de datos no se dupliquen innecesariamente. Si un almacén existe en el Nivel 0, generalmente debe persistir hasta el Nivel 1, a menos que un subproceso específico requiera una caché temporal (que sería un almacén diferente). La consistencia entre niveles garantiza la trazabilidad.
🔹 Equilibrio
Una regla crítica en la descomposición es el «equilibrio». Las entradas y salidas de un proceso padre deben coincidir con las entradas y salidas de los procesos hijos en el diagrama de nivel inferior. Los almacenes de datos también deben alinearse. Si un almacén aparece en el diagrama padre, el diagrama hijo debe tener en cuenta correctamente ese flujo de datos. Si un proceso se divide, el flujo de datos hacia el almacén debe mantenerse a través de la división.
⚠️ Errores lógicos que se deben evitar
Algunos errores estructurales pueden invalidar un diagrama. Reconocer estos errores temprano ahorra tiempo durante la fase de desarrollo.
- Flujos de datos fantasma: Una flecha que sale de un proceso sin un flujo de datos entrante es imposible. Un proceso no puede generar salida de la nada. Cada salida debe derivarse de una entrada o de datos almacenados.
- Conexiones directas entre almacenes: Como se mencionó, un almacén no puede conectarse con otro almacén. Los datos deben pasar a través de un proceso. Esto garantiza que todo movimiento de datos sea intencional y procesado.
- Procesos no conectados: Un proceso que no tiene flujos de datos entrantes ni salientes está aislado. No interactúa con el sistema y no cumple ninguna función en el diagrama de flujo de datos.
- Confundir entidades y almacenes: Las entidades externas están fuera de los límites del sistema. Los almacenes de datos están dentro. No coloque un símbolo de entidad externa dentro de los límites del sistema como si fuera una base de datos.
🛠️ Implicaciones de implementación
La diferencia entre proceso y almacén influye en cómo se construye el sistema. Los procesos se corresponden con funciones, métodos o microservicios. Los almacenes de datos se corresponden con tablas, archivos o almacenamiento de objetos.
🔹 Diseño de bases de datos
Al diseñar una base de datos, los almacenes de datos en el DFD se convierten en el plano maestro del esquema. Los atributos dentro de las flechas de flujo de datos definen las columnas. Las relaciones entre almacenes (mediadas por procesos) definen claves foráneas o enlaces transaccionales.
🔹 Automatización de flujos de trabajo
Para motores de flujos de trabajo, los procesos representan los pasos en una canalización. Los almacenes de datos representan el estado del flujo de trabajo. Un proceso podría actualizar el estado en el almacén para marcar una tarea como completada. Comprender la naturaleza pasiva del almacén garantiza que el motor de flujos de trabajo espere el estado correcto antes de continuar.
🔍 Normas de representación visual
Diferentes metodologías utilizan símbolos ligeramente diferentes, pero la lógica permanece consistente.
- DeMarco y Yourdon: Utiliza rectángulos redondeados para procesos y rectángulos abiertos para almacenes de datos.
- Gane y Sarson: Utiliza rectángulos redondeados para procesos y líneas paralelas para almacenes de datos.
Independientemente de la notación elegida, el significado semántico es idéntico. Un proceso actúa; un almacén almacena. La consistencia dentro de la documentación del proyecto es más importante que adherirse a una norma específica, siempre que el equipo entienda la convención elegida.
🎯 Resumen de roles
Construir un modelo de sistema robusto requiere disciplina al asignar roles. El proceso es el actor. Realiza el trabajo. El almacén de datos es el escenario. Almacena los elementos escénicos. Sin el actor, el escenario está vacío. Sin el escenario, el actor no tiene dónde colocar sus hallazgos.
Manteniendo una separación clara entre transformación y almacenamiento, los analistas crean diagramas que no solo son visualmente atractivos, sino también lógicamente sólidos. Estos diagramas sirven como un contrato entre los interesados del negocio y los equipos técnicos. Definen los límites de responsabilidad y el flujo de valor.
Al revisar un DFD, haz dos preguntas para cada símbolo: «¿Está realizando trabajo?» (Proceso) o «¿Está almacenando información?» (Almacén). Si la respuesta no es clara, refine la etiqueta o la conexión. La claridad es el objetivo final de la modelización de sistemas.
Adherirse a estos principios garantiza que la arquitectura resultante sea mantenible, escalable y comprensible. La diferencia es simple, pero su impacto en la integridad del sistema es profundo.