











Das Verständnis dafür, wie Informationen durch ein System fließen, ist grundlegend für die Entwicklung zuverlässiger Softwarearchitekturen. Wenn wir ein System mithilfe eines Datenflussdiagramms (DFD) darstellen, zeichnen wir nicht einfach nur Kästchen und Linien; wir kartieren den Lebenszyklus der Daten selbst. Die Analyse von Datenbewegungspfaden erfordert eine gründliche Untersuchung der Herkunft der Daten, ihrer Transformation, ihres Aufenthaltsorts und ihres Austritts aus der Umgebung. Dieser Prozess gewährleistet Integrität, Leistungsfähigkeit und Sicherheit über die gesamte Architektur hinweg.
Ohne eine klare Karte können Daten verloren gehen, vervielfacht werden oder unbefugtem Zugriff ausgesetzt sein. Eine gründliche Analyse offenbart Engpässe, versteckte Abhängigkeiten und potenzielle Ausfallpunkte, bevor sie die Produktion beeinträchtigen. Dieser Leitfaden untersucht die Methodik zur präzisen und klaren Aufschlüsselung dieser Pfade.
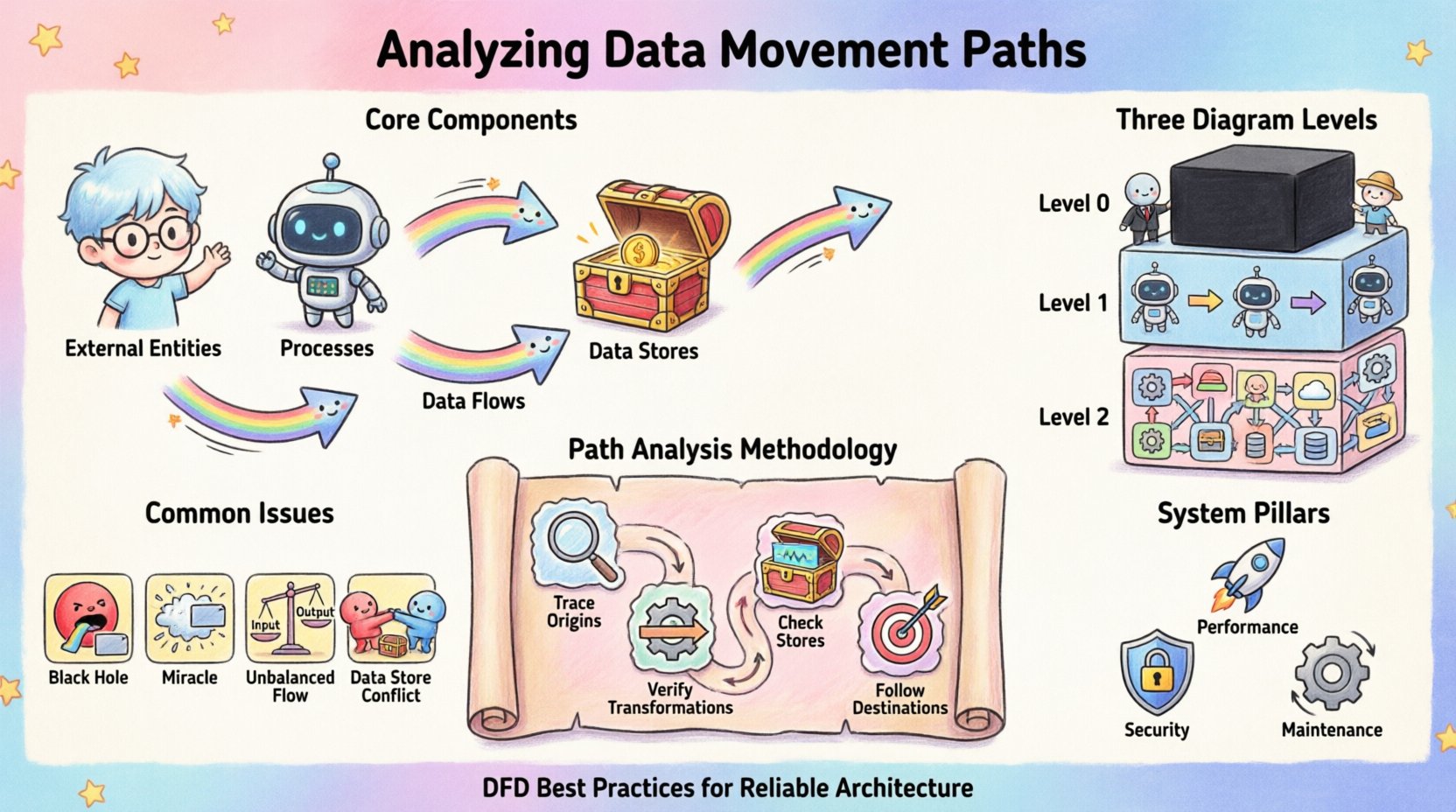
Wesentliche Komponenten der Datenbewegung 🧩
Um die Bewegung effektiv analysieren zu können, muss man zunächst die unterschiedlichen Elemente erkennen, die sie ermöglichen. Jedes DFD beruht auf einer konsistenten Fachsprache zur Beschreibung des Flusses. Die Vernachlässigung dieser Definitionen führt zu Unklarheiten im Modell.
- Externe Entitäten: Diese stellen Quellen oder Ziele außerhalb der Systemgrenzen dar. Sie initiieren Datenanfragen oder empfangen verarbeitete Ausgaben. Beispiele sind menschliche Benutzer, andere Systeme oder Drittdienste.
- Prozesse: Diese sind die Transformationen. Ein Prozess nimmt Eingabedaten entgegen, wendet Logik oder Regeln an und erzeugt Ausgabedaten. Er ist die Triebkraft der Veränderung innerhalb des Systems.
- Datenbanken: Diese sind Speicherorte, an denen Informationen für spätere Abrufe gespeichert werden. Sie gewährleisten Persistenz und ermöglichen es Daten, über die unmittelbare Ausführung eines Prozesses hinaus zu bestehen.
- Datenflüsse: Diese sind die Pfeile, die die Komponenten verbinden. Sie repräsentieren die tatsächliche Bewegung von Datensätzen oder Datensätzen zwischen Entitäten, Prozessen und Speichern.
Jeder Pfeil muss eine beschreibende Beschriftung haben, die genau angibt, welche Information reist. Vage Beschriftungen wie „Info“ oder „Daten“ verschleiern die spezifische Natur des Übertrags und erschweren die Analyse.
Ebenen der Detailgenauigkeit bei der Diagrammierung 📊
Die Datenbewegung ist selten statisch; sie existiert auf verschiedenen Abstraktionsstufen. Ein einzelnes Diagramm kann nicht jedes Byte an Information erfassen. Stattdessen verwenden wir einen hierarchischen Ansatz, um das System zu zerlegen.
1. Kontextdiagramm (Ebene 0)
Die höchste Abstraktionsebene betrachtet das gesamte System als ein einzelnes schwarzes Kästchen. Es zeigt die Interaktion des Systems mit externen Entitäten. Dies ist entscheidend für das Verständnis der Grenzen. Es beantwortet die Frage: Was tauscht das System mit der Außenwelt aus?
2. Ebene-1-Diagramm
Hier wird das schwarze Kästchen in Hauptprozesse zerlegt. Diese Ebene offenbart die primären Untereinheiten und wie hochwertige Daten zwischen ihnen fließen. Sie bietet einen Überblick über die interne Architektur, ohne in feinmechanische Logik verstrickt zu werden.
3. Ebene-2-Diagramme und darunter
Weitere Zerlegung erfolgt bei komplexen Prozessen. Diese detaillierten Ansichten zeigen spezifische Transformationen und den feinkörnigen Datenfluss. Diese Ebene ist entscheidend, um spezifische Validierungsstufen und Fehlerbehandlungsmechanismen zu identifizieren.
Bei der Analyse von Pfaden ist Konsistenz zwischen den Ebenen von größter Bedeutung. Daten, die in einen Prozess der Ebene 1 eintreten, müssen mit den Daten übereinstimmen, die ihn verlassen. Abweichungen zwischen den Ebenen deuten auf Lücken im Design hin.
Methodik zur Pfadanalyse 🔍
Die Verfolgung eines Datenpfads ist eine systematische Aufgabe. Sie beinhaltet das Verfolgen des Weges von der Quelle bis zum Ziel. Dieser Prozess hilft, logische Fehler und fehlende Verbindungen zu identifizieren.
Schritt 1: Ursprünge der Eingaben verfolgen
Beginnen Sie bei einer externen Entität. Folgen Sie dem Pfeil in das System. Fragen Sie, wohin diese Daten als Nächstes gehen. Gehen sie zu einem Prozess oder zu einem Speicher? Wenn sie zu einem Prozess gehen, verfügt dieser über ausreichend Informationen, um zu funktionieren? Jeder Prozess muss mindestens eine Eingabe und eine Ausgabe haben.
Schritt 2: Transformationen überprüfen
Sobald Daten in einen Prozess eintreten, analysieren Sie die Veränderung. Ist die Ausgabe logisch aus der Eingabe abgeleitet? Manchmal erscheint Daten in der Ausgabe eines Prozesses, die in der Eingabe nicht vorhanden waren. Dies wird als „Wunder“ bezeichnet und deutet auf einen fehlenden Eingang oder einen fest codierten Wert hin, der dokumentiert werden sollte.
Schritt 3: Datenbanken überprüfen
Identifizieren Sie jede Lese- und Schreiboperation. Eine Datenbank sollte kein Sackgasse sein. Wenn Daten in eine Datenbank fließen, muss zu einem späteren Zeitpunkt ein entsprechender Fluss aus ihr heraus erfolgen, es sei denn, die Daten werden dauerhaft archiviert. Stellen Sie sicher, dass das Schema, das aus dem Diagramm hervorgeht, mit den physischen Speicheranforderungen übereinstimmt.
Schritt 4: Ausgabestellen verfolgen
Wohin geht die verarbeitete Daten? Keht sie zurück zum Benutzer? Triggert sie einen anderen Prozess? Verlässt sie die Systemgrenze? Stellen Sie sicher, dass jeder Ausgangspfad berücksichtigt wird. Verwaiste Prozesse, die Daten ohne Ziel produzieren, sind ein Zeichen für eine unvollständige Gestaltung.
Häufige strukturelle Probleme ⚠️
Während der Analyse ergeben sich bestimmte Muster, die auf Gestaltungsfehler hinweisen. Die frühzeitige Erkennung dieser Muster verhindert kostspielige Umgestaltungen später.
| Problem | Beschreibung | Auswirkung |
|---|---|---|
| Schwarzes Loch | Ein Prozess hat Eingaben, aber keine Ausgaben. | Daten werden verbraucht und verschwinden. Die Logik ist unvollständig. |
| Wunder | Ein Prozess hat Ausgaben, aber keine Eingaben. | Daten erscheinen aus dem Nichts. Die Logik ist undefiniert. |
| Ungleichgewichtiger Fluss | Eingabe- und Ausgabedaten stimmen auf verschiedenen Ebenen nicht überein. | Verlust der Datenintegrität während der Zerlegung. |
| Konflikt im Datenspeicher | Mehrere Prozesse schreiben ohne Sperre in denselben Speicher. | Konkurrenzprobleme und Datenkorruption. |
Sicherheits- und Compliance-Überlegungen 🔒
Sicherheit ist kein Zusatz; sie ist eine Eigenschaft der Datenbewegung selbst. Die Analyse von Pfaden ermöglicht es uns, zu identifizieren, wo vertrauliche Informationen gespeichert und übertragen werden.
Identifizierung sensibler Daten
Verfolgen Sie personenbezogene Informationen (PII) oder Finanzdaten. Wenn sensible Daten zwischen Prozessen bewegt werden, ist dann eine Verschlüsselung erforderlich? Wenn sie in einem Speicher verbleiben, ist der Zugriff kontrolliert? Das Diagramm sollte diese sensiblen Flüsse hervorheben, beispielsweise durch unterschiedliche Linienstile oder Beschriftungen.
Zugriffssteuerungspunkte
Jeder Prozess fungiert als potenzieller Wächter. Analysieren Sie die Authentifizierungsanforderungen für jeden Prozess. Impliziert das Datenflussdiagramm, dass jeder Prozess auf jeden Speicher zugreifen kann? Dies deutet oft auf die Notwendigkeit strenger rollenbasierter Zugriffssteuerungen hin.
Regulatorische Compliance
Vorschriften legen oft fest, wo Daten gespeichert werden dürfen. Beispielsweise erfordern einige Rechtsgebiete, dass Daten innerhalb bestimmter geografischer Grenzen verbleiben. Ein Datenbewegungspfad, der diese Grenzen überschreitet, muss zur rechtlichen Prüfung markiert werden. Das Diagramm dient als Beweis für die Compliance-Architektur.
Leistung und Optimierung 🚀
Datenbewegung ist nicht kostenlos. Sie verbraucht Bandbreite, Rechenleistung und Zeit. Die Analyse der Pfade hilft dabei, diese Ressourcen zu optimieren.
Identifizierung von Engpässen
Suchen Sie nach Prozessen mit mehreren hochvolumigen Eingaben und Ausgaben. Diese sind wahrscheinlich zu Leistungsengpässen werden. Wenn ein einzelner Prozess Daten von fünf verschiedenen Quellen aggregiert, bevor er sie weiterleitet, könnte er unter Last Probleme haben. Überlegen Sie, ihn in parallele Prozesse aufzuteilen.
Latenzanalyse
Zählen Sie die Anzahl der Sprünge, die Daten zurücklegen müssen, um ihr Ziel zu erreichen. Jeder Sprung führt zu Latenz. Wenn eine Benutzeranfrage zehn Prozesse durchlaufen muss, bevor eine Antwort zurückgegeben wird, wirkt das System langsam. Die Reduzierung der Anzahl der Transformationen kann die Reaktionsfähigkeit verbessern.
Redundanzreduzierung
Überprüfen Sie auf doppelte Datenströme. Wenn die gleichen Informationen an drei verschiedene Prozesse gesendet werden, überlegen Sie, ob sie einen gemeinsamen Datenspeicher nutzen können. Dadurch verringert sich der Netzwerkverkehr und die Konsistenz wird gewährleistet.
Aufrechterhaltung der Diagrammgenauigkeit 🔄
Ein Diagramm ist ein lebendiges Dokument. Während sich das System weiterentwickelt, ändern sich die Pfade. Die Aufrechterhaltung der Genauigkeit erfordert einen disziplinierten Ansatz.
Versionskontrolle
Jede Änderung an der Datenflussstruktur sollte versioniert werden. Dadurch können Teams nachvollziehen, wann ein bestimmter Pfad verändert wurde. Dies ist für die Fehlerbehebung und die Auswirkungsanalyse unerlässlich.
Auswirkungsanalyse
Bevor ein Prozess geändert wird, verfolgen Sie alle verbundenen Ströme. Die Änderung eines Prozesses könnte einen nachgelagerten Verbraucher stören. Das Diagramm hilft, diese Abhängigkeiten zu visualisieren. Wenn sich das Datenformat in einem Speicher ändert, müssen alle Prozesse, die daraus lesen, aktualisiert werden.
Dokumentationsstandards
Legen Sie Regeln für Benennung und Beschriftung fest. Konsistente Namenskonventionen machen das Diagramm für neue Teammitglieder verständlich. Eine klare Legende sollte alle speziellen Symbole oder Linientypen erklären, die für Sicherheits- oder Leistungsmerkmale verwendet werden.
Integration mit anderen Modellen 🤝
Datenflussdiagramme existieren nicht isoliert. Sie ergänzen andere Modellierungstechniken.
Entitäts-Beziehungs-Diagramme (ERD)
Während DFDs auf Bewegung fokussieren, konzentrieren sich ERDs auf die Struktur. Die gegenseitige Abstimmung stellt sicher, dass die durch Prozesse fließenden Daten mit dem in der Datenbank definierten Schema übereinstimmen. Wenn ein Prozess eine „CustomerID“ erwartet, das ERD aber „ClientNum“ definiert, besteht ein Missverhältnis.
Zustandsübergangsdiagramme
DFDs zeigen, was sich bewegt, aber Zustandsdiagramme zeigen, wann. Die Kombination dieser beiden hilft zu verstehen, wie Datenbewegung Zustandsänderungen auslöst. Zum Beispiel könnte ein „PaymentReceived“-Fluss eine Zustandsänderung von „Pending“ zu „Shipped“ auslösen.
Schlussfolgerung zu Analysepraktiken ✅
Die Disziplin der Analyse von Datenbewegungspfaden dreht sich um Klarheit und Kontrolle. Sie wandelt abstrakte Anforderungen in konkrete architektonische Entscheidungen um. Indem Architekten jeden Pfeil sorgfältig verfolgen und jede Transformation überprüfen, bauen sie Systeme, die widerstandsfähig und verständlich sind.
Diese Praxis erfordert Aufmerksamkeit für Details. Sie verlangt, jede Annahme darüber zu hinterfragen, woher die Daten kommen und wohin sie gehen. Wenn sie korrekt durchgeführt wird, dient das resultierende Diagramm als Bauplan für Entwicklung, Test und Wartung. Es wird zu einer gemeinsamen Sprache zwischen Geschäftssachverständigen und technischen Teams, wodurch sichergestellt wird, dass alle den Weg der Daten verstehen.
Je komplexer die Systeme werden, desto größer wird die Notwendigkeit klarer Abbildungen. Ein gut analysiertes Datenflussdiagramm ist eine Investition in die langfristige Stabilität der Software. Es verringert das Risiko von Datenverlust, Sicherheitsverletzungen und Leistungsabfall. Durch Einhaltung dieser analytischen Standards stellen Teams sicher, dass ihre Systeme auch bei Skalierung robust bleiben.