











Die Datenintegrität beruht auf Sichtbarkeit. Ohne eine klare Karte, wie Informationen durch ein System fließen, operieren Organisationen blind. Die Verfolgung der Datenherkunft liefert genau diese Karte und dokumentiert die Reise von der Quelle bis zur Nutzung. Datenflussdiagramme dienen als grundlegende visuelle Sprache für diese Aufgabe. Sie übersetzen komplexe technische Prozesse in verständliche Strukturen, sodass Teams Transformationen und Abhängigkeiten präzise verfolgen können. Dieser Ansatz stellt sicher, dass jedes Datenstück nachvollzogen werden kann und unterstützt Compliance, Debugging und strategische Entscheidungsfindung.
Der Prozess erfordert mehr als nur Linien zwischen Kästchen zu zeichnen. Er setzt ein tiefes Verständnis der zugrundeliegenden Architektur, der Logik hinter den Transformationen und der beteiligten Speichermechanismen voraus. Durch die Nutzung standardisierter Diagrammtechniken können technische Teams eine lebendige Dokumentation erstellen, die sich gemeinsam mit der Infrastruktur entwickelt. Dieses Dokument legt die Methodik zur Implementierung der Herkunftstrace durch Flussdiagramme dar, wobei Schwerpunkte auf Klarheit, Genauigkeit und langfristiger Wartbarkeit liegen.
Verständnis der Datenherkunft 🧬
Datenherkunft bezieht sich auf die Geschichte der Daten. Sie erfasst Herkunft, Bewegungen und Transformationen, die Daten während ihres Lebenszyklus durchlaufen. Stellen Sie sich eine Wassertröpfchen vor, das in ein Flusssystem eintritt; die Herkunft verfolgt, wo es herkommt, welche Nebenflüsse es passiert und wo es letztendlich ausfließt. Im digitalen Kontext bedeutet dies zu wissen, welche Datenbanktabelle einen Datensatz erzeugt hat, welcher Skript ihn verarbeitet hat und welches Dashboard das endgültige KPI anzeigt.
Die Etablierung der Herkunft ist aus mehreren Gründen entscheidend. Erstens unterstützt sie die Fehlerbehebung. Wenn eine Zahl in einem Bericht falsch erscheint, ermöglicht die Herkunft, den Wert rückwärts zu verfolgen, um den Ort des Abweichungspunkts zu identifizieren. Zweitens unterstützt sie die Einhaltung von Vorschriften. Gesetze zum Datenschutz verlangen oft, dass Organisationen genau wissen, wo personenbezogene Daten gespeichert sind und wie sie verwendet werden. Schließlich schafft sie Vertrauen. Stakeholder sind eher bereit, auf Analysen zu vertrauen, wenn sie die Quelle und die Verarbeitungslogik hinter den Zahlen verstehen.
Die Herkunft kann in zwei Haupttypen eingeteilt werden: logisch und physisch. Die logische Herkunft beschreibt die konzeptionelle Bewegung der Daten, beispielsweise „Kunden-ID wird von Verkauf in Rechnungsstellung übertragen“. Die physische Herkunft beschreibt die spezifischen technischen Schritte, wie beispielsweise „Spalte 5 aus Tabelle A wird über SQL-Abfrage B in Spalte 3 von Tabelle C extrahiert“. Flussdiagramme verbinden diese beiden effektiv und liefern eine visuelle Darstellung, die sowohl Geschäftsinteressenten als auch technische Ingenieure zufriedenstellt.
Die Rolle von Datenflussdiagrammen 📊
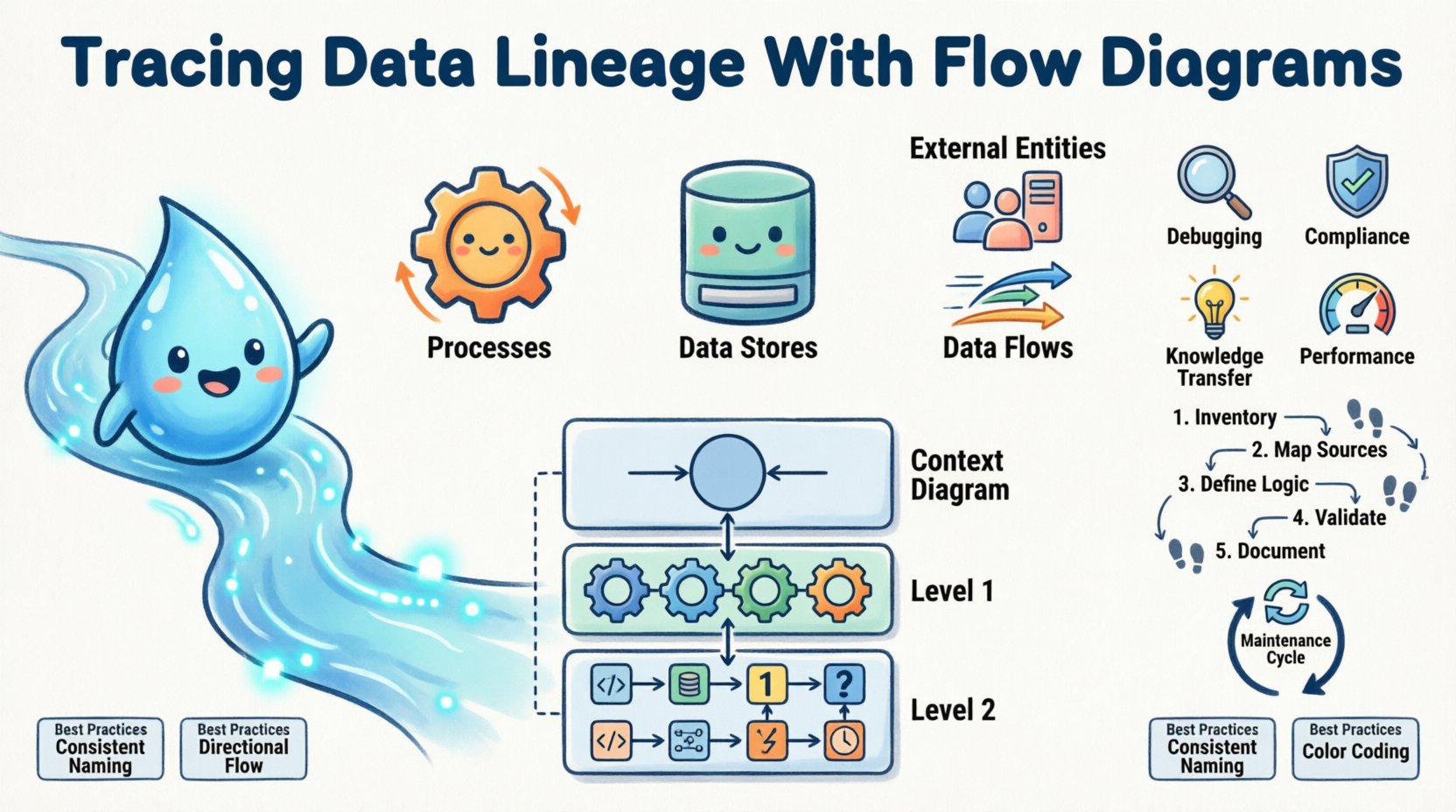
Datenflussdiagramme (DFDs) sind grafische Darstellungen, wie Daten durch ein System fließen. Im Gegensatz zu Entitäts-Beziehungs-Diagrammen, die sich auf statische Beziehungen zwischen Datenobjekten konzentrieren, legen DFDs den Fokus auf den dynamischen Fluss und die Verarbeitung von Informationen. Sie zerlegen komplexe Systeme in handhabbare Komponenten und machen sie ideal für die Abbildung der Datenherkunft.
Ein Standard-DFD besteht aus vier zentralen Elementen:
- Prozesse:Aktionen, die Daten transformieren. Sie werden meist als Kreise oder abgerundete Rechtecke dargestellt. Beispiele sind „Steuer berechnen“ oder „Verkaufsdaten aggregieren“.
- Datenbanken:Orte, an denen Daten gespeichert werden. Sie werden als offene Rechtecke dargestellt, die Datenbanken, Dateien oder Warteschlangen darstellen.
- Externe Entitäten:Quellen oder Ziele außerhalb der Systemgrenzen. Benutzer, andere Systeme oder Aufsichtsbehörden fallen oft in diese Kategorie.
- Datenflüsse:Die Pfeile, die die Elemente verbinden und die Richtung sowie den Inhalt der Datenbewegung anzeigen.
Bei der Verfolgung der Datenherkunft werden diese Elemente zu Knoten in einem größeren Graphen. Die Verbindungen zeigen den Pfad auf. Durch Einhaltung der DFD-Standards stellen Teams eine Konsistenz sicher. Ein Prozess in einem Diagramm folgt denselben visuellen Regeln wie ein Prozess in einem anderen, wodurch die kognitive Belastung für alle, die die Dokumentation prüfen, reduziert wird.
Ebenen der Diagrammdetails 🛠️
Um die Komplexität zu managen, werden DFDs oft auf verschiedenen Abstraktionsstufen erstellt. Diese Hierarchie ermöglicht es Stakeholdern, sich auf bestimmte Bereiche zu konzentrieren, ohne von der gesamten Systemarchitektur überwältigt zu werden. Der Standardansatz umfasst drei Ebenen der Tiefe.
| Ebene | Beschreibung | Anwendungsfall |
|---|---|---|
| Kontextdiagramm (Ebene 0) | Übersicht auf hoher Ebene, die das System als einen einzigen Prozess und seine Interaktion mit externen Entitäten zeigt. | Exekutivzusammenfassungen und Planung der Architektur auf hoher Ebene. |
| Ebene-1-Diagramm | Teilt den Hauptprozess in wesentliche Unterverarbeitungen und Datenbanken auf. | Systemdesign und Identifizierung der wichtigsten Datenberührungspunkte. |
| Ebene-2-Diagramm | Zerlegt spezifische Prozesse aus Ebene 1 weiter in detaillierte Schritte. | Technische Implementierung, Code-Reviews und detaillierte Audits. |
Dieser mehrstufige Ansatz verhindert, dass das Diagramm unlesbar wird. Eine einzige Seite, die jede einzelne SQL-Join-Operation und jeden API-Aufruf zeigt, wäre chaotisch. Stattdessen bietet das Kontextdiagramm das Gesamtbild, während die Diagramme der Ebene 2 die notwendige Feinheit für ingenieurtechnische Aufgaben liefern. Bei der Verfolgung der Datenherkunft ist es oft notwendig, zwischen diesen Ebenen zu wechseln. Eine Abfrage in einem Diagramm der Ebene 2 könnte in einem Diagramm der Ebene 1 als ein einziger Prozess zusammengefasst sein.
Schritte zur Implementierung der Stammbaumverfolgung 📝
Die Erstellung einer genauen Stammbaumkarte erfordert einen systematischen Ansatz. Willkürliche Zeichnungen führen zu Inkonsistenzen und fehlenden Verbindungen. Die folgenden Schritte beschreiben einen robusten Arbeitsablauf zum Aufbau und zur Pflege von Flussdiagrammen für die Datenstammbaumverfolgung.
1. Bestand an bestehenden Assets erfassen
Bevor Sie zeichnen, müssen Sie wissen, was vorhanden ist. Erstellen Sie eine Liste aller beteiligten Datenbanken, Data-Warehouses, Anwendungsserver und Berichtstools. Identifizieren Sie die primären Datenquellen, wie transaktionale Systeme oder externe APIs. Diese Inventarliste bildet die Grenze Ihres Diagramms. Ohne eine vollständige Liste entstehen Lücken im Stammbaum, was zu Blindstellen in der Governance führt.
2. Datenquellen zu Zielen abbilden
Beginnen Sie bei der Quelle. Identifizieren Sie den ersten Einstiegspunkt der Daten. Verfolgen Sie ihn bis zum ersten Verarbeitungsschritt. Dokumentieren Sie die Transformationslogik. Bereinigt ein Skript die Daten? Filtert eine Ansicht bestimmte Zeilen? Dokumentieren Sie dies auf Prozessebene. Fahren Sie fort, bis Sie das Endziel erreichen, beispielsweise ein Business-Intelligence-Dashboard oder ein Archivspeichersystem.
3. Transformationslogik definieren
Daten bleiben selten statisch. Sie werden aggregiert, zusammengeführt oder berechnet. Diese Transformationen sind die entscheidenden Punkte im Stammbaum. Dokumentieren Sie die spezifischen Regeln, die angewendet werden. Zum Beispiel: „Nullwerte in Spalte X werden durch 0 ersetzt“ oder „Zeitstempel werden von UTC in Ortszeit umgewandelt“. Diese Detailgenauigkeit ist für das Debugging unerlässlich. Wenn ein nachgelagerter Bericht unerwartete Werte zeigt, ermöglicht die Kenntnis der Transformationsregel die Reproduktion des Fehlers in einer Testumgebung.
4. Mit technischen Teams validieren
Ein Diagramm, das isoliert gezeichnet wird, ist anfällig für Fehler. Überprüfen Sie den Entwurf gemeinsam mit den Ingenieuren, die die Pipelines gebaut haben, und den Analysten, die die Daten nutzen. Sie können fehlende Schritte oder falsche Annahmen erkennen. Diese Zusammenarbeit stellt sicher, dass das Diagramm die Realität widerspiegelt, nicht nur das theoretische Design. Die Validierung ist ein entscheidender Schritt, um die Integrität der Stammbaum-Dokumentation zu gewährleisten.
5. Metadaten dokumentieren
Hängen Sie Metadaten an die Diagrammelemente an. Dazu gehören Versionsnummern, Namen der Verantwortlichen und Erstellungsdaten. Datenflüsse ändern sich im Laufe der Zeit. Ein Prozess könnte im nächsten Quartal neu strukturiert werden. Metadaten ermöglichen es Ihnen, die Geschichte des Diagramms selbst zu verfolgen und sicherzustellen, dass Sie wissen, welche Version der Stammbaumkarte während eines bestimmten Prüfzeitraums aktiv war.
Vorteile einer strukturierten Stammbaumverfolgung 🏗️
Die Investition von Zeit in detaillierte Flussdiagramme bringt messbare Vorteile für die gesamte Organisation. Die Vorteile reichen über einfache Dokumentation hinaus.
- Verringerte Debugging-Zeit: Wenn Fehler auftreten, verbringen Ingenieure weniger Zeit damit, die Ursache zu suchen. Das Diagramm wirkt als Leitfaden und zeigt direkt auf den wahrscheinlichen Fehlerbereich.
- Verbesserte Auswirkungsanalyse: Wenn ein Änderungsantrag vorliegt, beispielsweise die Änderung eines Spaltennamens, zeigt die Stammbaumkarte genau, welche Berichte und nachgelagerten Prozesse betroffen sind. Dies verhindert versehentliche Ausfälle.
- Regulatorische Compliance: Prüfer verlangen Beweise für die Datenverarbeitung. Flussdiagramme bieten eine klare, visuelle Prüfungsroute, die die Anforderungen an Datenschutz und Sicherheit erfüllt.
- Wissensweitergabe: Neue Teammitglieder können die Systemarchitektur schnell verstehen. Anstatt sich auf traditionelles Wissen zu verlassen, können sie die Diagramme studieren, um zu verstehen, wie Daten durch die Organisation fließen.
- Optimierte Leistung: Die Analyse des Flusses offenbart oft Engpässe. Wenn Daten zu lange an einem bestimmten Speicher oder Prozess warten, zeigt das Diagramm, wo Optimierungsmaßnahmen fokussiert werden sollten.
Pflege der Diagramme 🔄
Eine Stammbaumkarte ist keine einmalige Aufgabe. Systeme entwickeln sich weiter. Neue Datenquellen werden hinzugefügt, und alte Prozesse werden abgeschaltet. Wenn die Diagramme nicht aktualisiert werden, werden sie irreführend. Die Aufrechterhaltung der Genauigkeit erfordert einen disziplinierten Ansatz zur Änderungssteuerung.
Jedes Mal, wenn eine Datenpipeline geändert wird, sollte das Diagramm überprüft werden. Dies sollte Teil der Bereitstellungskontrollliste sein. Wenn eine neue API integriert wird, müssen die externe Entität und der Datenfluss hinzugefügt werden. Wenn sich die Transformationslogik ändert, muss die Beschreibung der Prozessbox aktualisiert werden. Die Behandlung des Diagramms als Code stellt sicher, dass es weiterhin eine zuverlässige Ressource bleibt.
Automatisierung kann bei der Pflege helfen. Einige Plattformen ermöglichen die Erzeugung von Diagrammen auf Basis von Metadaten-Repositories. Obwohl manuelle Überprüfungen weiterhin erforderlich sind, verringert die Automatisierung die Belastung, die visuelle Darstellung mit der technischen Realität synchron zu halten. Allerdings kann die reine Abhängigkeit von Automatisierung den geschäftlichen Kontext übersehen, weshalb menschliche Überwachung unverzichtbar bleibt.
Umgang mit Komplexität ⚖️
Große Unternehmen haben oft mit komplexen Datenökosystemen zu tun. Tausende Tabellen und Hunderte Prozesse können ein einzelnes Diagramm überwältigend machen. In solchen Fällen ist Modularität entscheidend. Teilen Sie den Stammbaum in logische Bereiche auf. Erstellen Sie separate Diagramme für Verkaufsdaten, Kundendaten und Finanzdaten. Verbinden Sie sie an den Schnittpunkten, halten Sie aber die Hauptansichten fokussiert.
Eine weitere Herausforderung ist die Behandlung veralteter Systeme. Ältere Systeme könnten die Metadaten fehlen, die für die automatische Verfolgung erforderlich sind. In solchen Fällen ist eine manuelle Rekonstruktion notwendig. Befragen Sie die ursprünglichen Entwickler oder überprüfen Sie alte Dokumentationen, um den Datenfluss abzuleiten. Seien Sie transparent über diese Lücken. Markieren Sie unsichere Bereiche im Diagramm, um anzuzeigen, wo weitere Untersuchungen erforderlich sind.
Best Practices für Klarheit 🚀
Um sicherzustellen, dass die Diagramme ihre Aufgabe erfüllen, beachten Sie diese Richtlinien für Gestaltung und Präsentation.
- Konsistente Benennung:Verwenden Sie standardisierte Namen für Prozesse und Datenspeicher in allen Diagrammen. Vermeiden Sie Abkürzungen, die Leser verwirren könnten.
- Richtungsfluss:Richten Sie Diagramme so aus, dass sie logisch von links nach rechts oder von oben nach unten fließen. Dies entspricht natürlichen Lesemustern.
- Farbcodierung:Verwenden Sie Farben, um den Status anzugeben. Zum Beispiel grün für aktive Prozesse, rot für veraltete und gelb für solche, die einer Überprüfung bedürfen.
- Schichtung:Halten Sie die Übersichtsansicht von der detaillierten Ansicht getrennt. Verunreinigen Sie das Hauptdiagramm nicht mit jeder einzelnen Feldzuordnung.
- Zugriffssteuerung:Stellen Sie sicher, dass Diagramme für diejenigen zugänglich sind, die sie benötigen. Sicherheitsteams müssen Datenflüsse mit sensiblen Informationen sehen können, während Entwickler die technische Implementierung einsehen müssen.
Abschließende Überlegungen 🔍
Die Verfolgung der Datenherkunft mit Flussdiagrammen ist eine Disziplin, die technische Präzision mit klarer Kommunikation verbindet. Sie wandelt abstrakte Datenbewegungen in konkrete visuelle Modelle um. Durch die Einhaltung etablierter Standards und die Aufrechterhaltung eines strengen Aktualisierungszyklus können Organisationen ein hohes Maß an Datentransparenz erreichen. Diese Transparenz ist die Grundlage der modernen Datenverwaltung.
Der Aufwand, um diese Diagramme zu erstellen und zu pflegen, zahlt sich in Form reduzierter Risiken und erhöhter Effizienz aus. Mit wachsenden Datenmengen und verschärften Vorschriften wird die Fähigkeit, Herkunft und Weg von Daten nachzuverfolgen, noch wichtiger. Die Investition in klare, genaue Flussdiagramme heute bereitet die Organisation auf die Herausforderungen von morgen vor. Das Ziel ist nicht nur, das System zu dokumentieren, sondern es tief genug zu verstehen, um es kontinuierlich zu verbessern.