











设计一个健壮的系统不仅需要视觉上连接组件,更需要严格的逻辑验证。在构建数据流图时,信息流动的视觉表现仅取决于其背后的逻辑。此设计阶段的错误可能会导致后续出现严重的运行故障。本指南深入探讨如何识别和纠正流程设计中的逻辑错误,以确保数据完整性和流程可靠性。 🧠
理解流程设计的基础 🏗️
在识别错误之前,必须理解标准数据流图的架构。这些图表描绘了数据在系统中的流动,突出显示外部实体、处理过程、数据存储以及连接它们的流。其主要目的是可视化信息如何进入、转换并离开系统。当控制这些流动的逻辑存在缺陷时,系统架构就会变得不稳定。
逻辑错误与语法错误不同。语法错误会阻止图表被绘制或技术性验证。逻辑错误则意味着图表绘制正确,但反映的是一种不可能或低效的现实。例如,一个过程可能被描绘为接收输入但没有定义输出,或者数据凭空出现。这些异常会破坏信息的逻辑流动。 ⚙️
确保图表准确反映业务规则和数据守恒定律至关重要。进入处理过程的每一条数据必须被转换、存储或传递出去。任何数据都不应被无故创建或销毁,必须有明确的机制。这一原则是流程设计中逻辑一致性的核心。
需要检测的逻辑错误类别 🔍
逻辑错误在流程设计中以各种形式表现出来。识别这些类别有助于系统性审查。以下是设计阶段经常出现的主要逻辑不一致类型。
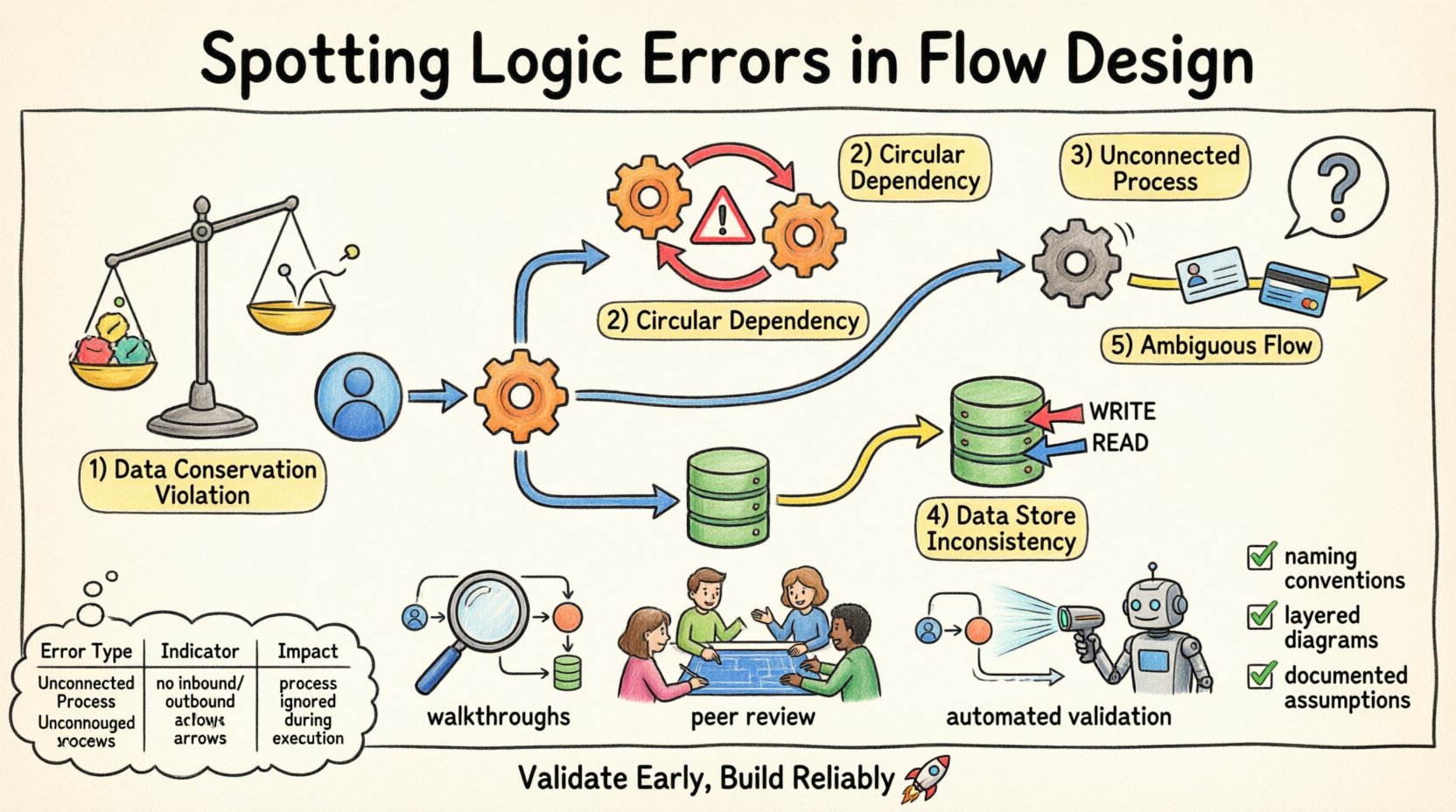
1. 数据守恒违规 📉
数据守恒定律指出,数据在过程中不能被创造或销毁。如果流程图显示数据从一个过程中出现但没有明确来源,就违反了这一法则。相反,如果数据进入一个过程后消失,且未被存储或输出,就会丢失。这通常发生在设计师忘记绘制输出箭头时。
例如,如果客户订单处理过程接收了订单详情,但仅输出确认收据,那么支付信息就缺失了。这表明逻辑上存在漏洞。系统无法在未考虑所有输入和输出的情况下正常运行。
2. 循环依赖 🔄
当过程A向过程B提供数据,而过程B又将数据反馈给过程A,且中间没有其他步骤时,就会发生循环依赖。在静态图中,这看起来像一个环。虽然时间驱动的系统中存在循环,但在逻辑流程设计中,这通常表示系统无法解决的死锁或无限递归。
识别这类问题需要追踪数据的路径。如果一个过程依赖于另一个过程的输出,而后者又在等待第一个过程的输出,那么流程就会停滞。这是一个关键的逻辑错误,会导致系统执行中断。
3. 未连接的过程 🚫
未连接的过程是指没有输入数据流的过程。没有输入,过程就无法执行,成为一个逻辑孤岛。同样,没有输出流的过程也不会对系统的整体输出做出贡献。虽然内部过程可能不需要直接的外部输出,但它们最终必须接入一条通向数据存储或外部实体的链路。
孤立的过程表明设计不完整。它们消耗资源却无法提供价值。发现这些过程需要对图表中的每个节点进行连通性分析。
4. 数据存储不一致 🗄️
数据存储代表持久化信息。当过程在没有适当授权或上下文的情况下读取或写入数据存储时,就会产生逻辑错误。例如,一个过程可能在未验证用户权限的情况下更新记录,或者一个过程可能读取了仅由另一个尚未运行的过程写入的数据。
另一个常见问题是,不同的过程在没有同步的情况下同时读取和写入同一个数据存储。这会在逻辑模型中造成竞争条件。图表必须清晰地显示写入和读取路径,以避免歧义。
5. 模糊的数据流 🌫️
数据流必须命名并清晰描述。模糊的流是指携带多种类型数据但未加区分的流。如果一个箭头同时表示“用户ID”和“信用卡号”,逻辑就存在缺陷,因为这些数据元素具有不同的安全性和处理要求。
将这些流分开,可以确保每条信息都按照其特定规则进行处理。模糊性会导致下游的安全漏洞和处理错误。
| 错误类型 | 指示 | 影响 |
|---|---|---|
| 数据守恒 | 数据出现/消失 | 数据丢失或损坏 |
| 循环依赖 | 过程A → 过程B → 过程A | 系统死锁 |
| 未连接的过程 | 没有输入或输出箭头 | 资源浪费 |
| 数据存储不一致 | 不受控制的读写 | 数据完整性问题 |
| 模糊的数据流 | 一个数据流中混合了多种数据类型 | 安全风险 |
检测方法 🛡️
一旦明确了错误的类型,下一步就是建立一种方法来发现它们。被动审查通常不够。需要主动地对图表进行深入探查。
逐步 walkthrough 演示 🚶
对图表进行一次心理上的逐步追踪。从一个外部实体开始,追踪数据经过每一个处理过程,直到数据存储或另一个实体。在每个节点上提出问题:这个处理过程是否有足够的输入来运行?它是否产生了预期的输出?如果我执行这个逻辑,数据会去往何处?
这种手动追踪迫使设计者动态地可视化数据的流动。它能揭示静态查看所遗漏的漏洞。如果在某个节点上追踪卡住,那很可能就是逻辑错误所在的位置。
同行评审会议 👥
另一个人查看图表会带来全新的视角。评审者可以发现设计者因熟悉而忽视的错误。鼓励评审者质疑假设。请他们找出看似多余或缺失的数据流。
结构化的评审会议能降低遗漏的风险。在这些评审过程中应使用检查清单,以确保涵盖所有错误类别。
自动化验证规则 🤖
虽然此处未提及具体软件,但逻辑验证工具可以扫描图表以发现结构错误。这些工具可以标记未连接的节点、缺失的数据存储或循环引用。它们构成了防范基本逻辑不一致的第一道防线。
使用自动化检查可以让团队将注意力集中在更高层次的逻辑上,而非结构语法。这确保了在添加复杂性之前,基础是稳固的。
逻辑疏忽的成本 💸
为什么这很重要?设计阶段的逻辑错误修复成本最高。如果在编码阶段发现逻辑缺陷,就需要重写模块。如果在部署后才发现,就需要打补丁,甚至可能需要数据迁移。
设想一个数据流缺少验证步骤的情况。这会导致无效数据进入系统。之后,基于这些数据生成的报告将不准确。企业基于错误信息做出决策。清理这些数据并恢复信任的成本,远高于最初修复图表的成本。
此外,逻辑错误可能导致安全漏洞。如果某个数据流允许数据绕过安全检查,敏感信息就会暴露。这可能引发合规性违规和法律后果。预防这些错误不仅关乎效率,更关乎风险管理。
预防策略 🛡️
预防胜于检测。在流程设计的创建过程中实施标准和实践,可以降低错误发生的可能性。
标准化命名规范 🏷️
为流程、数据存储和数据流建立严格的命名规则。流程名称应为动词-名词组合,例如“验证订单”。数据流名称应描述数据内容,例如“订单详情”。这种一致性有助于更容易地发现异常。如果一个数据流被命名为“数据”,很可能过于模糊,应予以仔细审查。
一致的命名也有助于自动化验证。脚本可以解析名称,以检查是否符合逻辑结构。
分层绘图 📑
将复杂系统分解为多个层级。第0层展示高层级流程。第1层将这些流程分解为子流程。这种分层方法可防止图表变得杂乱。杂乱会掩盖逻辑错误。
通过聚焦于特定区域,设计者可以在不忽视整体的情况下,专注于特定子系统的逻辑。在专注的视图中,错误更容易被发现。
假设的文档化 📝
每个图表都伴随着假设。应明确记录这些假设。如果某个流程假设数据始终存在,请明确说明该假设。如果某个数据流暗示存在时间延迟,请予以注明。这些文档为评审者提供了上下文。它解释了为何做出某些逻辑选择。
当假设被记录下来后,就可以对其进行质疑,并与业务需求进行验证。这降低了最终设计中仍存在隐藏逻辑错误的可能性。
验证检查清单 ✅
在最终确定流程设计之前,请逐一核对这份检查清单。它涵盖了逻辑错误通常隐藏的关键区域。
- 输入完整性: 每个流程是否至少有一个输入数据流?
- 输出完整性: 每个流程是否至少有一个输出数据流?
- 数据平衡: 数据量在各流程之间是否保持一致?
- 无死胡同: 是否存在任何不会导向数据存储或外部实体的流程?
- 清晰命名: 所有流程和过程是否都使用了描述性名称?
- 安全性: 敏感的数据流是否已明确标记并进行了逻辑保护?
- 时间敏感性: 是否有任何时间依赖关系已被明确界定?
- 一致性: 数据存储是否与流程中使用的数据一致?
优化设计 🎯
一旦发现错误,优化过程便开始。这包括修改图表以纠正逻辑错误。这并不总是意味着删除元素;有时则需要添加缺失的连接。
例如,如果某个流程没有输出,需确定数据应流向何处。将缺失的箭头添加到相应数据存储或实体上。如果存在循环依赖,应引入缓冲区或队列以打破循环。这可能意味着在设计中增加一个中间步骤。
优化是一个迭代过程。修改后,重新执行走查和检查清单。确保新逻辑经得起审查。在图表通过所有验证步骤之前,不要认为修复已完成。
关于逻辑完整性的最后思考 💡
流程设计的完整性决定了系统的成败。逻辑错误虽隐蔽但破坏力强,会削弱整个架构的可靠性。通过应用严格的检测方法和预防策略,设计者可以构建出按预期运行的系统。
在设计阶段注重细节,可节省后续的时间、金钱和精力。一个经过充分验证的图表,是构建稳定系统的蓝图。优先考虑逻辑一致性,可确保数据在组织中正确、安全且高效地流动。这种方法不仅使系统具备功能性,还具备应对变化的韧性。 🚀
始终关注清晰性和正确性。每一个箭头都至关重要,每一个节点都不可忽视。遵循这些原则,流程设计将成为开发团队值得信赖的资产。