Building robust software systems requires more than just writing functional code. It requires a structured approach to managing the lifecycle of data and processes. A state machine is a fundamental tool for this, providing a clear map of how a system moves from one condition to another. When integrating state diagrams with persistent storage and external services, the complexity increases significantly. This guide explores the technical patterns required to connect state logic to database operations and API interactions effectively.
State machines are not merely theoretical constructs; they are practical implementations that dictate the flow of data. Whether managing order processing, user onboarding, or workflow automation, the integrity of the state is paramount. Integrating this logic with databases ensures that state changes are durable. Connecting with APIs allows the system to react to external triggers. This document details the architectural considerations, implementation patterns, and risk mitigation strategies for this integration.
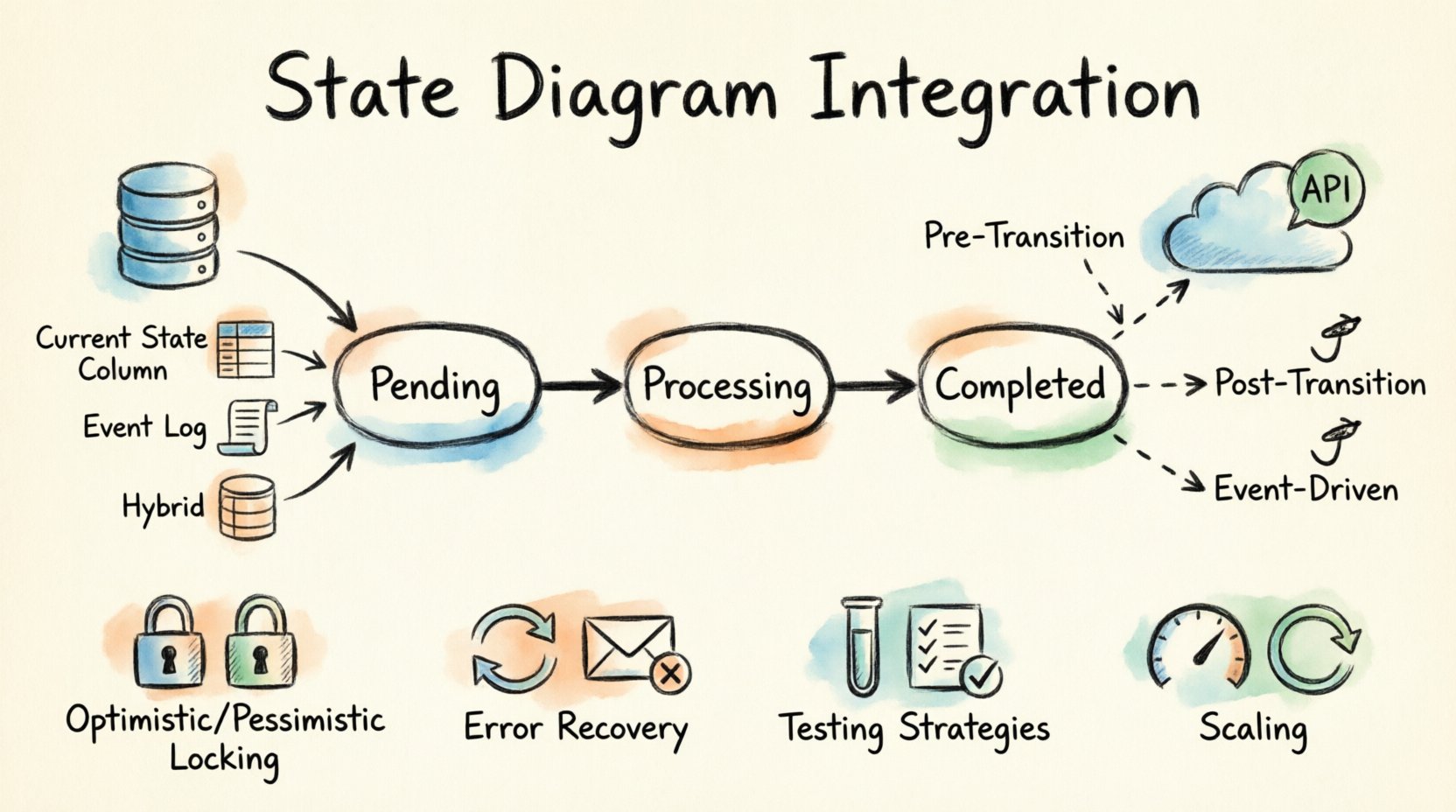
Understanding the Core Architecture 🧩
Before diving into persistence and network logic, it is essential to define the components involved. A state machine consists of three primary elements: states, transitions, and events. Understanding how these interact with external systems forms the basis of integration.
- States: Represent the condition of the entity at a specific moment. Examples include Pending, Processing, or Completed.
- Transitions: The movement from one state to another triggered by an event. This is where logic is applied.
- Events: Signals that trigger a transition. These can come from internal system actions or external API calls.
When integrating, the state must be visible to the database, and the transitions must be capable of invoking API calls. This creates a dependency chain where the database holds the truth, and the API handles the side effects.
Database Persistence Strategies 🗄️
Persistence is the process of storing the current state so that it survives a system restart or failure. How you store state impacts performance, consistency, and recovery capabilities. There are several patterns for mapping state diagram nodes to database rows.
Current State Storage
The most common approach involves storing the current state identifier in a dedicated column within the primary record table. This allows for quick retrieval without scanning logs.
- Implementation: Add a
statusorstate_codecolumn to the main entity table. - Benefit: Fast read performance for checking the current status.
- Risk: If the state logic is complex, a single column may not capture all necessary context.
Event Log Storage
In some architectures, the current state is not stored directly. Instead, the sequence of events is stored in a log. The current state is derived by replaying the events.
- Implementation: Append an event to a table whenever a transition occurs.
- Benefit: Full audit trail and the ability to reconstruct history.
- Risk: Calculating the current state requires processing the entire log, which can be slower.
Comparison of Storage Models
| Model | Read Performance | Write Complexity | Audit Capability |
|---|---|---|---|
| Current State Column | High | Low | Low |
| Event Log | Medium (Requires Replay) | Medium | High |
| Hybrid | High | Medium | Medium |
The hybrid model is often preferred. It stores the current state for quick access while maintaining a log of events for auditing. This ensures that the system knows where it is now, but also knows how it got there.
Database Constraints and Integrity
Ensuring data integrity is critical. The database should enforce rules that prevent invalid state transitions. While application logic is the primary gatekeeper, database constraints provide a safety net.
- Check Constraints: Define valid values for the state column.
- Foreign Keys: Link state logs to the main entity to ensure referential integrity.
- Transactions: Wrap state updates and related data changes in a single transaction to ensure atomicity.
API and External Logic Integration 🔗
State transitions often require action. When a system moves from Pending to Processing, it might need to send a notification, charge a payment, or update an inventory system. These actions are handled via APIs.
Triggering External Calls
API calls should be triggered based on the transition logic. This ensures that side effects only occur when the state change is valid.
- Pre-Transition Hooks: Validate external conditions before allowing the state change.
- Post-Transition Hooks: Execute logic after the state is successfully committed.
- Event-Driven Hooks: Listen for state change events and react asynchronously.
Handling API Failures
Network calls are unreliable. If an API call fails during a state transition, the system must decide how to proceed. Leaving the state in an ambiguous position can cause data corruption.
- Compensating Transactions: If an action fails, trigger a rollback or a specific state to mark the failure (e.g., Failed or Retry).
- Retry Logic: Implement exponential backoff for transient errors.
- Idempotency: Ensure that retrying an API call does not create duplicate records or charges.
Request Patterns
| Pattern | Use Case | Complexity |
|---|---|---|
| Synchronous | Immediate feedback required | Low |
| Asynchronous | Long-running tasks | Medium |
| Fire-and-Forget | Notifications | Low |
Synchronous calls block the state transition until the API responds. This is simple but can lead to timeouts. Asynchronous calls allow the state to update immediately, with a worker processing the external request later. This decouples the state logic from the external dependency latency.
Concurrency and Race Conditions 🔄
When multiple processes attempt to change the state of the same entity simultaneously, race conditions can occur. This is common in distributed systems where requests arrive via different API endpoints.
Optimistic Locking
Optimistic locking assumes that conflicts are rare. It uses a version number or timestamp to detect changes.
- Logic: Read the current version. Update the record with the new state and the incremented version.
- Conflict: If the update affects zero rows, another process modified the record. The transaction rolls back.
- Benefit: High throughput for systems with low contention.
Pessimistic Locking
Pessimistic locking assumes conflicts are likely. It locks the record before reading it.
- Logic: Acquire an exclusive lock on the row. Perform the update. Release the lock.
- Conflict: Other processes wait until the lock is released.
- Benefit: Guarantees order of operations.
- Risk: Can lead to deadlocks if not managed carefully.
Queue-Based State Management
To avoid concurrency issues entirely, route all state change requests through a single queue.
- Implementation: All API requests push an event to a message queue.
- Processing: A single worker processes events sequentially for a specific entity ID.
- Benefit: Eliminates race conditions by design.
Error Handling and Recovery 🛡️
Errors are inevitable. The integration layer must handle them without leaving the state machine in a broken state.
Transaction Boundaries
Define where the transaction begins and ends. A common mistake is committing the database state before the API call succeeds. This leaves the system in a state where the database says Completed, but the external service never received the request.
- Two-Phase Commit: Ensure both the database and the external service agree on the outcome.
- Eventual Consistency: Accept that consistency may be delayed, but ensure a mechanism to fix it.
Dead Letter Queues
If an API call fails repeatedly, move the event to a dead letter queue. This prevents the system from spinning in a retry loop indefinitely.
- Alerting: Notify engineers when items enter the dead letter queue.
- Manual Intervention: Allow operators to retry or discard failed events.
Testing and Validation 🧪
Testing state machines is complex because the number of possible paths grows exponentially. A robust testing strategy covers the logic, the integration points, and the failure scenarios.
Unit Testing State Logic
Test the state machine in isolation from the database and API.
- Input/Output: Feed an event and verify the resulting state.
- Invalid Transitions: Ensure invalid events are rejected.
- Code Coverage: Aim for 100% coverage of state transition rules.
Integration Testing
Test the flow with the database and API mocks.
- Database Schema: Verify that state updates match the schema.
- API Mocks: Simulate API responses (success, failure, timeout) to test error handling.
- End-to-End: Run the full workflow from start to finish in a test environment.
Mutation Testing
Intentionally break the code to see if the tests catch the error.
- Logic Changes: Remove a state transition and verify the test fails.
- Data Changes: Alter the database state and verify the system rejects it.
Scaling and Performance 🚀
As the system grows, the state machine must handle more load without degrading performance.
Caching State
Reading state from the database on every request can be slow. In-memory caches can reduce latency.
- Strategy: Cache the current state for a specific entity ID.
- Invalidation: Ensure the cache is invalidated immediately after a state change.
- Consistency: Accept temporary inconsistencies if the cache hit rate is high.
Database Sharding
If the entity count is large, split the database across multiple shards based on entity ID.
- Benefit: Distributes the load across multiple servers.
- Challenge: Complex queries that span shards become difficult.
Maintenance and Versioning 📝
State machines evolve. New states are added, and old ones are deprecated. Managing this evolution is crucial for long-term stability.
Versioning State Logic
Store the version of the state machine logic alongside the state data.
- Compatibility: Ensure older data can be read by new versions.
- Migration: Write scripts to update existing records to the new schema.
Deprecation Strategy
When removing a state, do not delete it immediately.
- Mark as Deprecated: Add a flag to indicate the state is obsolete.
- Block Transitions: Prevent new transitions into the deprecated state.
- Cleanup: Remove the state definition only after all data has migrated.
Documentation
Maintain a visual diagram that matches the code. This helps new developers understand the system.
- Diagram Tools: Use tools that can generate diagrams from code or configuration.
- Change Logs: Document every change to the state diagram in the version history.
Security Considerations 🔐
State transitions often involve sensitive data. Security must be woven into the integration layer.
- Authorization: Verify that the user requesting the state change has permission for that specific transition.
- Data Validation: Sanitize all input data before processing the state change.
- Logging: Log state changes for security auditing, but ensure sensitive data is masked.
Summary of Best Practices
- Store the current state in the database for fast access.
- Log all events for auditability and reconstruction.
- Use transactions to ensure atomicity between state updates and API calls.
- Implement retry logic with exponential backoff for API failures.
- Use optimistic locking to handle concurrent updates efficiently.
- Test all state transitions, including invalid ones.
- Version your state logic to manage evolution over time.
By following these patterns, developers can build state machines that are resilient, scalable, and maintainable. The integration between state logic, databases, and APIs is the backbone of reliable business processes. Proper design at this level prevents data corruption and ensures that the system behaves predictably under load.