











При моделировании сложных систем основной целью является ясность. Диаграммы потоков данных (DFD) служат основным инструментом для визуализации движения информации через систему. В рамках этой модели два символа доминируют на схеме: Процесс и Хранилище данных. Хотя они часто взаимодействуют, они представляют собой фундаментально разные понятия, касающиеся преобразования и сохранения данных. Понимание различий критически важно для точного анализа и проектирования систем.
Это руководство исследует функциональные роли, визуальные представления и логические последствия этих элементов. Различая действие и хранение, аналитики могут создавать диаграммы, которые безошибочно передают поведение системы.
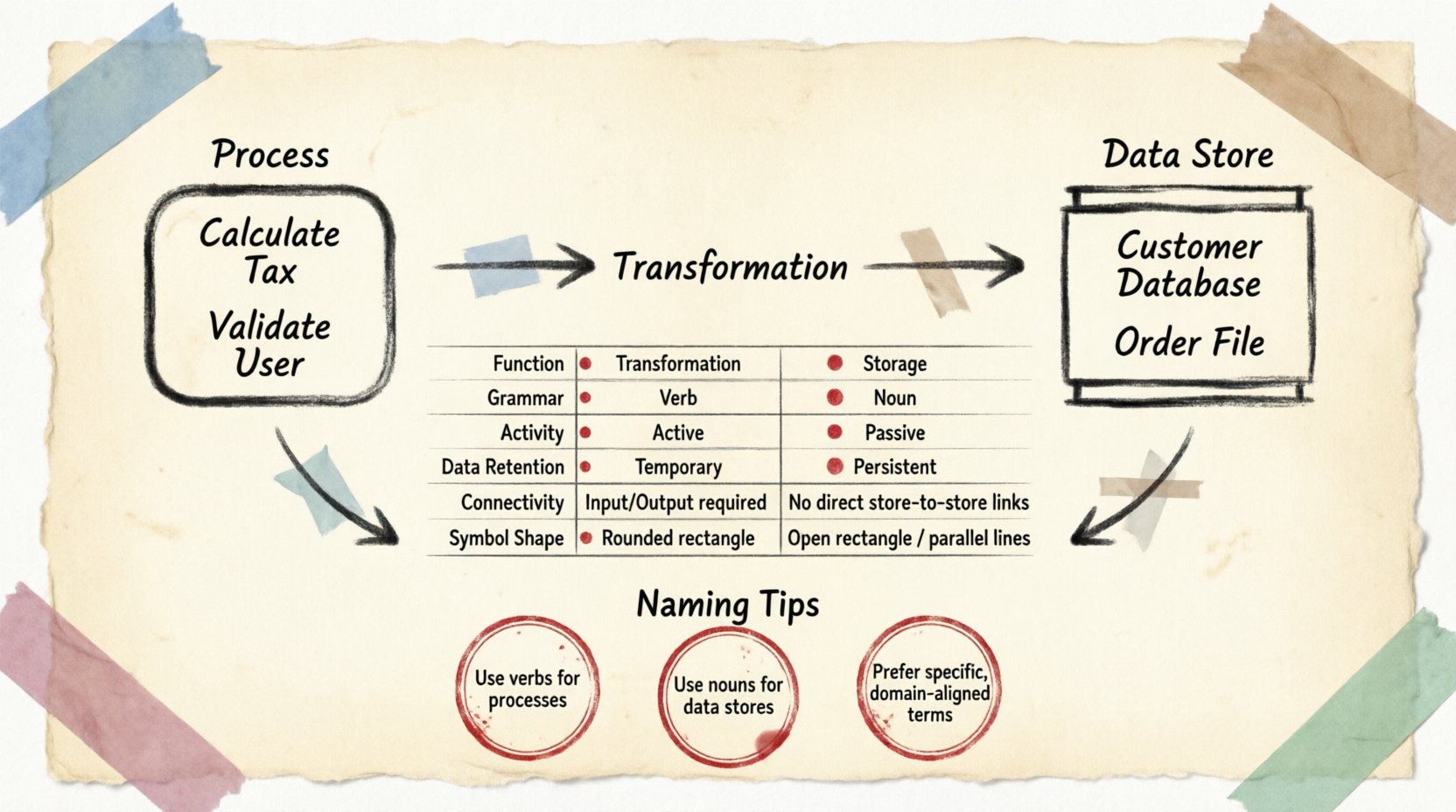
🔄 Определение процесса
Процесс представляет собой единицу работы или преобразования. Именно здесь данные меняют форму, рассчитываются или фильтруются. Представьте процесс как черный ящик. Вы знаете, что входит и что выходит, но внутренний механизм определяется самой логикой преобразования, а не хранением этой информации.
🔹 Основные характеристики
- Преобразование: Основная функция — изменение данных. Входные данные поступают, применяются правила или логика, и выходные данные покидают процесс.
- Временная природа: Процессы активны только при запуске. Они не сохраняют данные между выполнениями.
- Направленность: Данные поступают в процесс и выходят из него. Процесс без входных или выходных данных логически недопустим в контексте DFD.
- Имя с глаголом: Процессы обычно обозначаются глаголами или глагольными фразами (например, Рассчитать налог, Проверить пользователя, Создать отчет).
🔹 Концепция черного ящика
На высоком уровне моделирования процесс является черным ящиком. Основное внимание уделяется чему происходит с данными, а не как происходит технически. Например, процесс с названием «Обработать заказ» принимает данные о заказе и создает запись о транзакции. Он не указывает, происходит ли расчет в памяти, на диске или через удаленный API. Такая абстракция позволяет заинтересованным сторонам сосредоточиться на бизнес-логике, а не на технической реализации.
Однако по мере того, как диаграммы распадаются на более низкие уровни, внутренняя логика становится более детализированной. Даже в этом случае процесс остается активным механизмом преобразования. Он потребляет входные данные, выполняет работу и выдает результат. Он не служит резервуаром для хранения этой информации.
🗄️ Определение хранилища данных
Хранилище данных представляет собой репозиторий, где хранится информация. В отличие от процесса, хранилище данных не преобразует данные. Оно ждет. Оно хранит данные в постоянном состоянии до тех пор, пока процесс не извлечет их или не поместит туда.
🔹 Основные характеристики
- Непрерывность: Данные остаются в хранилище даже тогда, когда процессы не активны. Это ключевое отличие от буферов памяти или временных переменных.
- Пассивный характер: Хранилища данных не инициируют действия. Для чтения или записи в них требуется процесс.
- Имя существительным: Хранилища обычно обозначаются существительными (например, База данных клиентов, Файл заказов, Журнал инвентаря).
- Открытый характер: Потоки данных могут входить и выходить из хранилища. Однако хранилище не может напрямую соединяться с другим хранилищем. Данные должны проходить через процесс для перемещения между репозиториями.
🔹 Концепция репозитория
Представьте библиотеку. Книги — это данные. Полки — это хранилища данных. Библиотекарь — это процесс. Библиотекарь не создает книги; он их организует. Полки сами по себе не перемещают книги; они удерживают их на месте. Когда читатель запрашивает книгу, библиотекарь извлекает её (операция чтения). Когда приходит новая книга, библиотекарь помещает её на полку (операция записи).
В архитектуре системы хранилище данных может представлять таблицу базы данных, плоский файл, очередь или облачный бакет. Символ DFD абстрагирует технологию. Независимо от того, является ли это таблицей SQL или простым текстовым файлом, логическая роль одинакова: это место, где хранится информация.
⚡ Взаимодействие и поток данных
Связь между процессом и хранилищем данных регулируется строгими правилами потока данных. Стрелки в диаграмме потоков данных (DFD) представляют движение данных. Эти стрелки определяют направление передачи информации.
🔹 Цикл чтения-записи
Когда процессу нужна информация, он рисует стрелку от хранилища данных к процессу. Это указывает на операцию чтения. Процесс извлекает данные для использования в своей логике преобразования. Напротив, когда процесс генерирует новую информацию, он рисует стрелку от процесса к хранилищу данных. Это указывает на операцию записи. Данные теперь хранятся для будущего использования.
Крайне важно, что поток данных не может напрямую соединять два хранилища данных. Информация не может перейти из одного репозитория в другой без обработки. Это правило подчеркивает принцип, согласно которому перемещение данных всегда сопровождается каким-либо уровнем логики или контроля, даже если эта логика — простая операция копирования.
🔹 Внешние сущности
Внешние сущности (источники или приемники) взаимодействуют с процессами, а не напрямую с хранилищами данных. Внешняя сущность может быть человеком-пользователем, сторонним API или другой системой. Они отправляют данные процессу или получают данные от процесса. Затем процесс решает, сохранить ли эти данные в репозитории или отбросить.
📋 Таблица сравнения
Для краткого обобщения структурных различий рассмотрим следующий анализ атрибутов.
| Атрибут | Процесс | Хранилище данных |
|---|---|---|
| Функция | Преобразование / Действие | Хранение / Память |
| Грамматика | Глагол (например, Обновить) | Существительное (например, Таблица пользователей) |
| Деятельность | Активный (работает при срабатывании) | Пассивный (ожидает доступа) |
| Хранение данных | Временное (во время выполнения) | Постоянное (долгосрочное) |
| Связность | Связано с сущностями, хранилищами, другими процессами | Связано только с процессами |
| Форма символа | Округлый прямоугольник или круг | Открытый прямоугольник или параллельные линии |
🧩 Правила именования
Согласованность в именовании предотвращает путаницу на этапах проверки и реализации. Неоднозначность часто возникает, когда одно и то же слово используется как для хранения, так и для действия.
🔹 Именование процессов
Имена должны описывать действие, выполняемое с данными. Избегайте общих названий, таких как «Сделать это» или «Обработать». Вместо этого используйте конкретные описания. Например, «Проверить учетные данные входа» лучше, чем «Проверить вход». Такая ясность помогает разработчикам сразу понять ожидаемые требования к входным и выходным данным.
🔹 Именование хранилищ данных
Имена должны отражать содержимое, хранящееся внутри. Используйте множественное число или четкие идентификаторы. «Orders» (Заказы) указывает на набор записей о заказах. «Order» (Заказ) может означать единичный экземпляр транзакции. Хотя контекст имеет значение, множественное число обычно указывает на хранилище, содержащее несколько записей.
При именовании хранилищ данных учитывайте масштаб. Название «Database» (База данных) слишком общее. Названия «Customer Database» (База данных клиентов) или «Transaction Log» (Журнал транзакций) предоставляют необходимый контекст. Такая детализация помогает позже сопоставить диаграмму с физическими структурами хранения.
🧪 Декомпозиция и уровни
DFD являются иерархическими. Диаграмма высокого уровня (диаграмма контекста) показывает систему как один процесс. По мере декомпозиции на более низкие уровни различие между процессом и хранилищем становится более важным.
🔹 Уровень 0 против Уровня 1
На диаграмме контекста вся система представляет собой один процесс. На уровне 0 этот процесс разбивается на основные подпроцессы. Здесь вводятся хранилища данных, чтобы показать, где находятся основные компоненты данных. На уровне 1 и далее процессы дополнительно уточняются.
Во время декомпозиции убедитесь, что хранилища данных не дублируются без необходимости. Если хранилище существует на уровне 0, оно обычно сохраняется на уровне 1, если только конкретный подпроцесс не требует временного кэша (который будет другим хранилищем). Согласованность на разных уровнях обеспечивает отслеживаемость.
🔹 Сбалансированность
Критическое правило при декомпозиции — «Сбалансированность». Входы и выходы родительского процесса должны соответствовать входам и выходам дочерних процессов на диаграмме более низкого уровня. Хранилища данных также должны быть согласованы. Если хранилище присутствует на родительской диаграмме, дочерняя диаграмма должна правильно учитывать этот поток данных. Если процесс разделяется, поток данных к хранилищу должен сохраняться на обоих участках разделения.
⚠️ Логические ошибки, которые следует избегать
Некоторые структурные ошибки могут сделать диаграмму недействительной. Признание этих ошибок на раннем этапе экономит время на этапе разработки.
- Призрачные потоки данных: Стрелка, покидающая процесс без входящего потока данных, невозможна. Процесс не может создавать выходные данные из ничего. Каждый выходной поток должен быть получен из входных данных или из хранимых данных.
- Прямые соединения хранилищ: Как уже упоминалось, хранилище не может подключаться к другому хранилищу. Данные должны проходить через процесс. Это гарантирует, что все перемещения данных являются осознанными и обработанными.
- Не подключенные процессы: Процесс, не имеющий входящих или исходящих потоков данных, изолирован. Он не взаимодействует с системой и не выполняет никакой функции в диаграмме потоков данных.
- Смешение сущностей и хранилищ: Внешние сущности находятся за пределами границы системы. Хранилища данных находятся внутри. Не размещайте символ внешней сущности внутри границы системы, как будто это база данных.
🛠️ Последствия реализации
Различие между процессом и хранилищем влияет на то, как строится система. Процессы отображаются на функции, методы или микросервисы. Хранилища данных отображаются на таблицы, файлы или объектное хранилище.
🔹 Проектирование базы данных
При проектировании базы данных хранилища данных на диаграмме потоков данных становятся чертежом схемы. Атрибуты в стрелках потоков данных определяют столбцы. Связи между хранилищами (посредством процессов) определяют внешние ключи или транзакционные связи.
🔹 Автоматизация рабочих процессов
Для движков рабочих процессов процессы представляют этапы в конвейере. Хранилища данных представляют состояние рабочего процесса. Процесс может обновить состояние в хранилище, чтобы отметить выполнение задачи. Понимание пассивной природы хранилища гарантирует, что движок рабочего процесса ждет правильного состояния перед продолжением.
🔍 Стандарты визуального представления
Разные методологии используют немного отличающиеся символы, но логика остается неизменной.
- Демарко и Юродон: Использует закругленные прямоугольники для процессов и прямоугольники с открытым концом для хранилищ данных.
- Гейн и Сарсон: Использует закругленные прямоугольники для процессов и параллельные линии для хранилищ данных.
Независимо от выбранной нотации, семантическое значение одинаково. Процесс действует; хранилище хранит. Согласованность в документации проекта важнее соблюдения конкретного стандарта, при условии, что команда понимает выбранную конвенцию.
🎯 Обобщение ролей
Построение надежной модели системы требует дисциплины при распределении ролей. Процесс — это исполнитель. Он выполняет работу. Хранилище данных — это сцена. Оно хранит реквизиты. Без исполнителя сцена пуста. Без сцены исполнитель не знает, куда положить свои результаты.
Сохраняя четкое разделение между преобразованием и хранением, аналитики создают диаграммы, которые не только визуально привлекательны, но и логически обоснованы. Эти диаграммы служат договором между бизнес-заинтересованными сторонами и техническими командами. Они определяют границы ответственности и поток стоимости.
При проверке диаграммы потоков данных задавайте два вопроса для каждого символа: «Это выполняет работу?» (Процесс) или «Это хранит информацию?» (Хранилище). Если ответ неясен, уточните метку или соединение. Четкость — это конечная цель моделирования системы.
Соблюдение этих принципов гарантирует, что полученная архитектура будет поддерживаемой, масштабируемой и понятной. Различие простое, но его влияние на целостность системы глубоко.