











В современной архитектуре информационных систем целостность данных является основой надежного поведения системы. Когда данные поступают в среду обработки, они несут потенциальные риски, которые могут нарушить работу, подорвать безопасность или повредить выходные данные. Проверка входных данных системы — это не просто проверка безопасности, а фундаментальное логическое требование, встроенное в архитектуру системы. Используя логику потока в диаграммах потоков данных (DFD), инженеры могут точно определить, где происходит проверка, как обрабатываются ошибки и как данные перемещаются по архитектуре. Такой подход гарантирует, что каждый элемент информации, поступающий в систему, соответствует необходимым критериям, прежде чем повлиять на бизнес-логику.
В этой статье рассматриваются механизмы проверки входных данных через призму логики потока. Мы изучим, как визуально отображать правила проверки, как структурировать точки принятия решений для приема данных и как управлять состояниями ошибок без нарушения потока. Понимание этих механизмов позволяет архитекторам создавать системы, устойчивые к некорректным данным и внешним угрозам.
Понимание диаграмм потоков данных при проверке 📊
Диаграммы потоков данных предоставляют визуальное представление о том, как информация перемещается по системе. Они отображают процессы, хранилища данных, внешние сущности и сами данные. В контексте проверки DFD становится картой доверия. На ней показано, где данные принимаются, где они проверяются и где они хранятся или удаляются.
Стандартная DFD состоит из четырех основных элементов:
- Процесс: Преобразование данных. Именно здесь обычно находится логика проверки.
- Хранилище данных: Хранилище, где сохраняются данные. Проверка должна происходить до того, как данные попадут в хранилище.
- Внешняя сущность: Источник или пункт назначения данных за пределами границ системы. Входные данные исходят отсюда.
- Поток данных: Перемещение данных между элементами. Проверки данных происходят вдоль этих путей.
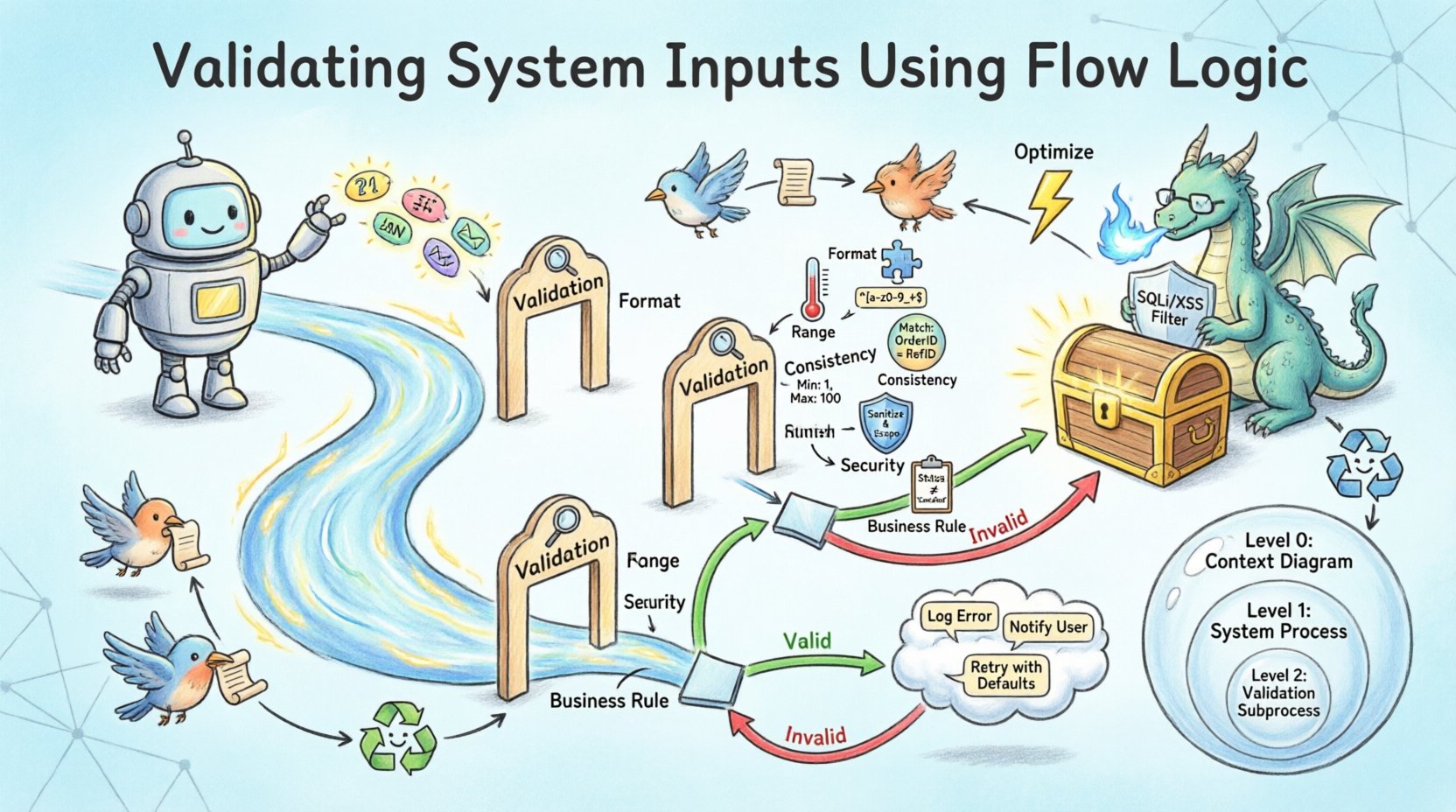
При проектировании с учетом проверки элемент «Процесс» становится критически важным. Просто перемещать данные из точки А в точку Б недостаточно. Процесс должен оценивать данные по набору правил. На диаграмме это часто отображается как специальный подпроцесс с меткой «Проверка» или «Очистка». Этот визуальный элемент напоминает разработчикам, что здесь существует логика фильтрации входных данных.
Сопоставление логики проверки с структурами потока 🧠
Логика потока — это последовательность операций, определяющих путь данных. При проверке эта логика определяет, будет ли данные переданы на следующий этап или направлены на обработку ошибок. Реализация этого требует четкого понимания точек принятия решений.
Рассмотрим форму ввода данных, собирающую информацию о пользователе. Логика потока должна проверить следующие атрибуты:
- Наличие: Заполнено ли поле?
- Тип: Является ли ввод правильным типом данных (например, целое число или строка)?
- Диапазон: Находится ли значение в допустимых пределах?
- Формат: Соответствует ли строка требуемому шаблону (например, адрес электронной почты)?
На DFD эти проверки создают ветвления. Если данные проходят все проверки, поток продолжается к основному процессу. Если проверка не пройдена, поток направляется на обработку ошибок. Такие ветвления необходимы для надежной архитектуры. Без них некорректные данные могут бесшумно распространяться, что приведет к ошибкам вычислений или уязвимостям безопасности.
Механизм точек принятия решений
Точки принятия решений — это места, где поток разделяется. На диаграммах логики потока это часто изображается в виде ромба или специального узла процесса, который генерирует два разных потока данных: один помечен как «Допустимо», другой — как «Недопустимо». Поток «Допустимо» продолжает работу в основном потоке обработки. Поток «Недопустимо» запускает ответ об ошибке или цикл исправления.
Важно различать клиентскую и серверную проверку в диаграмме. Хотя клиентская проверка улучшает пользовательский опыт, серверная проверка является настоящим барьером. На DFD проверка на стороне сервера должна быть последним барьером перед тем, как данные достигнут хранилища данных. Это гарантирует, что даже если интерфейс будет обойден, основная система останется защищенной.
Типы правил проверки входных данных 🛡️
Проверка — это не монолитное понятие. Она включает несколько уровней контроля. Каждый уровень выполняет свою функцию и требует различных стратегий реализации в логике потока.
| Тип проверки | Цель | Пример логики |
|---|---|---|
| Проверка формата | Обеспечивает соответствие данных ожидаемой структуре | Соответствие регулярным выражениям для номеров телефонов |
| Проверка диапазона | Обеспечивает, чтобы данные находились в пределах числовых ограничений | Возраст должен быть от 18 до 120 лет |
| Проверка согласованности | Обеспечивает соответствие данных другим входным данным | Дата окончания должна быть позже даты начала |
| Проверка безопасности | Предотвращает внедрение вредоносного кода | Очищает HTML-теги в текстовых полях |
| Проверка бизнес-правил | Обеспечивает соответствие данных операционным ограничениям | Скидка не может превышать 50% |
Интеграция этих правил в логику потока требует тщательной последовательности. Проверка безопасности, как правило, должна выполняться на ранних этапах процесса, чтобы предотвратить дорогостоящую обработку вредоносных данных. Проверка формата обычно является первым шагом, чтобы убедиться в правильности типов данных перед выполнением логических сравнений. Проверка бизнес-правил часто выполняется последней, поскольку может зависеть от данных, уже приведённых к нормализованному виду.
Обработка потоков ошибок и обратных связей 🔄
Надёжная система не просто отклоняет недопустимые данные; она грамотно обрабатывает отклонение. Именно здесь вступает в действие ветвь «Недопустимо» логики потока. Поток ошибок должен приводить к механизму, информирующему пользователя или системного администратора об ошибке, не раскрывая при этом чувствительных внутренних деталей.
В диаграмме потоков данных (DFD) процесс обработки ошибок должен включать:
- Ведение журнала: Записывает детали ошибки для отладки. Этот поток направляется в хранилище журнала аудита.
- Уведомление: Оповещает пользователя. Этот поток направляется во внешнюю сущность (интерфейс пользователя).
- Исправление: Предоставляет механизм для исправления данных. Это создаёт цикл обратной связи, при котором данные возвращаются на этап ввода.
Циклы обратной связи критически важны для удобства использования. Если пользователь отправляет форму с недопустимым адресом электронной почты, система должна позволить ему немедленно исправить ошибку. В терминах потока данных, данные не покидают этап ввода навсегда. Они повторно проверяются на соответствие логике проверки до тех пор, пока не пройдут проверку или пользователь не отменит действие. Это предотвращает заторы в пользовательском пути.
Ведение журнала ошибок и аудиторские следы
Безопасность и соответствие требованиям часто требуют записи неудач проверки. Даже если входные данные отклонены, сам факт попытки может быть признаком атаки. Поэтому должен существовать отдельный поток данных от процесса проверки к журналу аудита. Этот поток фиксирует временные метки, исходные IP-адреса и характер сбоя. Он работает независимо от основного потока данных, чтобы обеспечить, что сбои в ведении журнала не блокировали легитимную обработку.
Интеграция проверки на уровнях процессов 🏗️
Диаграммы потоков данных часто существуют на разных уровнях абстракции. Уровень 0 предоставляет общий обзор, тогда как уровни 1 и 2 детализируют конкретные процессы. Логика проверки должна быть согласованной на всех этих уровнях.
Уровень 0: Граница системы
На самом высоком уровне проверка представляется в виде ворот. Внешняя сущность отправляет данные, а система принимает или отклоняет их. Диаграмма потоков данных показывает границы входа и выхода. Любые данные, которые не проходят проверку на этом этапе, никогда не попадают во внутреннюю систему.
Уровень 1: Разбиение процессов
При декомпозиции системы конкретные процессы получают подпотоки проверки. Например, процесс «Регистрация пользователя» может быть разделён на «Проверка личности», «Проверка пароля» и «Проверка контакта». Каждый из этих подпроцессов имеет свою собственную логику потока. Диаграмма потоков данных на этом уровне показывает внутреннее перемещение данных, необходимое для выполнения этих проверок.
Уровень 2: Подробная логика
На самом низком уровне логика полностью определена. Именно здесь из диаграммы извлекается фактическая структура кода. Логика потока здесь определяет точный порядок операций. Например, проверка наличия имени пользователя в базе данных должна выполняться до проверки его формата, чтобы избежать утечки информации о существующих пользователях.
Оптимизация производительности во время проверки ⚡
Логика проверки добавляет вычислительную нагрузку. Каждая проверка требует времени обработки. В системах с высокой нагрузкой чрезмерная проверка может стать узким местом. Диаграмма потоков данных помогает определить, где требуется оптимизация.
Стратегии оптимизации включают:
- Ранний выход: Если базовая проверка не проходит (например, пустое поле), немедленно остановить обработку. Не запускать сложную логику.
- Кэширование: Если проверка зависит от внешних данных (например, проверка идентификатора пользователя против списка забаненных аккаунтов), кэшируйте эти данные, чтобы сократить количество обращений к базе данных.
- Асинхронная обработка: Для не критичных проверок перенесите проверку в фоновую очередь. Это сохранит высокую скорость основного потока данных.
При представлении этих оптимизаций на диаграмме потоков данных используйте отдельные потоки данных для синхронных и асинхронных задач. Это уточняет, какие проверки блокируют пользователя, а какие выполняются в фоновом режиме. Это также помогает в сценариях нагрузочного тестирования, когда необходимо понять поведение системы под нагрузкой.
Безопасность логики потока 🔒
Некорректный ввод является основным вектором атак, таких как SQL-инъекции, межсайтовый скриптинг и переполнение буфера. Логика потока, предназначенная для проверки, действует как брандмауэр. Однако дизайн должен быть правильным.
Частая проблема при проектировании — предположение, что входные данные поступают из доверенного источника. На диаграмме потоков данных каждая внешняя сущность должна рассматриваться как потенциально враждебная. Процесс проверки должен очищать данные до их взаимодействия с базами данных или командными строками. Эта очистка данных — это специальный узел процесса на диаграмме.
Кроме того, логика потока должна предотвращать утечку информации. Если сообщение об ошибке указывает, что имя пользователя существует, злоумышленник может использовать это для перечисления аккаунтов. Поток ошибок должен предоставлять общие сообщения (например, «Неверные учетные данные»), а не конкретные причины (например, «Имя пользователя не найдено»). Эта тонкость должна быть отражена в описании обработки ошибок.
Тестирование и верификация потоков проверки ✅
После проектирования логики потока она должна быть проверена. Тестирование включает отправку данных по путям диаграммы потоков данных, чтобы убедиться, что логика работает корректно. Обычно это делается с помощью юнит-тестов для отдельных правил проверки и интеграционных тестов для всего потока.
Тестовые сценарии должны охватывать:
- Путь успеха: Корректные данные проходят все проверки и достигают хранилища данных.
- Граничные случаи: Данные на границах диапазонов (например, минимальные и максимальные значения).
- Повреждённые данные: Данные с неправильными типами или неожиданными символами.
- Отсутствующие данные: Данные, где отсутствуют обязательные поля.
Если диаграмма потоков данных точна, результаты тестов должны соответствовать визуализированным потокам. Если тестовый сценарий завершается неудачно неожиданным образом, диаграмма должна быть обновлена. Этот итеративный процесс гарантирует, что документация остаётся точным отражением поведения системы.
Заключение по структурированной проверке 📝
Проверка входных данных системы с использованием логики потока превращает требование безопасности в структурный элемент архитектуры. Сопоставляя правила проверки в диаграммах потоков данных, команды могут визуализировать, где происходит проверка данных, как обрабатываются ошибки и как информация перемещается по системе. Эта ясность снижает неоднозначность, улучшает коммуникацию между дизайнерами и разработчиками и в конечном итоге приводит к более стабильному программному обеспечению. Интеграция точек принятия решений, потоков ошибок и проверок безопасности обеспечивает устойчивость системы к неизбежным помехам из внешнего мира.
По мере роста сложности систем зависимость от структурированной логики потока становится ещё более критичной. Она служит чертежом для поддержания целостности данных на протяжении времени. Следуя принципам, изложенным здесь, архитекторы могут создавать потоки, которые доверяют ничему и проверяют всё, обеспечивая долговечность и надёжность экосистемы данных.