











Na arquitetura de informações moderna, a integridade dos dados é a base do comportamento confiável do sistema. Quando os dados entram em um ambiente de processamento, carregam riscos potenciais que podem interromper operações, comprometer a segurança ou corromper saídas downstream. Validar entradas do sistema não é meramente uma verificação de segurança; é uma exigência lógica fundamental incorporada no design do sistema. Ao utilizar a lógica de fluxo em Diagramas de Fluxo de Dados (DFDs), engenheiros podem mapear exatamente onde ocorre a validação, como os erros são tratados e como os dados transitam pela arquitetura. Essa abordagem garante que cada peça de informação que entra no sistema atenda aos critérios necessários antes de influenciar a lógica de negócios.
Este artigo explora a mecânica da validação de entradas sob a perspectiva da lógica de fluxo. Analisaremos como representar regras de validação visualmente, como estruturar pontos de decisão para aceitação de dados e como gerenciar estados de erro sem interromper o fluxo. Compreender essas mecânicas permite que arquitetos construam sistemas resilientes a dados malformados e ameaças externas.
Compreendendo Diagramas de Fluxo de Dados na Validação 📊
Diagramas de Fluxo de Dados fornecem uma representação visual de como a informação se move através de um sistema. Eles representam processos, armazenamentos de dados, entidades externas e os próprios dados. No contexto da validação, o DFD torna-se um mapa de confiança. Mostra onde os dados são recebidos, onde são verificados e onde são armazenados ou descartados.
Um DFD padrão consiste em quatro elementos principais:
- Processo: Uma transformação de dados. É aqui que normalmente reside a lógica de validação.
- Armazenamento de Dados: Um repositório onde os dados são salvos. A validação deve ocorrer antes que os dados entrem em um armazenamento.
- Entidade Externa: Uma fonte ou destino de dados fora da fronteira do sistema. As entradas originam-se aqui.
- Fluxo de Dados: O movimento de dados entre elementos. As verificações de validação ocorrem ao longo desses caminhos.
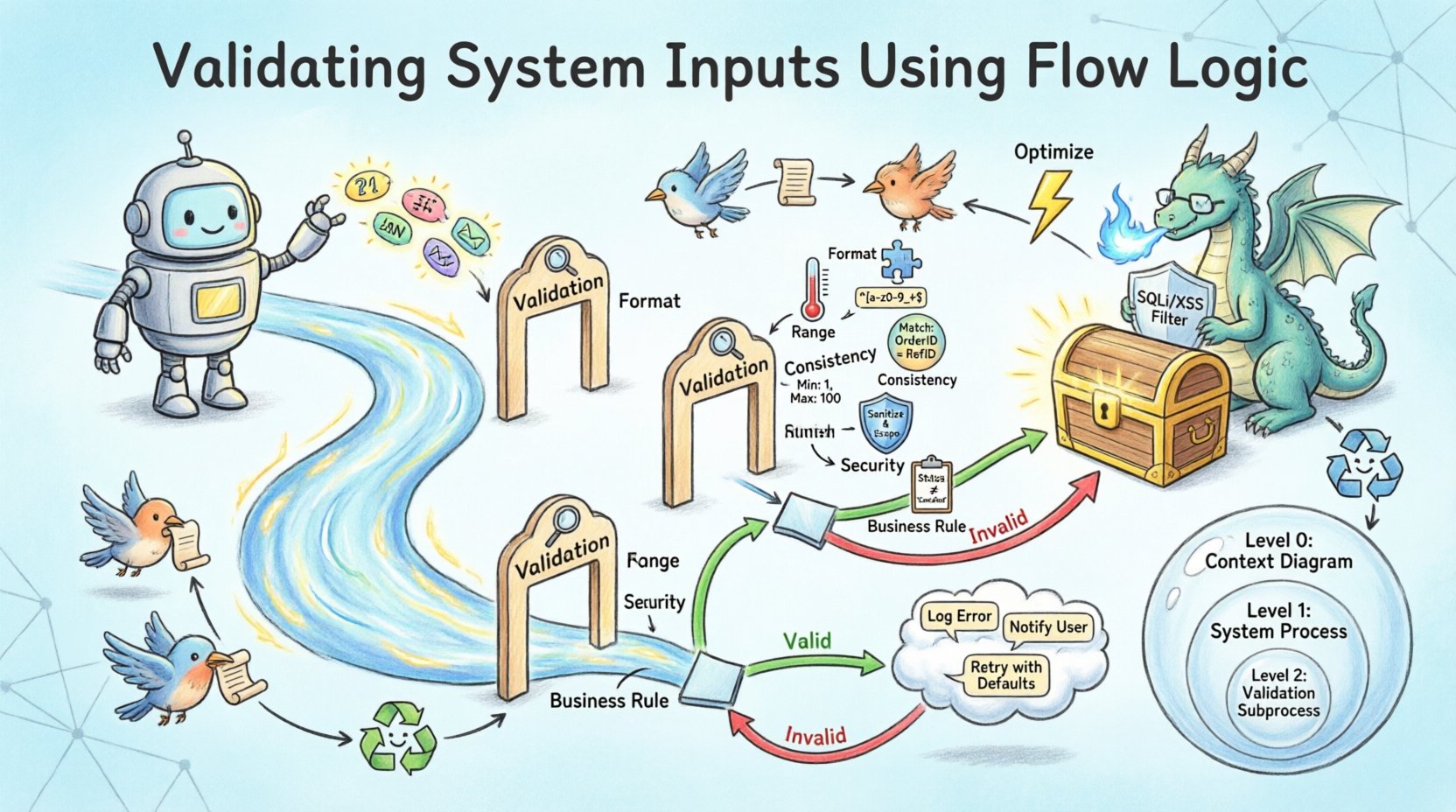
Ao projetar para validação, o elemento Processo torna-se crítico. Não basta mover dados do ponto A ao ponto B. O Processo deve avaliar os dados com base em um conjunto de regras. No diagrama, isso é frequentemente representado por um sub-processo específico rotulado como “Validação” ou “Sanitização”. Esse indicador visual lembra aos desenvolvedores que existe lógica aqui para filtrar as entradas.
Mapeando a Lógica de Validação para Estruturas de Fluxo 🧠
A lógica de fluxo refere-se à sequência de operações que determinam o caminho dos dados. Na validação, essa lógica determina se os dados prosseguem para a próxima etapa ou são desviados para um manipulador de erros. Implementar isso exige uma compreensão clara dos pontos de decisão.
Considere um formulário de entrada de dados que coleta informações do usuário. A lógica de fluxo deve verificar os seguintes atributos:
- Presença: O campo está preenchido?
- Tipo: A entrada é do tipo de dado correto (por exemplo, inteiro vs. string)?
- Faixa: O valor está dentro dos limites aceitáveis?
- Formato: A string corresponde ao padrão exigido (por exemplo, endereço de e-mail)?
Em um DFD, essas verificações criam ramificações. Se os dados passarem por todas as verificações, o fluxo avança para o processo principal. Se falharem, o fluxo é desviado para um processo de tratamento de erros. Essa ramificação é essencial para uma arquitetura robusta. Sem ela, dados inválidos poderiam se propagar silenciosamente, levando a erros de cálculo ou vulnerabilidades de segurança.
O Mecanismo de Ponto de Decisão
Pontos de decisão são onde o fluxo se divide. Em diagramas de lógica de fluxo, isso é frequentemente visualizado como uma forma de losango ou um nó de processo específico que produz dois fluxos de dados distintos: um rotulado como “Válido” e outro rotulado como “Inválido”. O fluxo “Válido” continua para a pipeline principal de processamento. O fluxo “Inválido” dispara uma resposta de erro ou um loop de correção.
É importante distinguir entre validação do lado do cliente e do lado do servidor no diagrama. Embora a validação do lado do cliente melhore a experiência do usuário, a validação do lado do servidor é o verdadeiro guardião. No DFD, a verificação do lado do servidor deve ser a última barreira antes que os dados alcancem o armazenamento de dados. Isso garante que, mesmo que a interface seja contornada, o sistema central permaneça protegido.
Tipos de Regras de Validação de Entrada 🛡️
A validação não é um conceito monolítico. Ela abrange várias camadas de escrutínio. Cada camada serve um propósito diferente e exige estratégias de implementação distintas na lógica de fluxo.
| Tipo de Validação | Propósito | Lógica de Exemplo |
|---|---|---|
| Validação de Formato | Garante que os dados correspondam à estrutura esperada | Correspondência de expressão regular para números de telefone |
| Validação de Faixa | Garante que os dados estejam dentro dos limites numéricos | A idade deve estar entre 18 e 120 |
| Validação de Consistência | Garante que os dados estejam alinhados com outras entradas | A data final deve ser posterior à data inicial |
| Validação de Segurança | Evita a injeção de código malicioso | Limpeza de tags HTML em campos de texto |
| Validação de Regras de Negócio | Garante que os dados estejam de acordo com as restrições operacionais | O desconto não pode exceder 50% |
Integrar essas regras na lógica de fluxo exige uma sequência cuidadosa. A validação de segurança geralmente deve ocorrer cedo no processo para evitar o processamento dispendioso de cargas maliciosas. A validação de formato geralmente é o primeiro passo para garantir que os tipos de dados estejam corretos antes de comparações lógicas serem feitas. A validação de regras de negócio geralmente ocorre por último, pois pode depender de dados que já foram normalizados.
Tratamento de Fluxos de Erro e Loops de Feedback 🔄
Um sistema robusto não rejeita apenas dados inválidos; ele gerencia essa rejeição de forma elegante. É aqui que a ramificação “Inválida” da lógica de fluxo entra em ação. O fluxo de erro deve levar a um mecanismo que informe o usuário ou administrador do sistema sobre o problema sem expor detalhes internos sensíveis.
No DFD, o processo de tratamento de erros deve incluir:
- Registro: Registre os detalhes do erro para depuração. Esse fluxo vai para um armazenamento de dados de registro de auditoria.
- Notificação: Alertar o usuário. Esse fluxo vai para a entidade externa (interface do usuário).
- Correção: Forneça um mecanismo para corrigir os dados. Isso cria um loop de feedback em que os dados retornam à fase de entrada.
Loops de feedback são críticos para a usabilidade. Se um usuário enviar um formulário com um endereço de e-mail inválido, o sistema deveria permitir que ele corrigisse imediatamente. Em termos de fluxo, os dados não saem permanentemente da fase de entrada. Eles são reavaliados contra a lógica de validação até que passem ou o usuário cancele a ação. Isso evita pontos sem saída na jornada do usuário.
Registro de Erros e Trilhas de Auditoria
Segurança e conformidade frequentemente exigem que falhas de validação sejam registradas. Mesmo que a entrada seja rejeitada, a tentativa em si pode ser um sinal de um ataque. Portanto, deve existir um fluxo de dados separado da validação para um registro de auditoria. Esse fluxo captura horários, endereços IP de origem e a natureza da falha. Ele opera de forma independente do fluxo principal de dados para garantir que falhas no registro não bloqueiem o processamento legítimo.
Integração da Validação nos Níveis de Processo 🏗️
Diagramas de Fluxo de Dados frequentemente existem em diferentes níveis de abstração. O Nível 0 fornece uma visão geral, enquanto os Níveis 1 e 2 detalham processos específicos. A lógica de validação deve ser consistente entre esses níveis.
Nível 0: Fronteira do Sistema
No nível mais alto, a validação é representada como uma porta. A entidade externa envia dados, e o sistema aceita ou rejeita esses dados. O DFD mostra as fronteiras de entrada e saída. Qualquer dado que falhe na validação nesta etapa nunca entra no sistema interno.
Nível 1: Decomposição de Processos
Ao decompor o sistema, processos específicos recebem fluxos de validação secundários. Por exemplo, um processo de “Registro de Usuário” pode ser dividido em “Verificação de Identidade”, “Validação de Senha” e “Verificação de Contato”. Cada um desses sub-processos possui sua própria lógica de fluxo. O DFD neste nível mostra o movimento interno de dados necessário para realizar essas verificações.
Nível 2: Lógica Detalhada
No nível mais baixo, a lógica está totalmente definida. É aqui que a estrutura real do código é derivada do diagrama. A lógica de fluxo especifica a ordem exata das operações. Por exemplo, verificar se um nome de usuário existe no banco de dados deve ocorrer antes de verificar se ele tem um formato válido, para evitar vazamento de informações sobre usuários existentes.
Otimização de Desempenho Durante a Validação ⚡
A lógica de validação adiciona sobrecarga computacional. Cada verificação exige tempo de processamento. Em sistemas de alta volume, uma validação excessiva pode se tornar um gargalo. O DFD ajuda a identificar onde a otimização é necessária.
Estratégias de otimização incluem:
- Saída Antecipada: Se uma verificação básica falhar (por exemplo, campo vazio), pare o processamento imediatamente. Não execute lógica complexa.
- Armazenamento em Cache: Se a validação depende de dados externos (por exemplo, verificar um ID de usuário contra uma lista de contas banidas), armazene esses dados em cache para reduzir as chamadas ao banco de dados.
- Processamento Assíncrono: Para validações não críticas, mova a verificação para uma fila de fundo. Isso mantém o fluxo principal de dados rápido.
Ao representar essas otimizações no DFD, use fluxos de dados distintos para tarefas síncronas e assíncronas. Isso esclarece quais validações bloqueiam o usuário e quais são executadas em segundo plano. Também ajuda em cenários de teste de carga, onde o comportamento do sistema sob estresse precisa ser compreendido.
Implicações de Segurança da Lógica de Fluxo 🔒
Entradas inválidas são um vetor principal para ataques como injeção SQL, scripting entre sites e estouros de buffer. A lógica de fluxo projetada para validação atua como uma firewall. No entanto, o design deve ser correto.
Um desafio comum no design é a suposição de que a entrada vem de uma fonte confiável. No DFD, cada entidade externa deve ser tratada como potencialmente hostil. O processo de validação deve sanitizar os dados antes que eles interajam com bancos de dados ou linhas de comando. Essa sanitização é um nó de processo específico no diagrama.
Além disso, a lógica de fluxo deve impedir vazamentos de informações. Se um erro de validação revelar que um nome de usuário existe, um atacante pode usar isso para enumerar contas. O fluxo de erro deve fornecer mensagens genéricas (por exemplo, “Credenciais inválidas”) em vez de razões específicas (por exemplo, “Nome de usuário não encontrado”). Essa sutileza deve ser capturada na descrição do processo de tratamento de erros.
Testes e Verificação dos Fluxos de Validação ✅
Uma vez que a lógica de fluxo é projetada, ela deve ser verificada. Os testes envolvem enviar dados pelos caminhos do DFD para garantir que a lógica seja mantida. Isso geralmente é feito usando testes unitários para regras de validação individuais e testes de integração para todo o fluxo.
Os casos de teste devem cobrir:
- Caminho Feliz:Dados válidos passam por todas as verificações e alcançam o armazenamento de dados.
- Casos de Borda:Dados nos limites dos intervalos (por exemplo, valores mínimos e máximos).
- Dados Malformados:Dados com tipos incorretos ou caracteres inesperados.
- Dados Ausentes:Dados em que campos obrigatórios estão ausentes.
Se o DFD for preciso, os resultados dos testes devem estar alinhados com os fluxos visualizados. Se um caso de teste falhar de uma forma não prevista pelo diagrama, o DFD deve ser atualizado. Esse processo iterativo garante que a documentação permaneça uma representação fiel do comportamento do sistema.
Conclusão sobre Validação Estruturada 📝
Validar entradas do sistema usando lógica de fluxo transforma um requisito de segurança em um componente estrutural da arquitetura. Ao mapear regras de validação dentro de Diagramas de Fluxo de Dados, as equipes conseguem visualizar onde os dados são verificados, como os erros são tratados e como as informações se movem pelo sistema. Essa clareza reduz a ambiguidade, melhora a comunicação entre designers e desenvolvedores e, em última análise, leva a software mais estável. A integração de pontos de decisão, fluxos de erro e verificações de segurança garante que o sistema permaneça robusto diante do ruído inevitável do mundo externo.
Conforme os sistemas crescem em complexidade, a dependência de lógica de fluxo estruturada torna-se ainda mais crítica. Ela fornece um plano mestre para manter a integridade dos dados ao longo do tempo. Ao seguir os princípios aqui descritos, arquitetos podem construir pipelines que não confiam em nada e verificam tudo, garantindo a longevidade e a confiabilidade do ecossistema de dados.