











Em sistemas distribuídos modernos, a confiabilidade de um serviço de backend muitas vezes depende de quão bem ele lida com solicitações concorrentes e recursos compartilhados. Uma das questões mais persistentes e difíceis de reproduzir nesse domínio é o deadlock. Um deadlock ocorre quando dois ou mais processos não conseguem prosseguir porque cada um está esperando que o outro libere um recurso. Esse estado de bloqueio permanente pode parar todo o sistema, causando inconsistência de dados, indisponibilidade de serviço e frustração do usuário. Para mitigar esses riscos, arquitetos e engenheiros precisam ir além de revisões simples de código e adotar uma abordagem visual no design do sistema. Diagramas de comunicação fornecem uma forma estruturada para mapear interações, identificar pontos de contenção potenciais e aplicar padrões de resiliência antes mesmo de o código ser escrito.
Este guia explora a mecânica dos deadlocks em ambientes de backend e demonstra como diagramas de comunicação podem atuar como ferramenta preventiva. Ao visualizar o fluxo de controle e a aquisição de recursos, as equipes conseguem identificar dependências circulares e implementar estratégias para rompê-las. Abordaremos as bases teóricas, técnicas práticas de visualização e padrões arquitetônicos específicos que contribuem para um sistema resiliente.
Compreendendo a Mecânica de um Deadlock 🛑
Antes de abordar a prevenção, é necessário compreender as condições que geram um deadlock. Na ciência da computação, um deadlock não é um evento aleatório; é o resultado de um conjunto específico de condições ocorrendo simultaneamente. Essas condições são frequentemente chamadas de condições de Coffman. Para que um deadlock exista, todas as quatro seguintes condições devem ser verdadeiras:
- Exclusão Mútua:Pelo menos um recurso deve ser mantido em um modo não compartilhável. Apenas um processo pode usar o recurso em qualquer momento dado.
- Segurar e Esperar:Um processo deve estar segurando pelo menos um recurso enquanto espera adquirir recursos adicionais detidos por outros processos.
- Sem Preempção:Recursos não podem ser retirados forçadamente de um processo. Eles devem ser liberados voluntariamente pelo processo que os detém.
- Espera Circular:Existe um conjunto de processos tal que P1 está esperando por P2, P2 está esperando por P3 e assim por diante, até que Pn esteja esperando por P1.
Em um aplicativo de uma única thread, o deadlock é raro. No entanto, em sistemas de backend que lidam com milhares de solicitações concorrentes, essas condições são fáceis de atender. Por exemplo, se o Serviço A detém um bloqueio no Recurso X e espera pelo Recurso Y, enquanto o Serviço B detém o Recurso Y e espera pelo Recurso X, é formada uma espera circular. Sem preempção ou uma ordem cuidadosa, o sistema fica travado.
O Papel dos Diagramas de Comunicação 📊
Diagramas de comunicação são um tipo de diagrama da Linguagem Unificada de Modelagem (UML). Enquanto os diagramas de sequência focam na linha do tempo das mensagens, os diagramas de comunicação enfatizam a organização estrutural dos objetos e os links entre eles. No contexto da resiliência de backend, essa visão estrutural é crucial. Permite que os designers vejamquem está falando com quem e quaisrecursos estão sendo trocados, e não apenas a ordem em que as mensagens chegam.
Ao projetar uma arquitetura de microserviços ou um backend monolítico complexo, os diagramas de comunicação ajudam a responder perguntas críticas:
- Quais serviços exigem acesso exclusivo à mesma tabela do banco de dados?
- Há dependências bidirecionais entre duas unidades de processamento?
- Uma cadeia de solicitações retorna ao remetente antes de ser concluída?
- Qual é a profundidade máxima de bloqueio de recursos aninhados?
Ao mapear essas interações cedo na fase de design, as equipes conseguem identificar cenários potenciais de deadlock que poderiam passar despercebidos em uma revisão puramente centrada no código. O diagrama atua como um contrato de interação, tornando suposições implícitas explícitas.
Mapeando Dependências de Recursos 🗺️
Para usar diagramas de comunicação de forma eficaz na evitação de deadlocks, o diagrama deve representar recursos, e não apenas o fluxo de dados. Diagramas de interação padrão geralmente mostram chamadas entre serviços. No entanto, para analisar bloqueios, devemos anotar os links com identificadores de recursos. Isso exige um nível ligeiramente mais alto de abstração, em que os nós representam processos ou threads, e os links representam recursos compartilhados ou canais de comunicação.
Passos para Criar um Diagrama Consciente de Vivos
- Identifique Recursos Críticos: Liste todos os estados compartilhados, como linhas de banco de dados, manipuladores de arquivos ou buffers de memória. Atribua-lhes identificadores únicos.
- Defina Propriedade: Determine qual serviço ou thread controla atualmente qual recurso. Marque isso no diagrama.
- Trace os Caminhos de Aquisição: Desenhe setas indicando a solicitação de um recurso. Rotule a seta com o nome do recurso.
- Destaque Estados de Espera: Use uma notação específica para mostrar quando um processo está bloqueado esperando por um recurso.
- Analise Ciclos: Procure laços fechados no diagrama onde o Processo A espera pelo Processo B, que espera pelo Processo A.
Identificando Padrões de Espera Circular 🔁
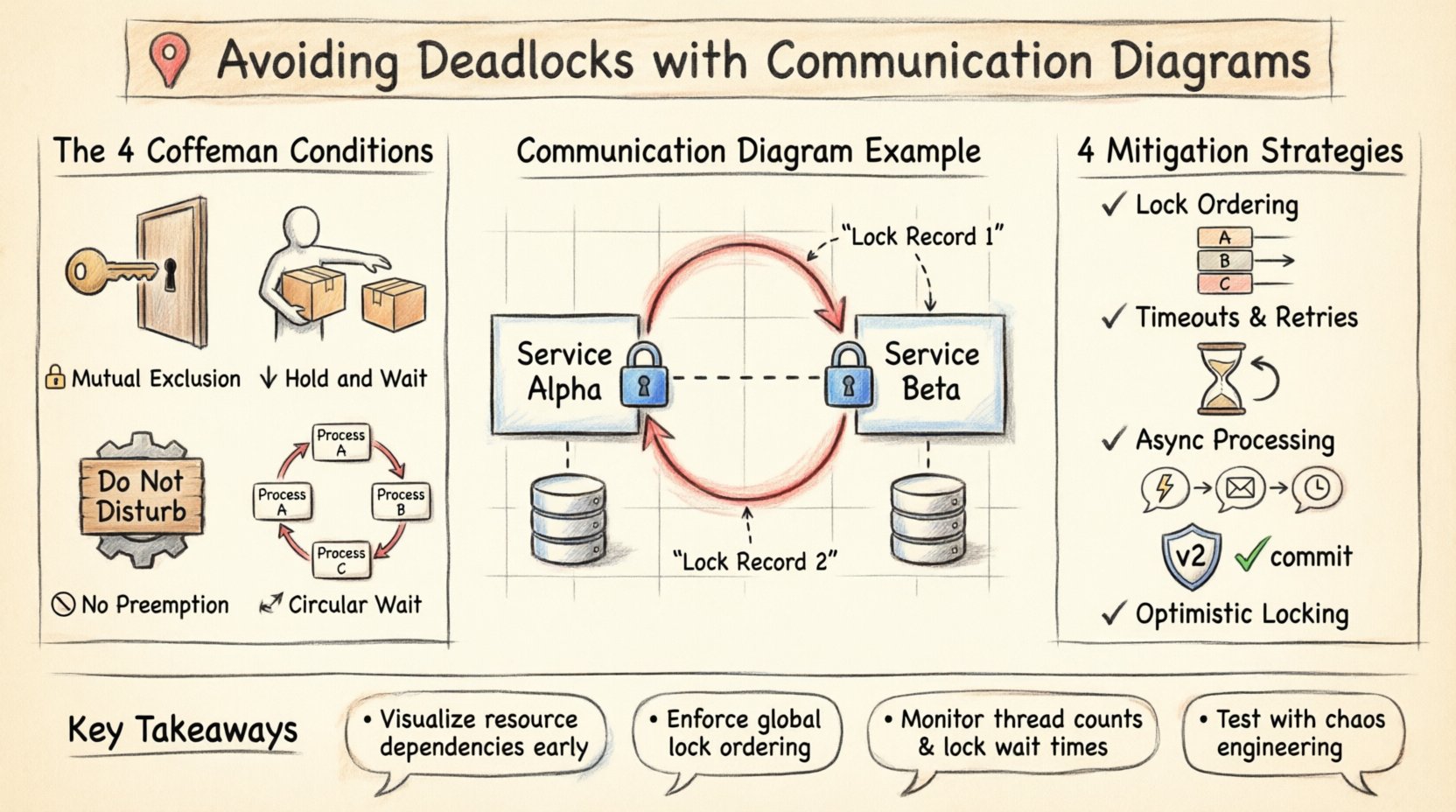
O padrão mais perigoso no design de sistemas é a dependência circular. Em um diagrama de comunicação, isso aparece como um laço fechado de interações. Considere um cenário envolvendo dois serviços, o Serviço Alpha e o Serviço Beta.
- O Serviço Alpha inicia uma transação e bloqueia o Registro 1.
- O Serviço Alpha solicita um bloqueio no Registro 2 ao Serviço Beta.
- O Serviço Beta já detém um bloqueio no Registro 2, mas precisa atualizar o Registro 1, que é detido pelo Alpha.
Em uma representação visual, esse laço é imediatamente evidente. O diagrama mostra Alpha apontando para Beta, e Beta apontando de volta para Alpha, ambos exigindo o recurso detido pelo outro. Sem um diagrama, essa lógica só poderia ser descoberta durante uma falha em produção ou um teste de estresse complexo.
Cenários Comuns que Levam à Circularidade
- Propagação de Transações: Quando uma transação distribuída exige que múltiplos serviços sejam confirmados em uma ordem específica, mas essa ordem não é garantida.
- Chamadas Aninhadas: Uma função chama outra função que eventualmente chama a função original, criando uma cadeia de bloqueios recursiva.
- Cache Compartilhado: Vários serviços tentando atualizar a mesma entrada em cache simultaneamente sem um mecanismo de bloqueio distribuído.
- Chaves Estrangeiras do Banco de Dados: Atualizações em tabelas relacionadas que exigem bloqueios em ambas as tabelas, onde a ordem das atualizações difere entre os serviços.
Técnicas Estratégicas de Mitigação 🛠️
Assim que um diagrama de comunicação revela um possível deadlock, mudanças arquitetônicas específicas são necessárias. Não existe uma única solução que funcione para todos os sistemas, mas existem várias estratégias comprovadas para quebrar as condições de Coffman.
1. Ordenação de Bloqueios
Este é o método mais eficaz para prevenir a espera circular. O sistema deve impor uma ordenação global dos recursos. Se todo processo solicitar recursos na mesma ordem (por exemplo, Recurso A antes do Recurso B), um ciclo não pode se formar. Em um diagrama de comunicação, isso significa garantir que todas as conexões que solicitam o Recurso X sejam estabelecidas antes que qualquer conexão solicite o Recurso Y.
2. Tempo limite e repetições
Mesmo com ordenação, a contenção é possível. Implementar um tempo limite na aquisição de recursos garante que um processo não espere indefinidamente. Se um bloqueio não puder ser adquirido dentro de uma duração especificada, o processo libera seus recursos atuais e tenta novamente. Isso evita que o sistema fique permanentemente travado, embora possa introduzir latência.
3. Processamento Assíncrono
Mudar de solicitações síncronas para arquiteturas assíncronas baseadas em eventos pode reduzir a contenção. Em vez de esperar que um bloqueio seja liberado, um serviço publica um evento e continua o processamento. Quando o recurso ficar disponível, um consumidor trata a atualização. Isso desacopla o momento do uso do recurso.
4. Bloqueio Otimista
Em vez de adquirir um bloqueio antes de ler ou modificar dados, o sistema verifica conflitos no momento do commit. Se outro processo tiver modificado os dados desde a leitura, a transação falha e deve ser repetida. Isso reduz o tempo de detenção dos bloqueios, minimizando a janela para deadlocks.
Comparação de Estratégias de Prevenção
| Estratégia | Previne a Condição | Complexidade | Impacto no Desempenho |
|---|---|---|---|
| Ordem de Bloqueio | Espera Circular | Alta | Baixa |
| Tempo Limite | Detenção e Espera (Indiretamente) | Baixa | Média (Repetições) |
| Bloqueio Otimista | Exclusão Mútua (a longo prazo) | Média | Variável |
| Fluxo Assíncrono | Detenção e Espera | Alta | Baixa |
Etapas de Implementação para Análise Baseada em Diagramas
Para integrar esta abordagem ao seu fluxo de desenvolvimento, siga estas etapas:
- Realize uma Revisão de Design: Antes de escrever código, crie o diagrama de comunicação para os novos recursos. Foque nos caminhos de acesso aos dados.
- Anote o uso de recursos: Marque cada gravação no banco de dados, atualização de cache ou operação de arquivo no diagrama.
- Execute um algoritmo de detecção de ciclos: Se estiver usando ferramentas automatizadas, aplique algoritmos de grafos para detectar ciclos no grafo de dependência derivado do diagrama.
- Refatore para independência: Se um ciclo for encontrado, refatore o código para quebrar a dependência. Isso pode envolver a introdução de um serviço mediador ou a alteração do modelo de dados.
- Valide com testes de carga: Simule alta concorrência para garantir que os padrões de deadlock não se manifestem sob estresse.
Monitoramento e Observabilidade 🧪
Mesmo com um projeto cuidadoso, as condições em tempo de execução podem mudar. As ferramentas de monitoramento devem ser configuradas para detectar sinais de deadlock. Métricas-chave incluem:
- Quantidade de threads:Um aumento repentino em threads bloqueadas pode indicar contenção de recursos.
- Tempo de espera por bloqueio: Se o tempo médio para adquirir um bloqueio aumentar significativamente, a contenção está crescendo.
- Retrocessões de transação: Uma alta taxa de retrocessões devido a timeout ou conflito sugere que as estratégias de bloqueio são muito agressivas.
- Logs de detecção de deadlock: Algumas engines de banco de dados e sistemas operacionais registram eventos de deadlock. Esses logs devem ser integrados ao sistema central de registro.
Estudo de caso: Fluxo de interação entre serviços
Considere um backend genérico de comércio eletrônico que gerencia pedidos e estoque. O serviço A gerencia pedidos e o serviço B gerencia estoque.
Cenário: O serviço A cria um pedido e bloqueia o ID do pedido. Em seguida, chama o serviço B para reservar o estoque. O serviço B bloqueia o ID do estoque. Para atualizar o status do pedido, o serviço B precisa enviar um callback ao serviço A, o que exige bloquear novamente o ID do pedido.
O deadlock: Se o serviço A mantém o ID do pedido e espera que o serviço B libere o ID do estoque, mas o serviço B não pode concluir sem que o serviço A libere o ID do pedido (via o callback), ocorre um deadlock. Este é um cenário de bloqueio aninhado.
A solução: Usando um diagrama de comunicação, esse ciclo é visível. A solução envolve quebrar a dependência. O serviço B deveria atualizar o estoque de forma assíncrona ou usar um ID de transação separado que não exija rebloquear o ID do pedido mantido pelo serviço A. O diagrama então mostraria um fluxo unidirecional de A para B, sem caminho de retorno que exija o bloqueio original.
Considerações sobre bloqueio distribuído
Em ambientes distribuídos, os bloqueios são frequentemente gerenciados por serviços externos, em vez da própria aplicação. Isso introduz latência de rede e o risco de falhas parciais. Os diagramas de comunicação devem considerar o link de rede como um ponto potencial de falha. Se o link entre o serviço A e o Gerenciador de Bloqueios falhar, o serviço A pode achar que detém o bloqueio enquanto outro serviço o detém.
Para resolver isso, o diagrama deve incluir um nó chamado “Gerenciador de Bloqueios”. As interações com esse nó devem ser idempotentes e com limite de tempo. O design deve garantir que, se um serviço falhar, o bloqueio seja liberado automaticamente após o tempo de aluguel expirar. Isso evita que a condição “Segurar e Esperar” persista indefinidamente.
Testes para Resiliência
Os diagramas de design são teóricos. Testes no mundo real são necessários para validar a resiliência. Isso inclui:
- Engenharia de Caos: Introduza intencionalmente atrasos ou falhas nas ligações de rede mostradas no diagrama para verificar se o sistema se recupera ou entra em deadlock.
- Testes de Estresse: Execute solicitações concorrentes que correspondam aos padrões identificados no diagrama para verificar se a ordem de bloqueio funciona sob carga.
- Análise Estática: Use ferramentas para analisar a base de código quanto a possíveis violações de ordem de bloqueio que correspondam à lógica do diagrama.
Conclusão
Evitar deadlocks não é meramente um exercício de codificação; é um desafio de design de sistema. Ao utilizar diagramas de comunicação, as equipes podem visualizar a complexa rede de dependências de recursos que levam a congelamentos do sistema. Essa abordagem transfere o foco da depuração reativa para a prevenção proativa. Compreender as quatro condições de um deadlock, mapear os caminhos de aquisição de recursos e impor ordens estritas ou padrões assíncronos são etapas essenciais para construir uma infraestrutura de backend resiliente. Embora nenhum sistema seja imune a problemas de concorrência, uma abordagem visual estruturada reduz significativamente o risco e a complexidade da gestão de recursos compartilhados. A aplicação consistente desses princípios garante que os serviços permaneçam responsivos e os dados permaneçam consistentes, mesmo sob alta carga e condições de falha.