











आधुनिक सूचना वास्तुकला में, डेटा अखंडता विश्वसनीय सिस्टम व्यवहार की नींव है। जब डेटा प्रोसेसिंग पर्यावरण में प्रवेश करता है, तो उसमें संचालन को बाधित करने, सुरक्षा को खतरे में डालने या निर्यात आउटपुट को दूषित करने के संभावित जोखिम होते हैं। सिस्टम इनपुट की पुष्टि केवल सुरक्षा जांच नहीं है; यह सिस्टम के डिजाइन में एक मूलभूत तार्किक आवश्यकता है। डेटा फ्लो डायग्राम (DFD) के भीतर फ्लो लॉजिक का उपयोग करके, इंजीनियर यह निर्धारित कर सकते हैं कि पुष्टि कहाँ होती है, त्रुटियों का निपटारा कैसे किया जाता है, और डेटा आर्किटेक्चर के माध्यम से कैसे संक्रमित होता है। इस दृष्टिकोण से यह सुनिश्चित किया जाता है कि सिस्टम में प्रवेश करने वाली प्रत्येक जानकारी व्यवसाय तर्क को प्रभावित करने से पहले आवश्यक मानदंड पूरे करती है।
इस लेख में फ्लो लॉजिक के माध्यम से इनपुट पुष्टि के तकनीकी पहलुओं का अध्ययन किया गया है। हम देखेंगे कि पुष्टि नियमों को दृश्य रूप से कैसे प्रस्तुत किया जाता है, डेटा स्वीकृति के लिए निर्णय बिंदुओं को कैसे संरचित किया जाता है, और फ्लो को तोड़े बिना त्रुटि स्थितियों का प्रबंधन कैसे किया जाता है। इन तकनीकी पहलुओं को समझने से वास्तुकारों को ऐसे सिस्टम बनाने में सहायता मिलती है जो गलत डेटा और बाहरी खतरों के खिलाफ लचीले हों।
पुष्टि में डेटा फ्लो डायग्राम को समझना 📊
डेटा फ्लो डायग्राम एक सिस्टम के माध्यम से जानकारी के आवागमन का दृश्य प्रतिनिधित्व प्रदान करते हैं। इनमें प्रक्रियाओं, डेटा स्टोर, बाहरी एजेंसियों और डेटा को दर्शाया जाता है। पुष्टि के संदर्भ में, DFD विश्वास का नक्शा बन जाता है। यह दिखाता है कि डेटा कहाँ प्राप्त किया जाता है, कहाँ जांच की जाती है, और कहाँ संग्रहीत या नष्ट किया जाता है।
एक मानक DFD चार प्राथमिक तत्वों से मिलकर बनता है:
- प्रक्रिया: डेटा का परिवर्तन। यहाँ पुष्टि तर्क आमतौर पर स्थित होता है।
- डेटा स्टोर: एक भंडारण स्थान जहाँ डेटा सहेजा जाता है। डेटा स्टोर में प्रवेश करने से पहले पुष्टि होनी चाहिए।
- बाहरी एजेंसी: सिस्टम सीमा के बाहर डेटा का स्रोत या गंतव्य। इनपुट यहाँ से उत्पन्न होता है।
- डेटा प्रवाह: तत्वों के बीच डेटा के आवागमन। पुष्टि जांच इन मार्गों के साथ होती है।
पुष्टि के लिए डिजाइन करते समय, प्रक्रिया तत्व महत्वपूर्ण हो जाता है। बस बिंदु A से बिंदु B तक डेटा ले जाना पर्याप्त नहीं है। प्रक्रिया को डेटा को नियमों के अनुसार मूल्यांकन करना चाहिए। डायग्राम में, इसे आमतौर पर “पुष्टि” या “साफ करना” लेबल वाली एक विशिष्ट उप-प्रक्रिया द्वारा दर्शाया जाता है। यह दृश्य संकेत विकासकर्ताओं को याद दिलाता है कि यहाँ इनपुट को फ़िल्टर करने के लिए तर्क मौजूद है।
फ्लो संरचनाओं में पुष्टि तर्क को मैप करना 🧠
फ्लो लॉजिक उन ऑपरेशन के क्रम को संदर्भित करता है जो डेटा के मार्ग को निर्धारित करते हैं। पुष्टि में, यह तर्क निर्धारित करता है कि डेटा अगले चरण पर आगे बढ़ेगा या त्रुटि हैंडलर की ओर विचलित किया जाएगा। इसके लागू करने के लिए निर्णय बिंदुओं की स्पष्ट समझ आवश्यक है।
एक डेटा एंट्री फॉर्म के बारे में सोचें जो उपयोगकर्ता की जानकारी एकत्र करता है। फ्लो लॉजिक को निम्नलिखित विशेषताओं की पुष्टि करनी चाहिए:
- उपस्थिति: क्या फ़ील्ड भरा हुआ है?
- प्रकार: क्या इनपुट सही डेटा प्रकार का है (उदाहरण के लिए, पूर्णांक बनाम स्ट्रिंग)?
- सीमा: क्या मान स्वीकार्य सीमा में आता है?
- प्रारूप: क्या स्ट्रिंग आवश्यक पैटर्न के अनुरूप है (उदाहरण के लिए, ईमेल पता)?
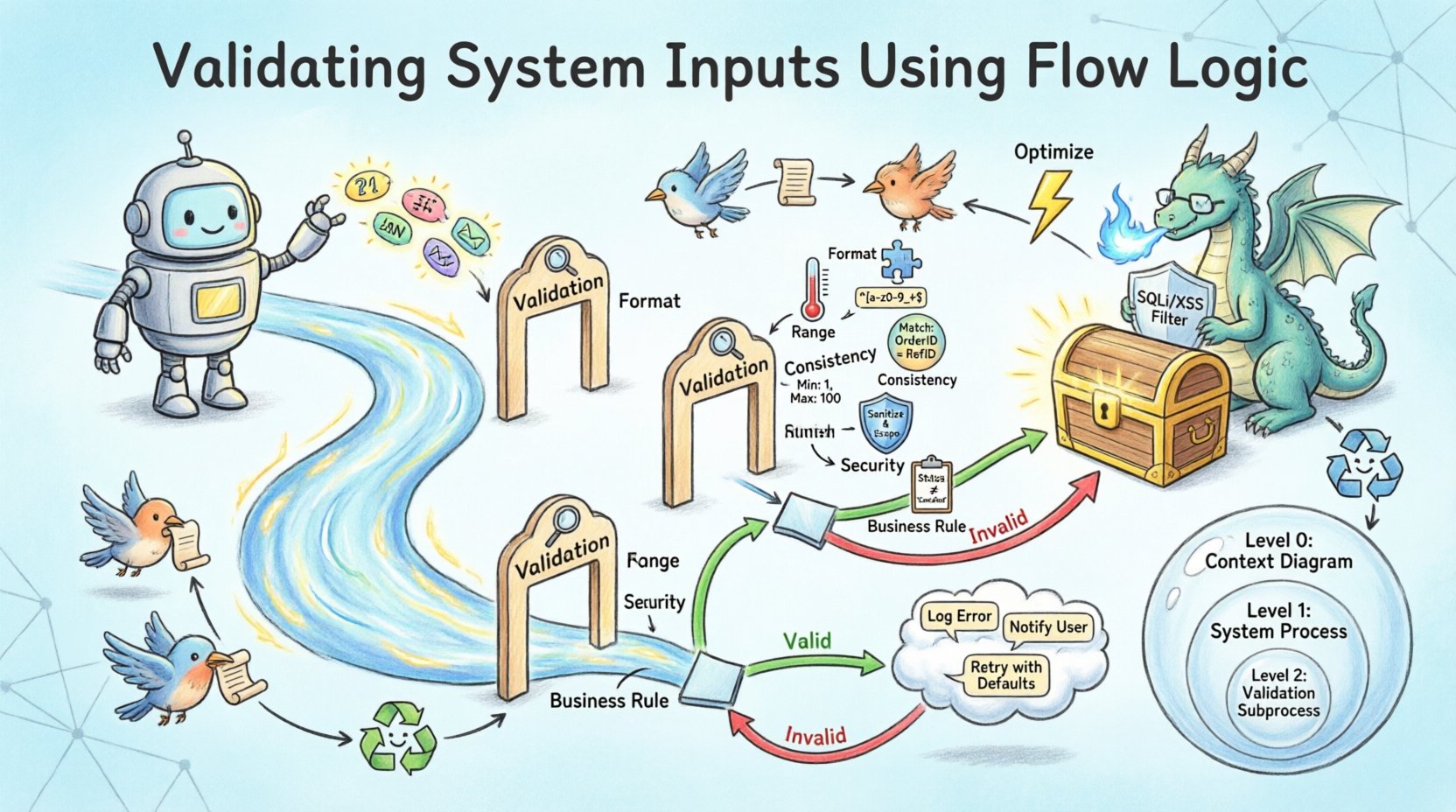
DFD में, इन जांचों से शाखाएं बनती हैं। यदि डेटा सभी जांचों को पार करता है, तो फ्लो मुख्य प्रक्रिया की ओर आगे बढ़ता है। यदि वह विफल होता है, तो फ्लो त्रुटि हैंडलिंग प्रक्रिया की ओर विचलित हो जाता है। यह शाखाएं लचीली आर्किटेक्चर के लिए आवश्यक हैं। इसके बिना, अमान्य डेटा चुपचाप फैल सकता है, जिससे गणना त्रुटियां या सुरक्षा कमजोरियां हो सकती हैं।
निर्णय बिंदु तंत्र
निर्णय बिंदु वे स्थान हैं जहाँ फ्लो विभाजित होता है। फ्लो लॉजिक डायग्राम में, इसे आमतौर पर हीरे के आकार या एक विशिष्ट प्रक्रिया नोड के रूप में दर्शाया जाता है जो दो अलग-अलग डेटा प्रवाह उत्पन्न करता है: एक “वैध” और दूसरा “अवैध” लेबल वाला। “वैध” प्रवाह मुख्य प्रोसेसिंग पाइपलाइन की ओर आगे बढ़ता है। “अवैध” प्रवाह त्रुटि प्रतिक्रिया या सुधार लूप को ट्रिगर करता है।
डायग्राम में क्लाइंट-साइड और सर्वर-साइड पुष्टि के बीच अंतर करना महत्वपूर्ण है। जबकि क्लाइंट-साइड पुष्टि उपयोगकर्ता अनुभव में सुधार करती है, सर्वर-साइड पुष्टि वास्तविक गेटकीपर है। DFD में, सर्वर-साइड जांच डेटा स्टोर तक पहुंचने से पहले अंतिम बाधा होनी चाहिए। इससे सुनिश्चित होता है कि यद्यपि इंटरफेस को बायपास किया जाए, तो भी मुख्य सिस्टम सुरक्षित रहता है।
इनपुट पुष्टि नियमों के प्रकार 🛡️
पुष्टि एक एकल अवधारणा नहीं है। इसमें कई स्तरों की जांच शामिल है। प्रत्येक स्तर का अलग उद्देश्य होता है और फ्लो लॉजिक के भीतर इसके लिए अलग-अलग कार्यान्वयन रणनीतियां आवश्यक होती हैं।
| पुष्टि प्रकार | उद्देश्य | उदाहरण तर्क |
|---|---|---|
| प्रारूप सत्यापन | यह सुनिश्चित करता है कि डेटा अपेक्षित संरचना के अनुरूप हो | फ़ोन नंबरों के लिए रेगेक्स मैचिंग |
| सीमा सत्यापन | यह सुनिश्चित करता है कि डेटा संख्यात्मक सीमा के भीतर हो | उम्र 18 और 120 के बीच होनी चाहिए |
| सांस्कृतिक सत्यापन | यह सुनिश्चित करता है कि डेटा अन्य इनपुट्स के साथ मेल खाता हो | अंतिम तिथि शुरुआती तिथि के बाद होनी चाहिए |
| सुरक्षा सत्यापन | घातक कोड इनजेक्शन को रोकता है | टेक्स्ट फ़ील्ड्स में HTML टैग्स को साफ़ करें |
| व्यावसायिक नियम सत्यापन | यह सुनिश्चित करता है कि डेटा संचालन सीमाओं के अनुरूप हो | छूट 50% से अधिक नहीं हो सकती |
इन नियमों को फ्लो तर्क में एकीकृत करने के लिए सावधानीपूर्वक क्रमबद्धता की आवश्यकता होती है। सुरक्षा सत्यापन को सामान्यतः प्रक्रिया के शुरुआती चरण में किया जाना चाहिए ताकि घातक पैकेट्स के महंगे प्रोसेसिंग से बचा जा सके। प्रारूप सत्यापन आमतौर पर पहला चरण होता है, ताकि तार्किक तुलना करने से पहले डेटा प्रकार सही हों। व्यावसायिक नियम सत्यापन अक्सर अंत में होता है, क्योंकि इसमें पहले से सामान्यीकृत डेटा पर निर्भरता हो सकती है।
त्रुटि फ्लो और फीडबैक लूप का प्रबंधन 🔄
एक मजबूत प्रणाली केवल अमान्य डेटा को अस्वीकार नहीं करती है; यह अस्वीकृति को बिना किसी दुर्घटना के प्रबंधित करती है। यहीं फ्लो तर्क की “अमान्य” शाखा का महत्व होता है। त्रुटि फ्लो को एक तंत्र की ओर ले जाना चाहिए जो उपयोगकर्ता या सिस्टम प्रबंधक को समस्या के बारे में सूचित करे बिना संवेदनशील आ inter विवरणों को उजागर न करे।
DFD में, त्रुटि प्रबंधन प्रक्रिया में शामिल होना चाहिए:
- लॉगिंग:त्रुटि विवरण को डीबगिंग के लिए रिकॉर्ड करें। यह फ्लो एक ऑडिट लॉग डेटा स्टोर की ओर जाता है।
- सूचना:उपयोगकर्ता को चेतावनी दें। यह फ्लो बाहरी एकाधिकार (उपयोगकर्ता इंटरफेस) की ओर जाता है।
- सुधार:डेटा को ठीक करने के लिए एक तंत्र प्रदान करें। इससे एक फीडबैक लूप बनता है जहां डेटा इनपुट चरण में वापस आता है।
फीडबैक लूप उपयोगकर्ता अनुभव के लिए महत्वपूर्ण हैं। यदि उपयोगकर्ता एक अमान्य ईमेल पते के साथ फॉर्म जमा करता है, तो प्रणाली को उसे तुरंत सुधारने की अनुमति देनी चाहिए। फ्लो के शब्दों में, डेटा इनपुट चरण से स्थायी रूप से नहीं जाता है। यह तब तक वैधता तर्क के खिलाफ फिर से मूल्यांकन किया जाता है जब तक कि यह पास नहीं हो जाता या उपयोगकर्ता कार्य को रद्द नहीं कर देता। इससे उपयोगकर्ता के यात्रा में मृत बिंदुओं को रोका जाता है।
त्रुटि लॉगिंग और ऑडिट ट्रेल
सुरक्षा और सुसंगतता के लिए अक्सर आवश्यकता होती है कि वैधता विफलताओं को रिकॉर्ड किया जाए। भले ही इनपुट को अस्वीकार कर दिया गया हो, लेकिन प्रयास स्वयं हमले का संकेत हो सकता है। इसलिए, वैधता प्रक्रिया से ऑडिट लॉग तक एक अलग डेटा फ्लो होनी चाहिए। यह फ्लो समयचिह्न, स्रोत IP पते और विफलता की प्रकृति को कैप्चर करता है। यह मुख्य डेटा फ्लो से स्वतंत्र रूप से काम करता है ताकि लॉगिंग विफलताओं के कारण वैध प्रोसेसिंग ब्लॉक न हो।
प्रक्रिया स्तरों में सत्यापन को एकीकृत करना 🏗️
डेटा फ्लो आरेख अक्सर विभिन्न स्तरों के सामान्यीकरण पर मौजूद होते हैं। स्तर 0 एक उच्च स्तर का अवलोकन प्रदान करता है, जबकि स्तर 1 और स्तर 2 विशिष्ट प्रक्रियाओं को विभाजित करते हैं। सत्यापन तर्क को इन स्तरों के बीच संगत रहना चाहिए।
स्तर 0: प्रणाली सीमा
उच्चतम स्तर पर, सत्यापन को एक गेट के रूप में दर्शाया जाता है। बाहरी एकाधिकारी डेटा भेजता है, और प्रणाली इसे स्वीकार करती है या अस्वीकार करती है। DFD इनपुट और आउटपुट सीमाओं को दर्शाता है। इस चरण पर सत्यापन में असफल होने वाला कोई भी डेटा आंतरिक प्रणाली में कभी नहीं प्रवेश करता है।
स्तर 1: प्रक्रिया विभाजन
प्रणाली के विभाजन के समय, विशिष्ट प्रक्रियाओं को सत्यापन उप-प्रवाह मिलते हैं। उदाहरण के लिए, एक “उपयोगकर्ता पंजीकरण” प्रक्रिया को “पहचान जांच,” “पासवर्ड सत्यापन,” और “संपर्क सत्यापन” में विभाजित किया जा सकता है। इनमें से प्रत्येक उप-प्रक्रिया की अपनी प्रवाह तर्क होती है। इस स्तर पर DFD इन जांचों को करने के लिए आवश्यक आंतरिक डेटा गतिशीलता को दर्शाता है।
स्तर 2: विस्तृत तर्क
सबसे निचले स्तर पर, तर्क पूरी तरह से परिभाषित होता है। यहीं से आरेख से वास्तविक कोड संरचना निकाली जाती है। यहां प्रवाह तर्क संचालन के ठीक क्रम को निर्दिष्ट करता है। उदाहरण के लिए, डेटाबेस में एक उपयोगकर्ता नाम की उपस्थिति की जांच करने के बाद ही इसके वैध प्रारूप की जांच करनी चाहिए, ताकि मौजूदा उपयोगकर्ताओं के बारे में जानकारी लीक न हो।
सत्यापन के दौरान प्रदर्शन को अनुकूलित करना ⚡
सत्यापन तर्क गणनात्मक अतिरिक्त भार जोड़ता है। प्रत्येक जांच को प्रसंस्करण समय की आवश्यकता होती है। उच्च आवृत्ति वाली प्रणालियों में, अत्यधिक सत्यापन एक बाधा बन सकता है। DFD यह निर्धारित करने में मदद करता है कि अनुकूलन की आवश्यकता कहां है।
अनुकूलन के लिए रणनीतियां शामिल हैं:
- प्रारंभिक निकास: यदि एक मूल जांच विफल हो जाती है (उदाहरण के लिए, खाली फ़ील्ड), तुरंत प्रसंस्करण बंद कर दें। जटिल तर्क को न चलाएं।
- कैशिंग: यदि सत्यापन बाहरी डेटा पर निर्भर करता है (उदाहरण के लिए, बैन किए गए खातों की सूची के खिलाफ उपयोगकर्ता आईडी की जांच), उस डेटा को कैश करें ताकि डेटाबेस कॉल कम की जा सकें।
- असिंक्रोनस प्रसंस्करण: गैर-महत्वपूर्ण सत्यापन के लिए, जांच को बैकग्राउंड कतार में स्थानांतरित करें। इससे मुख्य डेटा प्रवाह तेज रहता है।
जब इन अनुकूलनों को DFD में दर्शाया जाता है, तो सिंक्रोनस और एसिंक्रोनस कार्यों के लिए अलग-अलग डेटा प्रवाह का उपयोग करें। यह स्पष्ट करता है कि कौन से सत्यापन उपयोगकर्ता को रोकते हैं और कौन से पृष्ठभूमि में चलते हैं। यह लोड टेस्टिंग के परिदृश्यों में भी मदद करता है, जहां तनाव के तहत प्रणाली के व्यवहार को समझने की आवश्यकता होती है।
प्रवाह तर्क के सुरक्षा प्रभाव 🔒
अमान्य इनपुट ऐसे हमलों के लिए मुख्य मार्ग है जैसे SQL इंजेक्शन, क्रॉस-साइट स्क्रिप्टिंग और बफर ओवरफ्लो। सत्यापन के लिए डिज़ाइन किया गया प्रवाह तर्क एक फायरवॉल के रूप में कार्य करता है। हालांकि, डिज़ाइन सही होना चाहिए।
डिज़ाइन में एक सामान्य चुनौती यह मान्यता है कि इनपुट एक विश्वसनीय स्रोत से आता है। DFD में, प्रत्येक बाहरी एकाधिकारी को संभावित शत्रुतापूर्ण माना जाना चाहिए। सत्यापन प्रक्रिया को डेटाबेस या कमांड लाइन के साथ बातचीत करने से पहले डेटा को साफ करना चाहिए। इस साफ करने की प्रक्रिया आरेख में एक विशिष्ट प्रक्रिया नोड है।
साथ ही, प्रवाह तर्क को जानकारी के लीक होने से रोकना चाहिए। यदि सत्यापन त्रुटि यह बताती है कि एक उपयोगकर्ता नाम मौजूद है, तो एक हमलावर इसका उपयोग खातों की गिनती करने के लिए कर सकता है। त्रुटि प्रवाह को सामान्य संदेश (उदाहरण के लिए, “अमान्य प्रमाणपत्र”) प्रदान करना चाहिए, बजाय विशिष्ट कारणों (उदाहरण के लिए, “उपयोगकर्ता नाम नहीं मिला”) के। इस बातचीत को त्रुटि संभाल प्रक्रिया विवरण में दर्ज किया जाना चाहिए।
सत्यापन प्रवाहों का परीक्षण और पुष्टि ✅
जब प्रवाह तर्क डिज़ाइन कर लिया जाता है, तो उसकी पुष्टि करना आवश्यक होता है। परीक्षण में DFD मार्गों के माध्यम से डेटा भेजना शामिल होता है ताकि तर्क सही रहे। इसे अक्सर व्यक्तिगत सत्यापन नियमों के लिए यूनिट टेस्ट और पूर्ण प्रवाह के लिए इंटीग्रेशन टेस्ट के माध्यम से किया जाता है।
परीक्षण मामलों में शामिल होना चाहिए:
- खुशहाल मार्ग: मान्य डेटा सभी जांचों को पार करता है और डेटा स्टोर तक पहुंचता है।
- किनारे के मामले: सीमाओं पर डेटा (उदाहरण के लिए, न्यूनतम और अधिकतम मान)।
- गलत ढंग से बना डेटा: गलत प्रकार या अप्रत्याशित अक्षरों वाला डेटा।
- गायब डेटा: डेटा जहां आवश्यक फ़ील्ड अनुपस्थित हैं।
यदि DFD सही है, तो परीक्षण परिणाम दृश्यमान प्रवाहों के साथ मेल खाने चाहिए। यदि कोई परीक्षण मामला आरेख द्वारा अनुमानित तरीके से विफल होता है, तो DFD को अपडेट करना आवश्यक है। इस आवर्ती प्रक्रिया सुनिश्चित करती है कि दस्तावेज़ीकरण प्रणाली के व्यवहार का एक सच्चा प्रतिबिंब बना रहे।
संरचित सत्यापन पर निष्कर्ष 📝
प्रवाह तर्क के उपयोग से प्रणाली इनपुट के सत्यापन से सुरक्षा आवश्यकता को वास्तुकला का एक संरचनात्मक घटक बनाया जाता है। डेटा प्रवाह आरेखों में सत्यापन नियमों के नक्शा बनाकर, टीमें यह देख सकती हैं कि डेटा कहां जांचा जाता है, त्रुटियों का निपटारा कैसे किया जाता है, और जानकारी प्रणाली के माध्यम से कैसे आगे बढ़ती है। इस स्पष्टता से अस्पष्टता कम होती है, डिज़ाइनर और डेवलपर्स के बीच संचार में सुधार होता है, और अंततः अधिक स्थिर सॉफ्टवेयर की ओर बढ़ता है। निर्णय बिंदुओं, त्रुटि प्रवाहों और सुरक्षा जांचों के एकीकरण से यह सुनिश्चित होता है कि प्रणाली बाहरी दुनिया के अपरिहार्य शोर से लड़ने में सक्षम रहे।
जैसे-जैसे प्रणालियां जटिलता में बढ़ती हैं, संरचित प्रवाह तर्क पर निर्भरता और अधिक महत्वपूर्ण हो जाती है। यह समय के साथ डेटा अखंडता बनाए रखने के लिए एक नक्शा प्रदान करता है। यहां बताए गए सिद्धांतों का पालन करके, वास्तुकार ऐसे पाइपलाइन बना सकते हैं जो किसी चीज़ पर भरोसा नहीं करते और हर चीज़ की जांच करते हैं, जिससे डेटा प्रणाली की लंबी अवधि तक विश्वसनीयता और टिकाऊपन सुनिश्चित होता है।