











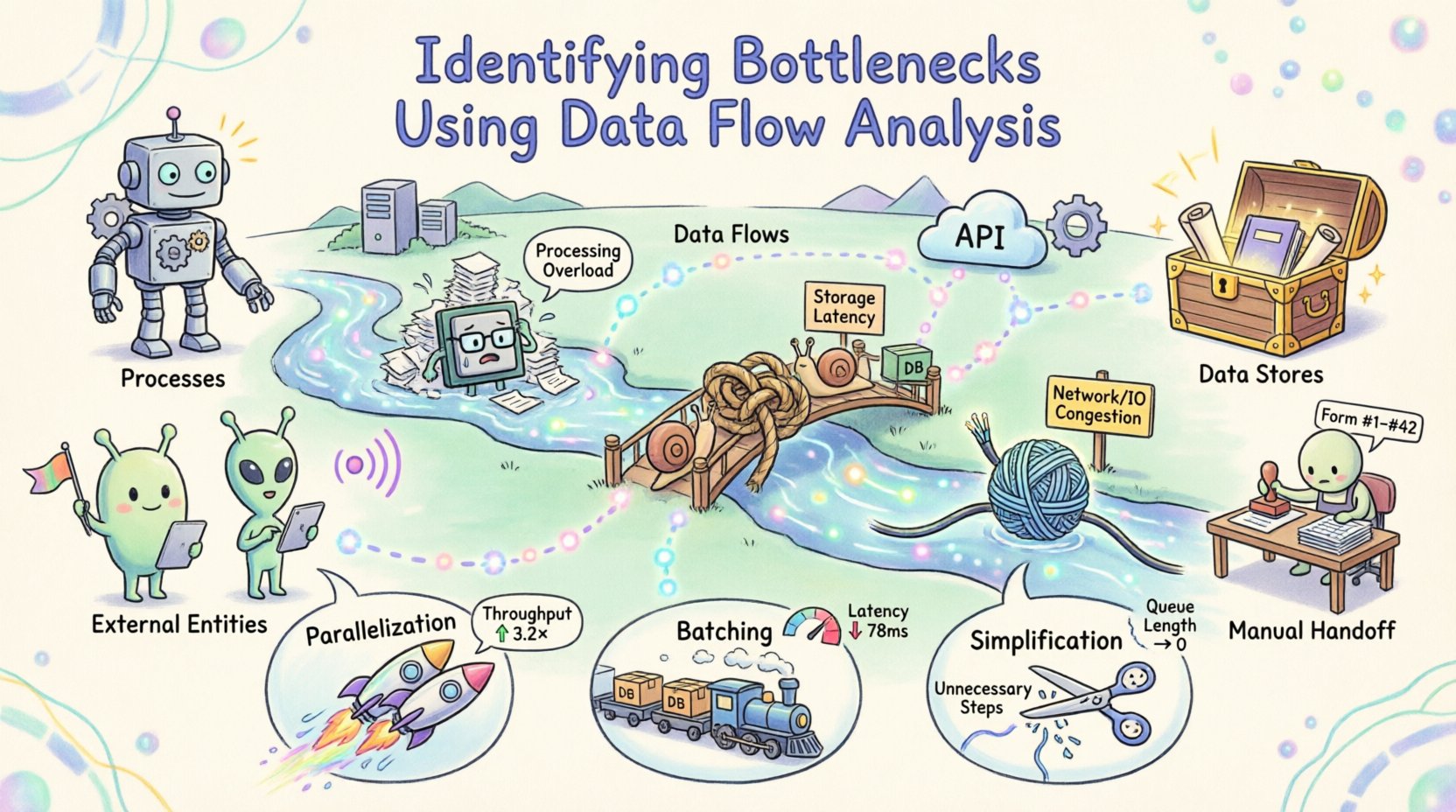
En sistemas complejos, la eficiencia no siempre es evidente hasta que ocurre una desaceleración. Cuando los procesos se detienen, los datos se retrasan o el rendimiento disminuye, el problema subyacente a menudo radica en el movimiento de la información, más que en el almacenamiento o el cálculo en sí. El análisis del flujo de datos proporciona un método estructurado para visualizar cómo la información se mueve a través de un sistema, facilitando la detección de dónde surge la fricción. Al mapear estos flujos, los equipos pueden identificar con precisión los puntos donde se excede la capacidad o donde se acumulan retrasos innecesarios. 🧭
Este enfoque requiere una comprensión clara de la arquitectura del sistema sin depender de herramientas propietarias. El objetivo es establecer un marco lógico que revele ineficiencias. Ya sea gestionando una canalización de software, una línea de producción o un flujo administrativo, los principios permanecen constantes. Identificar estas limitaciones permite intervenciones dirigidas que generan mejoras medibles en velocidad y fiabilidad. ⚙️
Comprendiendo las bases de los diagramas de flujo de datos 🗺️
Antes de localizar un cuello de botella, uno debe entender el mapa. Un diagrama de flujo de datos (DFD) es una representación gráfica del flujo de datos a través de un sistema de información. Se centra en de dónde proviene la data, a dónde va y cómo cambia. A diferencia de los diagramas de flujo que representan la lógica de control, los DFD enfatizan el movimiento y la transformación de los elementos de datos.
Existen cuatro componentes principales dentro de un DFD estándar:
- Procesos:Transformaciones que convierten datos de entrada en datos de salida. A menudo se representan como círculos o rectángulos redondeados.
- Almacenes de datos:Ubicaciones donde se almacena la data para su uso posterior, como bases de datos o archivos.
- Entidades externas:Fuentes o destinos fuera de los límites del sistema, como usuarios o otros sistemas.
- Flujos de datos:Los caminos por los cuales la data se mueve entre los componentes.
Crear un diagrama de alto nivel establece el alcance. Un diagrama de nivel inferior luego profundiza en procesos específicos. Esta jerarquía permite a los analistas examinar el sistema a diferentes niveles de detalle. Si ocurre un retraso a nivel macro, acercarse revela el proceso o transferencia específica que causa la demora. 🔍
La anatomía de un cuello de botella del sistema 🚦
Un cuello de botella es cualquier punto en un sistema donde el flujo de datos está restringido, causando una acumulación o retraso. En el contexto del análisis del flujo de datos, los cuellos de botella se manifiestan de varias formas distintas. Reconocer el tipo de restricción es el primer paso hacia su resolución.
| Tipo de cuello de botella | Descripción | Síntomas típicos |
|---|---|---|
| Procesamiento | El cálculo o la lógica tardan más de lo que puede soportar el flujo de datos entrante. | Las colas se acumulan antes del proceso; los picos de uso de CPU o memoria son altos. |
| Almacenamiento | Leer o escribir datos en una base de datos o sistema de archivos es lento. | La latencia aumenta durante la recuperación de datos; los tiempos de transacción varían enormemente. |
| Red/Entrada/Salida | La velocidad de transferencia entre componentes está limitada por el ancho de banda o la latencia. | Ocurren tiempos de espera; las transferencias grandes de datos se detienen con frecuencia. |
| Humano | Se requiere intervención manual donde debería existir automatización. | Las tareas esperan aprobación; los errores ocurren debido al agotamiento o la complejidad. |
Comprender estas categorías ayuda a priorizar las correcciones. Una limitación de red podría requerir cambios en la infraestructura, mientras que un límite de procesamiento podría necesitar una optimización algorítmica. Sin esta distinción, los esfuerzos podrían desviarse hacia áreas que no limitan el sistema. 🛠️
Metodología para la identificación 🔎
Identificar cuellos de botella no es un evento único, sino una investigación sistemática. Los siguientes pasos describen un enfoque sólido para analizar flujos de datos y localizar restricciones.
1. Mapear el estado actual
Comience documentando la arquitectura existente. No dependa de la memoria ni de suposiciones. Entreviste a los interesados y revise la documentación para capturar el flujo real de información. Cree un diagrama de Nivel 0 que muestre el límite del sistema y las interacciones externas. Luego, cree diagramas de Nivel 1 que descompongan los procesos principales. Asegúrese de que cada flujo de datos tenga una entrada y salida definidas.
2. Definir métricas para la medición
Los mapas visuales son cualitativos. Para encontrar cuellos de botella, necesita datos cuantitativos. Seleccione indicadores clave de desempeño (KPI) para cada proceso y flujo de datos. Las métricas relevantes incluyen:
- Rendimiento: La cantidad de datos procesados por unidad de tiempo.
- Latencia: El tiempo que tarda en viajar un dato desde su origen hasta su destino.
- Utilización: El porcentaje de tiempo que un recurso está activo.
- Longitud de la cola: El número de elementos esperando procesamiento.
Recopilar estos datos durante un período representativo revela patrones. Un proceso podría parecer rápido en promedio, pero mostrar picos significativos durante cargas máximas. Estos picos son a menudo donde se esconde el cuello de botella. 📉
3. Analizar las transiciones de datos
Examine las conexiones entre procesos. Busque flujos de datos que se ramifiquen en múltiples caminos o que se fusionen desde múltiples fuentes. Los puntos de fusión a menudo generan contención. Si tres flujos alimentan a un solo procesador, este debe manejar la carga combinada. Si la capacidad no se escala adecuadamente, se forma una cola de espera.
Asimismo, verifique la existencia de bucles. Los datos que ciclan repetidamente a través de un proceso indican rehacer trabajo o manejo de errores. Los bucles excesivos consumen recursos sin agregar valor. Rastree estos bucles para determinar si son necesarios o el resultado de un mal diseño. 🔄
4. Correlacionar con el uso de recursos
Relacione las métricas de flujo de datos con los recursos del sistema. Un volumen alto de flujo de datos debería correlacionarse con un alto uso de recursos. Si un flujo de datos específico muestra alta latencia pero bajo uso de recursos en otras partes, el problema podría ser específico de esa ruta. Por el contrario, si todos los procesos se ralentizan simultáneamente, el problema podría ser sistémico, como un bloqueo compartido de base de datos o congestión de red.
Utilice herramientas de monitoreo para rastrear el consumo de recursos junto con el flujo. Esta correlación ayuda a distinguir entre un cuello de botella lógico (diseño deficiente) y un cuello de botella físico (límites de hardware). ⚖️
Cuantificar el impacto de las restricciones 📊
Una vez identificado un posible cuello de botella, su impacto debe cuantificarse. Este paso asegura que los recursos se asignen a los problemas más críticos. No todos los retrasos son iguales. Un retraso en la interfaz de usuario podría ser más dañino que un retraso en la generación de informes en segundo plano.
Calcule el costo del retraso. Esto implica estimar el tiempo perdido por transacción y multiplicarlo por el volumen de transacciones. Por ejemplo, si un proceso tarda 100 milisegundos adicionales y maneja 10,000 transacciones por hora, el tiempo total perdido es significativo. Si este retraso afecta la experiencia del usuario, el costo para el negocio es aún mayor.
Considere el efecto en cadena. Un retraso al inicio de una canalización puede propagarse hacia abajo. Si el primer paso se retrasa, todos los pasos posteriores se retrasan. Esto amplifica el impacto total. Identificar la causa raíz evita tratar solo los síntomas. Corregir el primer paso a menudo resuelve automáticamente los retrasos posteriores. 🌊
Estrategias para la optimización 🛠️
Con los cuellos de botella identificados y cuantificados, la atención se centra en la optimización. La estrategia depende de la naturaleza de la restricción. Hay tres palancas principales: paralelización, agrupación y simplificación.
Paralelización
Si un proceso está limitado por cálculos, dividir el trabajo entre múltiples recursos puede aumentar el rendimiento. Esto suele aplicarse a tareas independientes. Si el flujo de datos permite la división, distribuya la carga. Asegúrese de que la sobrecarga de sincronización no anule las ganancias. La paralelización funciona mejor cuando las tareas no dependen de la salida inmediata de otras. 🚀
Agrupación
Si la restricción está relacionada con la entrada/salida o la latencia de red, procesar los datos en lotes puede ser más eficiente que procesar elementos individuales. Esto reduce la sobrecarga de abrir y cerrar conexiones. Sin embargo, la agrupación introduce latencia para elementos individuales. Equilibre la ganancia de rendimiento con el retraso aceptable para el usuario final. 📦
Simplificación
A menudo, la optimización más efectiva es eliminar pasos innecesarios. Revise el flujo de datos en busca de transformaciones redundantes. Si los datos se convierten de un formato a otro y luego de vuelta, puede eliminarse el paso intermedio. Simplifique la lógica para reducir el tiempo de procesamiento. Cada paso añadido a un flujo introduce puntos potenciales de falla y retraso. ✂️
Monitoreo continuo e iteración 🔄
La optimización no es un destino final. Los sistemas evolucionan, y nuevos cuellos de botella surgen cuando cambian los patrones de tráfico. Una vez que se completa el análisis inicial y se implementan mejoras, el ciclo comienza de nuevo. Establezca una rutina para revisar los flujos de datos.
Configure alertas para las métricas definidas anteriormente. Si el rendimiento disminuye o la latencia aumenta bruscamente, desencadene una investigación. Mantenga actualizada la documentación de los diagramas de flujo de datos (DFD). A medida que se realicen cambios en el sistema, actualice los diagramas. Mapas desactualizados generan suposiciones incorrectas y esfuerzos desperdiciados. 📝
Fomente una cultura de mejora continua. Los equipos deben estar capacitados para reportar ineficiencias que encuentren en su trabajo diario. Los usuarios de primera línea a menudo detectan cuellos de botella que las métricas de alto nivel pasan por alto. Su retroalimentación es invaluable para afinar el análisis. 👥
Estudio de caso: Optimización de un flujo de trabajo genérico 🏭
Considere un escenario en el que un sistema de procesamiento de pedidos experimentó retrasos durante las horas pico. El análisis inicial mostró que la etapa de validación de pedidos tardaba demasiado. El DFD reveló que la validación requería tres comprobaciones separadas contra diferentes sistemas externos.
Al analizar el flujo, el equipo se dio cuenta de que estas comprobaciones se realizaban de forma secuencial. Al cambiar el diseño para realizar estas comprobaciones en paralelo, se redujo el tiempo total de validación en un 60%. El diagrama de flujo de datos se actualizó para reflejar esta nueva estructura. La monitorización confirmó que la cola de pedidos se vació más rápido, y el sistema manejó las cargas máximas sin intervención. Este ejemplo demuestra cómo los cambios estructurales en el flujo producen resultados inmediatos. ✅
Mejores prácticas para la eficiencia sostenible 🌱
Para mantener un sistema saludable, siga estas pautas:
- Mantenga los diagramas actualizados:Un mapa desactualizado es peor que ningún mapa.
- Enfóquese en el flujo, no solo en la función:Asegúrese de que los datos se muevan sin problemas, no solo de que las funciones funcionen.
- Mida todo:Si no se mide, no puede mejorarse.
- Revise periódicamente:Programar auditorías periódicas de la arquitectura de datos.
- Documente las suposiciones:Registre por qué ciertos flujos se diseñaron de una manera específica para facilitar la resolución de problemas futuros.
Al tratar el flujo de datos como un activo crítico, las organizaciones pueden asegurarse de que sus sistemas permanezcan ágiles y confiables. El proceso de identificar cuellos de botella no consiste en encontrar fallas, sino en comprender profundamente el sistema. Esta comprensión conduce a resiliencia y rendimiento. 🛡️
Reflexiones finales sobre la integridad del flujo de datos 🧩
La eficiencia en cualquier sistema depende del movimiento fluido de la información. Cuando los datos encuentran resistencia, toda la operación se ralentiza. El análisis de flujo de datos ofrece una lente clara para ver dónde ocurre esta resistencia. Al mapear, medir y modificar el flujo, los equipos pueden eliminar fricciones y mejorar el rendimiento.
Las técnicas descritas aquí proporcionan un marco para la optimización sostenible. Requieren disciplina y atención al detalle, pero la recompensa es un sistema que funciona de manera consistente bajo presión. A medida que crecen los volúmenes de datos, la capacidad de gestionar el flujo se vuelve cada vez más crítica. Dominar esta disciplina asegura longevidad y fiabilidad para la arquitectura. 🏆