











En la arquitectura de información moderna, la integridad de los datos constituye la base del comportamiento confiable del sistema. Cuando los datos entran en un entorno de procesamiento, conllevan riesgos potenciales que pueden interrumpir las operaciones, comprometer la seguridad o corromper las salidas posteriores. Validar las entradas del sistema no es simplemente una verificación de seguridad; es un requisito lógico fundamental integrado en el diseño del sistema. Al utilizar la lógica de flujo dentro de los Diagramas de Flujo de Datos (DFD), los ingenieros pueden trazar exactamente dónde ocurre la validación, cómo se manejan los errores y cómo los datos transitan a través de la arquitectura. Este enfoque garantiza que cada pieza de información que ingresa al sistema cumpla con los criterios necesarios antes de influir en la lógica de negocio.
Este artículo explora la mecánica de la validación de entradas desde la perspectiva de la lógica de flujo. Examinaremos cómo representar visualmente las reglas de validación, cómo estructurar puntos de decisión para la aceptación de datos y cómo gestionar estados de error sin interrumpir el flujo. Comprender estas mecánicas permite a los arquitectos construir sistemas resistentes ante datos malformados y amenazas externas.
Entendiendo los Diagramas de Flujo de Datos en la Validación 📊
Los Diagramas de Flujo de Datos proporcionan una representación visual de cómo la información se mueve a través de un sistema. Muestran procesos, almacenes de datos, entidades externas y los propios datos. En el contexto de la validación, el DFD se convierte en un mapa de confianza. Muestra dónde se reciben los datos, dónde se verifican y dónde se almacenan o descartan.
Un DFD estándar consta de cuatro elementos principales:
- Proceso: Una transformación de datos. Es aquí donde normalmente reside la lógica de validación.
- Almacén de datos: Un repositorio donde se guardan los datos. La validación debe ocurrir antes de que los datos entren en un almacén.
- Entidad externa: Una fuente o destino de datos fuera de los límites del sistema. Las entradas provienen de aquí.
- Flujo de datos: El movimiento de datos entre elementos. Las verificaciones de validación ocurren a lo largo de estos caminos.
Al diseñar para la validación, el elemento Proceso se vuelve crítico. No basta con mover simplemente los datos del punto A al punto B. El Proceso debe evaluar los datos contra un conjunto de reglas. En el diagrama, esto a menudo se representa mediante un subproceso específico etiquetado como “Validación” o “Sanitización”. Esta pista visual recuerda a los desarrolladores que existe lógica aquí para filtrar las entradas.
Mapeando la Lógica de Validación a Estructuras de Flujo 🧠
La lógica de flujo se refiere a la secuencia de operaciones que determinan el camino del dato. En la validación, esta lógica dicta si los datos avanzan a la siguiente etapa o se desvían hacia un manejador de errores. Implementar esto requiere una comprensión clara de los puntos de decisión.
Considere un formulario de entrada de datos que recopila información del usuario. La lógica de flujo debe verificar los siguientes atributos:
- Presencia: ¿Está el campo lleno?
- Tipo: ¿Es la entrada del tipo de dato correcto (por ejemplo, entero frente a cadena)?
- Rango: ¿El valor cae dentro de límites aceptables?
- Formato: ¿La cadena coincide con un patrón requerido (por ejemplo, dirección de correo electrónico)?
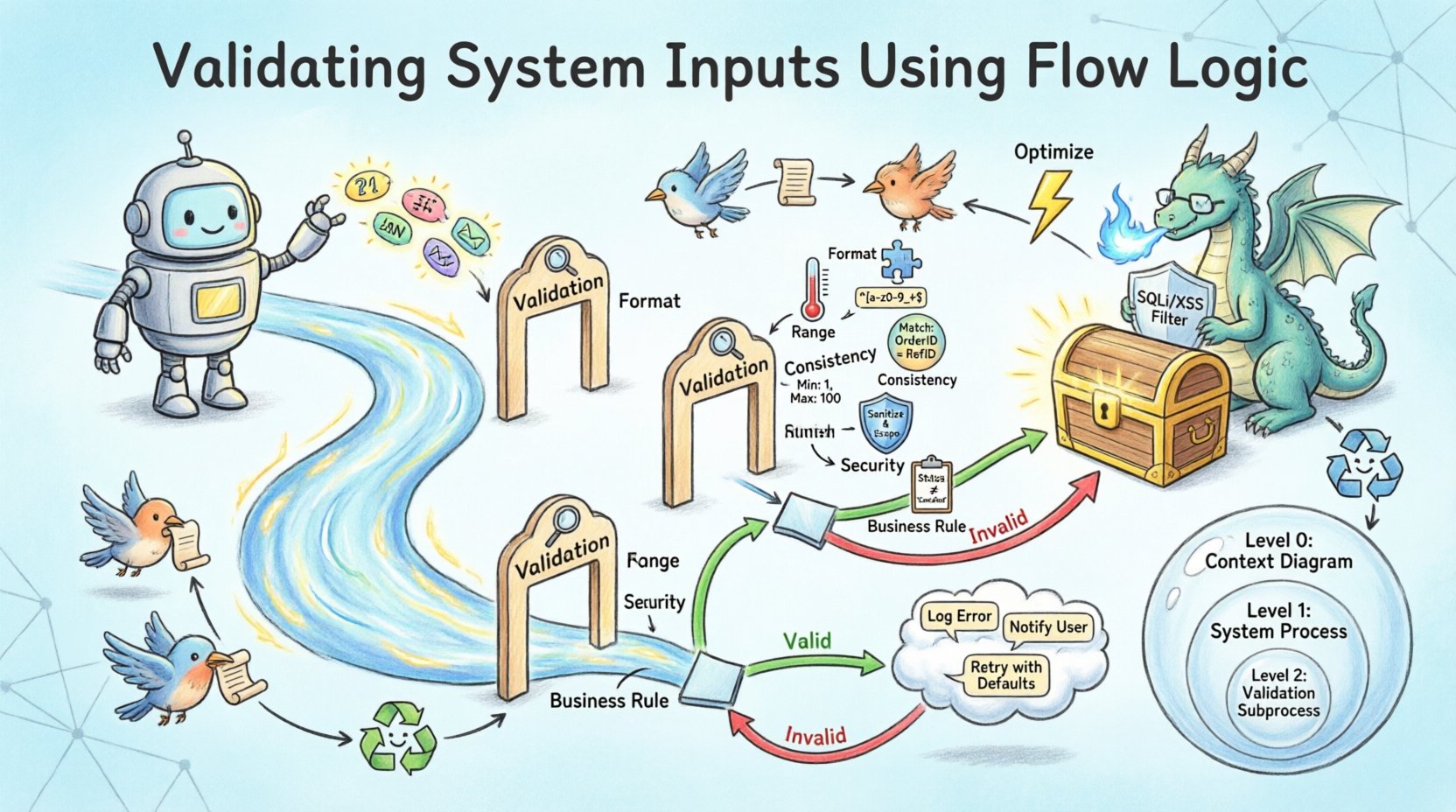
En un DFD, estas verificaciones crean ramificaciones. Si los datos superan todas las verificaciones, el flujo avanza hacia el proceso principal. Si fallan, el flujo se desvía hacia un proceso de manejo de errores. Esta ramificación es esencial para una arquitectura robusta. Sin ella, los datos inválidos podrían propagarse en silencio, provocando errores de cálculo o vulnerabilidades de seguridad.
El Mecanismo de Punto de Decisión
Los puntos de decisión son donde el flujo se divide. En los diagramas de lógica de flujo, esto a menudo se visualiza como una forma de diamante o un nodo de proceso específico que genera dos flujos de datos distintos: uno etiquetado como “Válido” y otro etiquetado como “Inválido”. El flujo “Válido” continúa hacia la línea principal de procesamiento. El flujo “Inválido” desencadena una respuesta de error o un bucle de corrección.
Es importante distinguir entre la validación del lado del cliente y la validación del lado del servidor en el diagrama. Aunque la validación del lado del cliente mejora la experiencia del usuario, la validación del lado del servidor es el verdadero guardián. En el DFD, la verificación del lado del servidor debe ser la barrera final antes de que los datos alcancen el almacén de datos. Esto garantiza que incluso si la interfaz se salta, el sistema central permanezca protegido.
Tipos de Reglas de Validación de Entradas 🛡️
La validación no es un concepto monolítico. Abarca varias capas de escrutinio. Cada capa cumple una función diferente y requiere estrategias de implementación distintas dentro de la lógica de flujo.
| Tipo de Validación | Propósito | Lógica de ejemplo |
|---|---|---|
| Validación de formato | Asegura que los datos coincidan con la estructura esperada | Coincidencia de expresiones regulares para números de teléfono |
| Validación de rango | Asegura que los datos estén dentro de los límites numéricos | La edad debe estar entre 18 y 120 |
| Validación de consistencia | Asegura que los datos se alineen con otras entradas | La fecha final debe ser posterior a la fecha inicial |
| Validación de seguridad | Evita la inyección de código malicioso | Limpia las etiquetas HTML en los campos de texto |
| Validación de reglas de negocio | Asegura que los datos se ajusten a las restricciones operativas | El descuento no puede superar el 50% |
Integrar estas reglas en la lógica de flujo requiere una secuenciación cuidadosa. La validación de seguridad generalmente debe ocurrir al principio del proceso para evitar el procesamiento costoso de cargas maliciosas. La validación de formato suele ser el primer paso para asegurar que los tipos de datos sean correctos antes de realizar comparaciones lógicas. La validación de reglas de negocio suele ocurrir al final, ya que puede depender de datos que ya han sido normalizados.
Manejo de flujos de error y bucles de retroalimentación 🔄
Un sistema robusto no solo rechaza datos inválidos; también gestiona el rechazo de forma elegante. Es aquí donde entra en juego la rama «Inválida» de la lógica de flujo. El flujo de error debe conducir a un mecanismo que informe al usuario o al administrador del sistema sobre el problema sin exponer detalles internos sensibles.
En el DFD, el proceso de manejo de errores debe incluir:
- Registro:Registra los detalles del error para depuración. Este flujo va a un almacén de datos de registro de auditoría.
- Notificación:Notifica al usuario. Este flujo va a la entidad externa (interfaz de usuario).
- Corrección:Proporciona un mecanismo para corregir los datos. Esto crea un bucle de retroalimentación en el que los datos regresan a la etapa de entrada.
Los bucles de retroalimentación son críticos para la usabilidad. Si un usuario envía un formulario con una dirección de correo electrónico inválida, el sistema debería permitirle corregirla de inmediato. En términos de flujo, los datos no abandonan permanentemente la fase de entrada. Se vuelven a evaluar contra la lógica de validación hasta que pasen o el usuario cancele la acción. Esto evita puntos muertos en el recorrido del usuario.
Registro de errores y rastros de auditoría
La seguridad y el cumplimiento a menudo requieren que se registren los fallos de validación. Incluso si la entrada se rechaza, el intento en sí podría ser una señal de un ataque. Por lo tanto, debe existir un flujo de datos separado desde el proceso de validación hasta un registro de auditoría. Este flujo captura marcas de tiempo, direcciones IP de origen y la naturaleza del fallo. Opera de forma independiente con respecto al flujo de datos principal para garantizar que los fallos de registro no bloquen el procesamiento legítimo.
Integración de la validación en los niveles de proceso 🏗️
Los diagramas de flujo de datos a menudo existen en diferentes niveles de abstracción. El nivel 0 proporciona una visión general, mientras que los niveles 1 y 2 desglosan procesos específicos. La lógica de validación debe ser consistente en todos estos niveles.
Nivel 0: Límite del sistema
En el nivel más alto, la validación se representa como una puerta de entrada. La entidad externa envía datos, y el sistema los acepta o rechaza. El diagrama de flujo de datos (DFD) muestra los límites de entrada y salida. Cualquier dato que no pase la validación en esta etapa nunca entra al sistema interno.
Nivel 1: Descomposición de procesos
Al descomponer el sistema, ciertos procesos reciben flujos de validación secundarios. Por ejemplo, un proceso de “Registro de usuario” podría dividirse en “Verificación de identidad”, “Validación de contraseña” y “Verificación de contacto”. Cada uno de estos subprocesos tiene su propia lógica de flujo. El DFD en este nivel muestra el movimiento interno de datos necesario para realizar estas comprobaciones.
Nivel 2: Lógica detallada
En el nivel más bajo, la lógica está completamente definida. Aquí es donde se deriva la estructura real del código a partir del diagrama. La lógica de flujo especifica el orden exacto de las operaciones. Por ejemplo, comprobar si un nombre de usuario existe en la base de datos debe hacerse antes de verificar si tiene un formato válido, para evitar filtrar información sobre usuarios existentes.
Optimización del rendimiento durante la validación ⚡
La lógica de validación añade sobrecarga computacional. Cada comprobación requiere tiempo de procesamiento. En sistemas de alta volumetría, una validación excesiva puede convertirse en un cuello de botella. El DFD ayuda a identificar dónde se necesita optimización.
Las estrategias de optimización incluyen:
- Salida temprana: Si una comprobación básica falla (por ejemplo, campo vacío), detenga el procesamiento inmediatamente. No ejecute lógica compleja.
- Caché: Si la validación depende de datos externos (por ejemplo, verificar un ID de usuario contra una lista de cuentas prohibidas), almacene esos datos en caché para reducir las llamadas a la base de datos.
- Procesamiento asíncrono: Para validaciones no críticas, mueva la comprobación a una cola en segundo plano. Esto mantiene el flujo principal de datos rápido.
Cuando se representan estas optimizaciones en el DFD, utilice flujos de datos distintos para tareas síncronas y asíncronas. Esto aclara qué validaciones bloquean al usuario y cuáles se ejecutan en segundo plano. También ayuda en escenarios de pruebas de carga, donde se necesita comprender el comportamiento del sistema bajo estrés.
Implicaciones de seguridad de la lógica de flujo 🔒
La entrada inválida es un vector principal para ataques como inyección SQL, scripting entre sitios y desbordamientos de búfer. La lógica de flujo diseñada para la validación actúa como un cortafuegos. Sin embargo, el diseño debe ser correcto.
Un desafío común en el diseño es asumir que la entrada proviene de una fuente de confianza. En el DFD, cada entidad externa debe tratarse como potencialmente hostil. El proceso de validación debe limpiar los datos antes de que interactúen con bases de datos o líneas de comandos. Esta limpieza es un nodo de proceso específico en el diagrama.
Además, la lógica de flujo debe prevenir la fuga de información. Si un error de validación revela que un nombre de usuario existe, un atacante puede usar esta información para enumerar cuentas. El flujo de errores debe proporcionar mensajes genéricos (por ejemplo, “Credenciales inválidas”) en lugar de razones específicas (por ejemplo, “Nombre de usuario no encontrado”). Esta sutileza debe capturarse en la descripción del proceso de manejo de errores.
Pruebas y verificación de flujos de validación ✅
Una vez diseñada la lógica de flujo, debe verificarse. Las pruebas implican enviar datos a través de las rutas del DFD para asegurar que la lógica se mantenga. Esto suele hacerse utilizando pruebas unitarias para reglas de validación individuales y pruebas de integración para todo el flujo.
Las pruebas deben cubrir:
- Camino feliz:Los datos válidos superan todas las comprobaciones y llegan al almacén de datos.
- Casos límite:Datos en los límites de los rangos (por ejemplo, valores mínimos y máximos).
- Datos mal formados:Datos con tipos incorrectos o caracteres inesperados.
- Datos faltantes:Datos donde faltan campos obligatorios.
Si el DFD es preciso, los resultados de las pruebas deben alinearse con los flujos visualizados. Si una prueba falla de una manera no prevista por el diagrama, el DFD debe actualizarse. Este proceso iterativo garantiza que la documentación siga siendo una representación fiel del comportamiento del sistema.
Conclusión sobre la validación estructurada 📝
Validar las entradas del sistema utilizando lógica de flujo transforma un requisito de seguridad en un componente estructural de la arquitectura. Al mapear las reglas de validación dentro de los Diagramas de Flujo de Datos, los equipos pueden visualizar dónde se comprueba la información, cómo se manejan los errores y cómo fluye la información a través del sistema. Esta claridad reduce la ambigüedad, mejora la comunicación entre diseñadores y desarrolladores, y conduce finalmente a software más estable. La integración de puntos de decisión, flujos de errores y comprobaciones de seguridad garantiza que el sistema permanezca resistente ante el ruido inevitable del mundo externo.
A medida que los sistemas crecen en complejidad, la dependencia de la lógica de flujo estructurada se vuelve aún más crítica. Proporciona una plantilla para mantener la integridad de los datos con el tiempo. Al adherirse a los principios descritos aquí, los arquitectos pueden construir flujos de trabajo que no confíen en nada y verifiquen todo, asegurando la longevidad y fiabilidad del ecosistema de datos.