











Понимание того, как информация перемещается через систему, критически важно для любого аналитика или разработчика. Диаграмма потоков данных (DFD) предоставляет визуальное представление этого перемещения. Она показывает, откуда берется данные, как они изменяются и куда они приходят. Это руководство описывает процесс создания таких диаграмм с точностью и ясностью.
Зачем визуализировать перемещение данных? 📊
Прежде чем взять в руки ручку или открыть холст, необходимо понять цель диаграммы. DFD — это не блок-схема. Она не показывает поток управления или логические решения. Вместо этого она строго фокусируется на перемещении данных. Это различие имеет решающее значение для обеспечения точности.
Визуализация потока данных предоставляет несколько ощутимых преимуществ:
- Четкость:Сложные системы становятся проще для понимания, когда они разбиваются на визуальные компоненты.
- Коммуникация:Заинтересованные стороны могут обсуждать поведение системы, не имея знаний кода.
- Анализ пробелов:Отсутствующие хранилища данных или избыточные потоки становятся очевидными на этапе чернового рисования.
- Документирование:Диаграмма служит живым документом требований к системе.
Основные компоненты диаграммы потоков данных 🧩
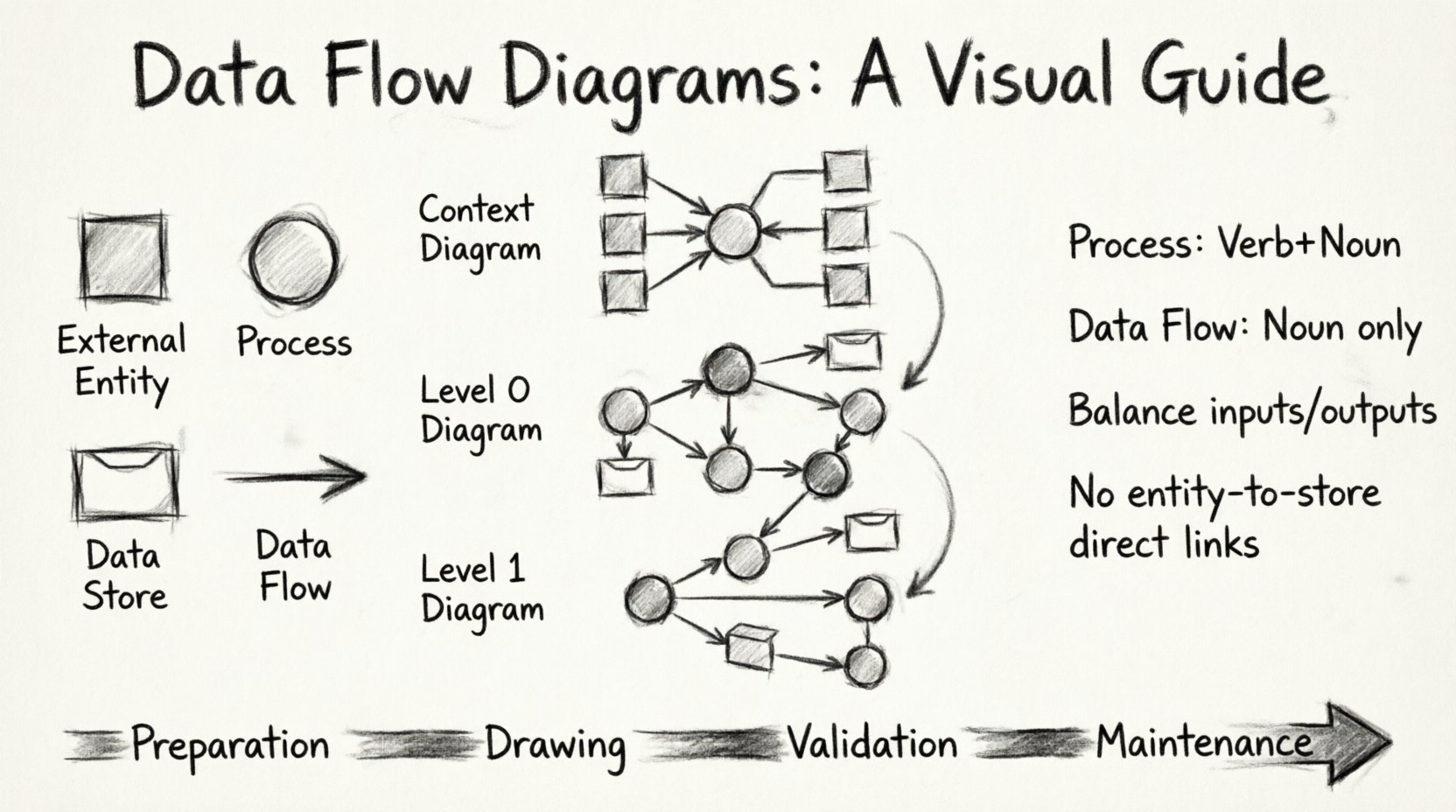
Каждая DFD опирается на четыре стандартных символа. Эти символы составляют лексику диаграммы. Правильное использование их гарантирует, что любой, кто читает диаграмму, поймет архитектуру системы.
1. Внешний элемент (Источник или пункт назначения)
Внешние элементы представляют людей, организации или другие системы, взаимодействующие с процессом. Они находятся за пределами границы системы. Данные поступают от них или уходят к ним. Обычно они изображаются в виде квадратов или прямоугольников.
2. Процесс (Преобразование)
Процесс изменяет данные. Он принимает входные данные, выполняет вычисление или действие и выдает выходные данные. Это сердце диаграммы. Процессы обычно изображаются в виде кругов или закругленных прямоугольников. У каждого процесса должно быть как минимум одно входное и одно выходное значение.
3. Хранилище данных (Репозиторий)
Хранилища данных хранят информацию для последующего использования. В отличие от процессов, они не преобразуют данные; они просто хранят их в безопасности. Примеры включают базы данных, файлы или очереди. Они часто изображаются в виде прямоугольников с открытым концом или параллельных линий.
4. Поток данных (Соединение)
Потоки данных представляют перемещение информации. Стрелки указывают направление. Каждый поток должен быть помечен существительным, описывающим данные, а не глаголом. Например, «Сведения о заказе» — правильно, а «Обработать заказ» — неправильно.
Фаза подготовки 📝
Немедленное приступление к рисованию часто приводит к путанице. Подготовка гарантирует, что диаграмма останется управляемой. Следуйте этим шагам перед созданием первой линии.
Определите границы системы
Определите, что находится внутри системы, а что снаружи. Все, что находится внутри границы, управляется программным обеспечением или процессом. Все, что снаружи, является внешним. Эта граница помогает определить, где разместить внешние элементы.
Соберите источники информации
Просмотрите существующую документацию, проведите интервью с заинтересованными сторонами и изучите текущие рабочие процессы. Вам нужно знать, какие данные поступают в систему и какие результаты ожидаются. Без точных входных данных диаграмма будет спекулятивной.
Шаг 1: Диаграмма контекста 🌍
Диаграмма контекста — это обзор высокого уровня. Она показывает всю систему как один процесс и внешние элементы, с которыми она взаимодействует. Это отправная точка для любой DFD.
- Определите единственный процесс:Нарисуйте круг или пузырь, представляющий всю систему. Дайте ему имя, например, «Система управления заказами».
- Разместите внешние сущности:Нарисуйте квадраты для всех пользователей, отделов или внешних систем, участвующих в процессе. Примеры: «Клиент», «Склад» или «Шлюз оплаты».
- Нарисуйте потоки данных:Соедините сущности с центральным процессом с помощью стрелок. Подпишите каждую стрелку передаваемыми данными. Убедитесь, что стрелки направлены в обе стороны, если данные отправляются и получают.
- Проверьте полноту:Убедитесь, что учтены все внешние взаимодействия. Если сущность отправляет данные, но не получает никаких, проверьте, не отсутствует ли ответ.
Шаг 2: Диаграмма уровня 0 (верхний уровень) 🏗️
После установления контекста разбейте единственный процесс на основные подпроцессы. Это называется диаграммой уровня 0. Она разбивает систему на основные функциональные области.
- Разбейте процесс:Замените единственный процесс контекста на 3–7 основных процессов. Избегайте слишком большого количества, так как это создаст путаницу, и слишком малого — из-за недостатка деталей.
- Определите хранилища данных:Определите, где данные должны храниться на этом уровне. Расположите хранилища данных между процессами, где информация извлекается или сохраняется.
- Соедините потоки:Нарисуйте стрелки между процессами, сущностями и хранилищами. Убедитесь, что каждый процесс имеет вход и выход.
- Сохраняйте баланс:Входы и выходы на этом уровне должны соответствовать диаграмме контекста. Если диаграмма контекста показывает вход «Заказа», диаграмма уровня 0 должна показать, что «Заказ» поступает в один из подпроцессов.
Шаг 3: Разбиение до уровня 1 и далее 🔍
Если процесс на диаграмме уровня 0 сложный, он требует дальнейшего разбиения. Это создает диаграмму уровня 1. Вы можете продолжать этот процесс до тех пор, пока процессы не станут достаточно простыми для прямой реализации.
Правила разбиения
- Один процесс за раз:Сосредоточьтесь на разбиении одного подпроцесса, прежде чем переходить к следующему. Не пытайтесь нарисовать всю систему сразу.
- Сохраняйте потоки:Когда вы разбиваете процесс на более мелкие, данные, поступающие в исходный процесс, должны поступать в новые подпроцессы. Данные, выходящие из процесса, должны поступать из новых подпроцессов.
- Ограничьте детализацию:Прекратите разбиение, когда логика будет достаточно ясной, чтобы разработчик мог написать код без дополнительных пояснений. Обычно три уровня достаточно для большинства систем.
Правила именования и лучшие практики 🏷️
Последовательное именование делает диаграмму читаемой. Несогласованное именование приводит к путанице и ошибкам.
Имена процессов
Имена процессов должны быть глаголами, за которыми следует существительное. Примеры: «Проверить пользователя», «Рассчитать налог» или «Создать отчет». Это указывает на действие. Избегайте неопределенных названий, таких как «Система» или «Данные». Используйте действительные глаголы для описания преобразования.
Имена потоков данных
Имена потоков данных должны быть существительными или существительными фразами. Примеры: «Идентификатор клиента», «Счет», или «Квитанция об оплате». Избегайте глаголов, таких как «Отправить счет», потому что сам поток — это данные, а не действие. Действие — это процесс.
Имена сущностей
Внешние сущности должны быть единственным или множественным числом существительных, представляющих участника. Используйте «Клиент», а не «Данные клиента». Используйте «Склад», а не «Управление складом». Сущность — это участник, а не данные.
Правила и ограничения потоков данных ⚖️
Соблюдение строгих правил предотвращает логические ошибки в проектировании. Эти ограничения обеспечивают, что диаграмма отображает корректную систему.
| Правило | Описание |
|---|---|
| Вход в хранилище данных | Данные могут быть записаны в хранилище только из процесса. Прямые потоки между сущностями и хранилищами обычно не разрешены. |
| Выход из хранилища данных | Данные могут быть прочитаны из хранилища только процессом. Сущности не могут напрямую обращаться к хранилищам. |
| Вход/выход процесса | Каждый процесс должен иметь хотя бы один вход и один выход. Процесс, который поглощает данные, не производя их, — это «черная дыра». Процесс, который создает данные без входа, — это «волшебный источник». Оба случая являются ошибками. |
| Пересечение потоков данных | Потоки данных не должны напрямую пересекать хранилища данных или внешние сущности. Они должны проходить через процесс. |
Проверка и обзор ✅
После того как диаграмма нарисована, она должна быть проверена. Этот этап гарантирует, что модель соответствует реальности.
Проверка баланса
Сравните входы и выходы родительского процесса с входами и выходами его дочерних процессов. Данные, входящие в родительский процесс, должны быть равны данным, входящим в дочерние процессы. Данные, выходящие из родительского процесса, должны быть равны данным, выходящим из дочерних процессов. Если они не совпадают, диаграмма несбалансирована и требует исправления.
Проверка полноты
Проверьте каждый поток данных. У каждого элемента данных есть назначение? У каждого процесса есть источник? Есть ли несвязанные хранилища данных? Полная диаграмма не имеет свободных концов.
Подтверждение заинтересованных сторон
Покажите диаграмму тем, кто использует систему. Попросите их пройти по потоку данных. Согласны ли они с маршрутом? Обнаруживают ли они отсутствующие шаги? Их обратная связь — окончательный тест точности.
Поддержание диаграммы 🔄
DFD — это не разовое задание. Системы развиваются, и требования меняются. Диаграмма должна развиваться вместе с ними.
- Контроль версий: Ведите учет изменений. Обозначайте версии датами или номерами.
- Регулярно обновляйте:Каждый раз, когда добавляется новая функция или изменяется процесс, немедленно обновите диаграмму потоков данных (DFD).
- Архивирование старых версий:Храните старые диаграммы для справки при аудитах или отладке.
Заключение по визуальной точности 🎯
Создание диаграммы потоков данных — это дисциплинированное упражнение в логике и визуализации. Для разложения сложных систем на понятные части требуется терпение. Следуя описанным выше шагам, вы сможете создать диаграмму, которая будет надежным чертежом для разработки и коммуникации.
Цель заключается не просто в проведении линий, а в понимании потоков. Когда потоки данных ясны, ясна и архитектура системы. Эта ясность снижает количество ошибок и улучшает конечный продукт. Сосредоточьтесь на данных, а не на коде, и диаграмма будет эффективно выполнять свою задачу.