











Построение надежных программных систем требует больше, чем просто написание функционального кода. Это требует четкого понимания того, как система ведет себя в различных условиях. Диаграммы конечных автоматов, часто называемые просто диаграммами состояний, служат чертежом для такого поведения. Они отображают различные режимы, в которых может находиться система, и правила переходов между ними. Однако по мере роста сложности систем вероятность возникновения логических ошибок возрастает. Отладка этих проблем требует структурированного подхода, глубокого понимания лежащей в основе логики и систематического исключения переменных.
В этом руководстве описываются основные стратегии выявления и устранения логических ошибок в архитектурах, основанных на состояниях. Понимая анатомию переходов состояний и распространенные ловушки, инженеры могут поддерживать целостность системы, не полагаясь на угадывание.
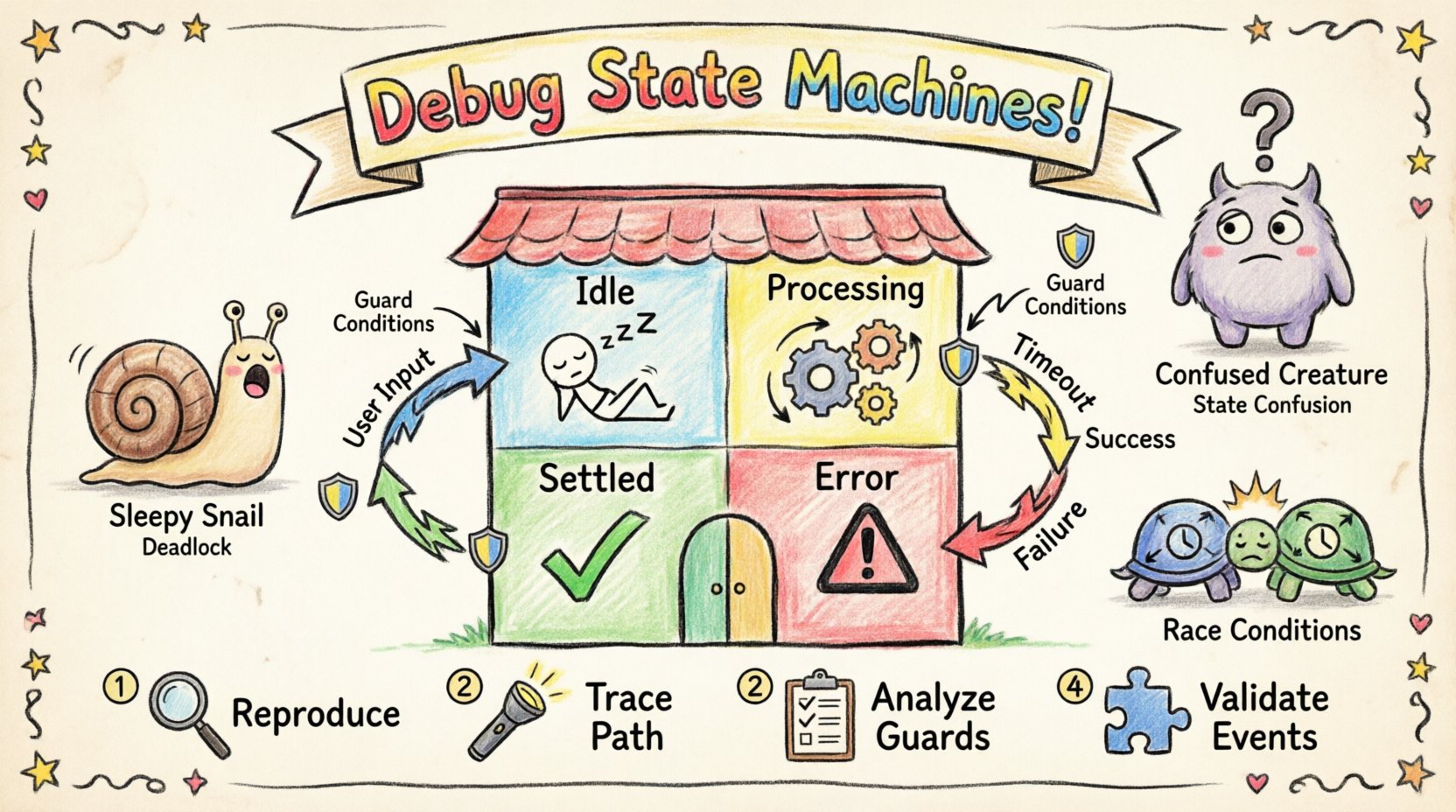
🔍 Понимание анатомии конечного автомата
Прежде чем приступать к устранению неисправностей, необходимо понимать компоненты, управляющие конечным автоматом. Диаграмма состояний — это не просто визуальное представление; это логическое соглашение, определяющее жизненный цикл системы. Каждый элемент выполняет определенную функцию по контролю потока и данных.
- Состояния: Отличительные режимы или состояния, в которых может находиться система. Примеры включаютПриостановлено, Обработка, илиОшибка.
- Переходы: Пути, соединяющие состояния. Переход происходит, когда определенное событие запускает смену одного состояния на другое.
- События: Сигналы или действия, запускающие переходы. Это могут быть внутренние действия или внешние входы.
- Ограничения: Логические условия, проверяемые во время перехода. Переход происходит только в том случае, если условие возвращает значение true.
- Действия: Операции, выполняемые при входе, выходе или во время перехода. К ним могут относиться ведение журнала, обновление данных или запуск внешних служб.
- Начальные/Конечные состояния: Начальная точка и точка завершения жизненного цикла.
При отладке крайне важно проверить, правильно ли взаимодействуют эти компоненты. Логическая ошибка часто возникает из-за расхождения между ожидаемым поведением, определенным на диаграмме, и фактическим поведением в среде выполнения.
🚨 Распространенные логические ошибки и их симптомы
Сложные системы часто страдают от определенных типов логических сбоев. Раннее распознавание симптомов может значительно сэкономить время при отладке. В таблице ниже приведены категории распространенных проблем, их наблюдаемые симптомы и наиболее вероятные причины.
| Тип ошибки | Симптом | Корневая причина |
|---|---|---|
| Ложные переходы | Система переходит в неожиданное состояние без четкого триггера. | Отсутствуют условия-ограничения или перекрывающиеся обработчики событий. |
| Взаимоблокировки | Система останавливается и не реагирует на корректные входные данные. | Нет исходящих переходов из определенного состояния для определенных событий. |
| Недоступные состояния | Определенные состояния никогда не входят в процесс нормальной работы. | Неправильные пути входа или логика, пропускающая определенные состояния. |
| Путаница состояний | Система ведет себя по-разному в одном и том же состоянии в зависимости от истории. | Неудача при сбросе контекста или неправильное управление состояниями истории. |
| Гонки в параллельных процессах | Конфликтующие действия происходят одновременно в параллельных состояниях. | Отсутствие синхронизации между параллельными подсистемами. |
🧪 Пошаговая методология отладки
Устранение проблем с машиной состояний требует дисциплинированного рабочего процесса. Случайные исправления часто приводят к появлению новых ошибок. Следуйте этой систематической методике для изоляции и устранения логических ошибок.
1. Воспроизведите проблему
Прежде чем приступить к исправлению, необходимо надежно воспроизвести ошибку. Если проблема возникает эпизодически, зафиксируйте последовательность событий, приводящих к сбою.
- Определите конкретный ввод или событие, которое вызывает некорректное поведение.
- Запишите текущее состояние системы до наступления события.
- Запишите состояние, в которое переходит система после события.
- Проверьте, возникает ли проблема постоянно или только при определенных условиях (например, при определенных значениях данных).
2. Отследите путь выполнения
Используйте механизмы логирования для отслеживания пути выполнения. Каждый переход должен быть зафиксирован с соответствующим контекстом.
- Логирование входа/выхода:Фиксируйте момент входа и выхода из состояния.
- Логирование переходов:Фиксируйте событие, вызвавшее переход.
- Оценка условий-ограничений:Фиксируйте, прошли ли условия-ограничения или нет, и почему.
- Ведение журнала действий: Ведите журнал выполнения действий и их вывода.
Эти данные создают хронологию событий. Сравните эту хронологию с диаграммой состояний. Ищите расхождения, где код отклоняется от проекта.
3. Проанализируйте условия-ограничения
Условия-ограничения являются частой причиной логических ошибок. Переход может казаться доступным на диаграмме, но скрытое условие может препятствовать его срабатыванию.
- Проверьте все условия-ограничения, связанные с проблемным переходом.
- Убедитесь, что переменные, используемые в условии-ограничении, соответствуют данным, доступным в момент события.
- Проверьте наличие побочных эффектов при оценке условия-ограничения, которые могут неожиданно изменить состояние.
- Убедитесь, что условия-ограничения не слишком строгие, блокируя допустимые переходы.
4. Проверьте обработку событий
События являются катализаторами изменений. Если событие не обрабатывается правильно, система может проигнорировать его или обработать в неправильном состоянии.
- Проверьте, совпадает ли имя события точно между источником и машиной состояний.
- Убедитесь, что событие отправляется в правильный экземпляр машины состояний.
- Убедитесь, что событие не потребляется родительским состоянием, когда его должен обрабатывать дочерний элемент.
- Подтвердите, что очередь событий обрабатывает события в ожидаемом порядке.
🔄 Обработка параллелизма и параллельных состояний
Расширенные машины состояний часто используют параллельные состояния. Это позволяет нескольким независимым машинам состояний одновременно работать внутри составного состояния. Хотя это мощно, это вводит сложность в синхронизации и обмене данными.
1. Точки синхронизации
В средах с параллелизмом переходы должны быть синхронизированы, чтобы избежать гонок. Переход в одном параллельном состоянии может зависеть от завершения перехода в другом.
- Определите четкие барьеры синхронизации, где параллельные состояния должны быть выровнены.
- Используйте флаги или переменные состояния для указания готовности параллельных ветвей.
- Убедитесь, что конечные состояния в параллельных ветвях достигнуты до завершения составного состояния.
2. Целостность совместно используемых данных
Параллельные состояния часто обращаются к совместно используемым ресурсам. Если два состояния одновременно изменяют одни и те же данные, может произойти повреждение.
- Реализуйте механизмы блокировки при доступе к совместно используемым переменным состояния.
- Где возможно, используйте неизменяемые структуры данных, чтобы предотвратить случайное изменение.
- Проведите аудит всех функций действий, чтобы определить, изменяют ли они глобальное или совместно используемое состояние.
🛡️ Методы проверки и валидации
Отладка — это реактивный процесс; проверка — проактивный. Реализация стратегий проверки машины состояний до развертывания снижает нагрузку на устранение неполадок.
1. Статический анализ
Инструменты статического анализа могут сканировать определение диаграммы состояний без выполнения кода. Они могут выявлять структурные проблемы.
- Проверьте наличие недостижимых состояний.
- Определите переходы, которые не могут быть запущены никаким событием.
- Убедитесь, что все состояния имеют допустимые пути выхода.
- Убедитесь, что все события обрабатываются (нет ошибок необработанных событий).
2. Проверка модели
Проверка модели включает математическую проверку того, что конечный автомат удовлетворяет определённым свойствам. Это особенно полезно для систем, критичных к безопасности.
- Определите свойства, такие как «система никогда не переходит в состояние взаимоблокировки».
- Запустите алгоритмы для проверки этих свойств на основе графа переходов состояний.
- Используйте эти инструменты для проверки сложных сценариев параллелизма.
3. Юнит-тестирование для конечных автоматов
Каждое состояние и переход следует тестировать независимо, где это возможно.
- Напишите тесты, которые помещают систему в определённое состояние и запускают определённое событие.
- Убедитесь, что система переходит в правильное следующее состояние.
- Убедитесь, что запускаются ожидаемые действия.
- Тестируйте граничные условия, например, запуск события в состоянии, где он не должен быть разрешён.
📝 Документация для будущего сопровождения
Конечный автомат, который сложно понять, сложно отлаживать. Чёткая документация гарантирует, что будущие инженеры смогут эффективно устранять неполадки, не прибегая к обратному проектированию логики.
- Комментируйте код: Добавьте встроенные комментарии, объясняющие сложные переходы или неочевидные условия-ограничения.
- Поддерживайте диаграммы: Держите визуальные диаграммы состояний синхронизированными с кодом. Устаревшая диаграмма — это риск.
- Документируйте крайние случаи: Зафиксируйте известные ограничения или специфические сценарии, при которых машина ведёт себя иначе.
- Контроль версий: Рассматривайте определения состояний как код. Используйте контроль версий для отслеживания изменений логики с течением времени.
⚙️ Реальный сценарий: Поток обработки платежей
Рассмотрим систему обработки платежей. Конечный автомат управляет жизненным циклом транзакции:Инициировано, Авторизовано, Оплачено, или Ошибка.
Представьте ситуацию, когда транзакция переходит в состояние Оплачено состояние, но база данных указывает, что она по-прежнему находится в состоянии Авторизовано. Это классическая ошибка несогласованности состояния.
- Диагностика: Переход от Авторизовано к Оплачено был инициирован, но логика обновления состояния не смогла зафиксировать изменение в постоянном хранилище.
- Влияние: Пользователь видит успех, но бэкенд ожидает, что средства будут зарезервированы.
- Исправление: Реализуйте обертку транзакции, которая гарантирует, что обновление состояния и фиксация в базе данных происходят атомарно.
- Предотвращение: Добавьте задание синхронизации, которое периодически проверяет состояние конечного автомата по сравнению с состоянием базы данных.
🔧 Расширенные инструменты устранения неполадок
Хотя ручное отслеживание эффективно, определенные инструменты могут ускорить процесс отладки.
- Интерактивные визуализаторы состояний: Инструменты, позволяющие визуально просматривать состояния в реальном времени.
- Агрегаторы журналов: Централизованные системы ведения журналов, позволяющие фильтровать по идентификатору состояния или типу события.
- Протоколы отладки: Интерфейсы, которые позволяют внешним системам запрашивать текущее состояние машины без её перезагрузки.
- Среды моделирования: Сандбоксы, где можно повторить последовательность событий для безопасного воспроизведения ошибок.
🧠 Нагрузка памяти и сложность состояний
По мере увеличения количества состояний нагрузка на память, необходимая для поддержания логики, растёт экспоненциально. Это известно как проблема взрыва состояний.
- Модуляризуйте: Разбейте большие машины состояний на более мелкие, управляемые подмашинки.
- Абстрагируйте: Используйте составные состояния, чтобы скрыть сложность от логики более высокого уровня.
- Ограничьте: Жёстко ограничьте количество одновременных состояний, чтобы снизить накладные расходы на синхронизацию.
- Рефакторинг: Регулярно пересматривайте диаграмму состояний, чтобы выявить избыточные или перекрывающиеся состояния.
🛑 Обработка неожиданных входных данных
Надёжные системы должны обрабатывать входные данные, которые не определены в диаграмме состояний. Это часто называют «состоянием ошибки».
- Переходы по умолчанию: Определите переход по умолчанию для событий, происходящих в неожиданных состояниях.
- Ведение журнала: Записывайте неожиданные события с высоким уровнем серьёзности для оповещения разработчиков.
- Восстановление: Убедитесь, что система может восстановиться из состояния ошибки, а не аварийно завершиться.
- Уведомление: Уведомляйте пользователя или систему мониторинга при возникновении неожиданного события.
📊 Метрики состояния машины состояний
Чтобы поддерживать здоровую систему, отслеживайте конкретные метрики, связанные с машиной состояний.
- Частота переходов: Как часто происходят конкретные переходы. Резкие изменения могут указывать на ошибку.
- Длительность состояния: Как долго система находится в конкретном состоянии. Длительные периоды могут указывать на зависание.
- Уровень ошибок: Процент событий, приводящих к переходам с ошибкой.
- Количество блокировок: Количество раз, когда система переходит в состояние без исходящих переходов.
🚀 Заключение по целостности системы
Поддержание целостности машины состояний — это непрерывный процесс. Требуется бдительность, четкая документация и глубокое понимание логики потока. Следуя методологиям, описанным выше, инженеры могут эффективно отлаживать логические ошибки и обеспечивать предсказуемое поведение сложных систем.
Помните, что цель заключается не только в устранении текущей ошибки, но и в повышении общей устойчивости архитектуры. Хорошо спроектированная машина состояний самодокументирована и устойчива к изменениям. Вложите время в этап проектирования, чтобы снизить стоимость устранения неполадок в будущем.
Последовательно применяйте эти принципы. Регулярно проверяйте свои диаграммы. Тщательно тестируйте переходы. При дисциплине вы сможете управлять сложностью и обеспечивать стабильную, надежную работу программного обеспечения.