











Распределенные системы в значительной степени зависят от перемещения информации между изолированными компонентами. При создании микросервисов архитектура — это не просто разделение кода; это координация того, как данные перемещаются по сети. Понимание логики потоков данных необходимо для поддержания целостности системы, производительности и надежности. Без четкой карты того, откуда берутся данные, где они трансформируются и где закрепляются, системы становятся непрозрачными и трудными для диагностики.
В этом руководстве рассматривается методология картирования этих потоков. Мы рассмотрим структурные компоненты, логику перемещения данных и шаблоны, управляющие взаимодействием между сервисами. Цель — создать прозрачную архитектуру, в которой каждая транзакция учитывается.
Понимание архитектуры 🏗️
Архитектура микросервисов разбивает монолитное приложение на более мелкие, независимые единицы. Каждая единица отвечает за конкретную бизнес-возможность. Однако эта независимость вводит сложность в управлении состоянием и коммуникации. Данные не существуют в вакууме — они перемещаются.
Когда вы картируете эти сервисы, вы фактически рисуете чертеж нервной системы системы. Вам нужно определить производителей данных и потребителей. Вам необходимо понимать протоколы передачи. Сервисы общаются напрямую через HTTP? Используют ли они очередь сообщений? Доступны ли они к общей базе данных?
Четкость в этой области предотвращает жесткую связь. Если сервис А зависит от сервиса В для работы, эта зависимость должна быть явно отображена на ваших картах. Скрытые зависимости приводят к цепным сбоям. Визуализируя поток, вы можете выявить узкие места до того, как они повлияют на производительность в продакшене.
Ключевые причины для картирования
- Наблюдаемость:Вы не можете отлаживать то, что не видите. Четкая карта помогает отслеживать запросы в распределенной среде.
- Безопасность:Понимание потоков данных позволяет применять шифрование и контроль доступа на правильных границах.
- Производительность:Выявление путей с высокой задержкой помогает оптимизировать сетевые вызовы и запросы к базе данных.
- Соответствие:Требования часто требуют знать, где хранятся чувствительные данные и как они перемещаются.
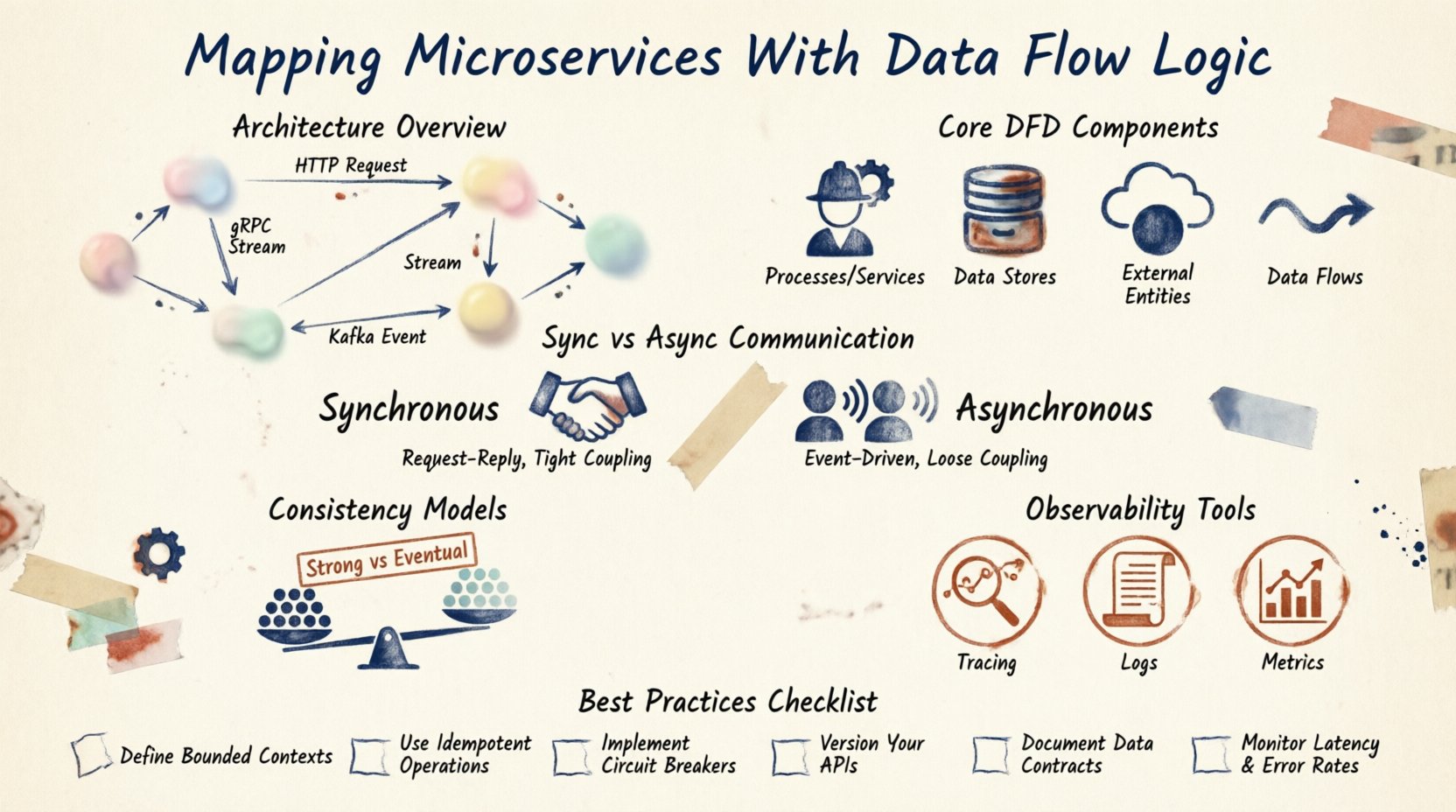
Основные компоненты диаграмм потоков данных 📊
Диаграмма потоков данных (DFD) предоставляет стандартизированный способ представления этих взаимодействий. В контексте микросервисов компоненты немного отличаются от традиционных DFD в инженерии программного обеспечения.
1. Процессы (сервисы)
Это активные элементы. Каждый микросервис представляет собой процесс, преобразующий входные данные в выходные. Например, сервис заказов получает данные о заказе и преобразует их в резервирование товара на складе.
2. Хранилища данных
Данные не всегда остаются в памяти. Они часто сохраняются в базах данных, кэшах или объектном хранилище. В среде микросервисов сервисы обычно имеют собственные хранилища данных. Это обеспечивает слабую связь. Если изменяется схема базы данных, адаптироваться должны только сервисы-владельцы.
3. Внешние сущности
Это сущности за пределами системы. Это может быть сторонний платежный шлюз, мобильное приложение или пользователь. Они инициируют запросы или получают уведомления. Картирование этих границ критически важно для проектирования шлюза API.
4. Потоки данных
Это стрелки, соединяющие компоненты. Они представляют перемещение информации. Каждый поток должен иметь метку, описывающую передаваемые данные. Это JSON-пакет? Бинарный файл? Уведомление о событии?
Пошаговый процесс картирования 🗺️
Создание карты — это систематическое занятие. Требуется постепенно разбивать систему на слои. Вот логический подход к построению этих диаграмм.
- Определите границы: Определите, что находится внутри системы, а что — снаружи. Это задает границы для вашей диаграммы.
- Перечислите сервисы: Перечислите каждый микросервис, участвующий в конкретном бизнес-процессе, который вы анализируете.
- Определите точки входа данных: Где данные поступают в систему? Это конечная точка API? Планируемая задача? Потребитель очереди сообщений?
- Пройдите по пути: Следуйте за одним фрагментом данных от входа до выхода. Запишите каждый сервис, с которым он взаимодействует.
- Определите место хранения: Отметьте, где данные читаются или записываются на каждом этапе.
- Проверьте логику: Обсудите с командой разработчиков схему, чтобы убедиться, что она соответствует фактической реализации.
Паттерны коммуникации 📡
Как сервисы общаются друг с другом, определяет логику потока. Существуют два основных режима: синхронный и асинхронный.
Синхронная коммуникация
Сервис A вызывает Сервис B и ждет ответа. Это часто реализуется через REST или gRPC. Это обеспечивает немедленную обратную связь, но создает тесную связь. Если Сервис B медленный, Сервис A зависает.
Асинхронная коммуникация
Сервис A отправляет сообщение и продолжает работу. Сервис B получает его, когда готов. Используются брокеры сообщений или потоки событий. Это повышает отказоустойчивость, но усложняет отслеживание состояния.
| Аспект | Синхронный | Асинхронный |
|---|---|---|
| Задержка | Высокая (блокирующая) | Низкая (неблокирующая) |
| Связность | Тесная | Разреженная |
| Сложность | Просто отследить | Требует источника событий |
| Обработка сбоев | Повторить немедленно | Очереди сообщений с ошибками |
Модели согласованности 🤝
В распределенной системе согласованность данных является важным вопросом. Вы не можете полагаться на одну транзакцию через несколько баз данных. Вам необходимо выбрать модель согласованности.
Сильная согласованность
Каждое чтение получает самую последнюю запись. Это сложно достичь между микросервисами без блокировки. Часто требуется использование механизмов распределённой блокировки.
Потенциальная согласованность
Данные станут согласованными через некоторое время. Обновления распространяются асинхронно. Это стандарт для большинства микросервисов. Это обеспечивает высокую доступность, но требует от приложения обработки временных несоответствий данных.
Наблюдаемость и трассировка 🔍
Как только карта нарисована, вам понадобятся инструменты для её мониторинга. Распределённая трассировка позволяет отслеживать идентификатор запроса через каждый сервис. Это критически важно для отладки.
Логи должны быть связаны. Если запрос завершается с ошибкой, логи от шлюза, сервиса заказов и сервиса оплаты должны быть связаны между собой. Эта связь — цифровая копия вашей диаграммы потока данных.
Метрики также являются частью потока. Следует отслеживать объём сообщений, задержку вызовов и уровень ошибок. Эти метрики подтверждают здоровье путей передачи данных, которые вы спроектировали.
Лучшие практики обслуживания 🛠️
Диаграмма полезна только в том случае, если она остаётся точной. Системы развиваются, и карта должна развиваться вместе с ними.
- Автоматизация генерации: По возможности генерируйте диаграммы из кода или инфраструктуры как кода. Это снижает количество ошибок, вызванных вручную.
- Контроль версий: Храните свои диаграммы в том же репозитории, что и ваш код. Проверяйте их во время запросов на слияние.
- Регулярные аудиты: Планируйте ежеквартальные проверки, чтобы убедиться, что карта соответствует работающей системе.
- Документирование протоколов: Чётко определите форматы данных. Используйте схемы для обеспечения структуры между сервисами.
Проблемы в распределённых потоках ⚠️
Создание карт этих систем сопряжено с трудностями. Сети выходят из строя. Сервисы перезапускаются. Данные теряются.
Задержка в сети: Физическое расстояние между сервисами может повлиять на производительность. Вам необходимо учитывать это в логике времени.
Фрагментация данных: Данные распределены по многим хранилищам. Восстановление полной картины сущности требует объединения данных из разных источников. Это добавляет сложность запросам.
Оркестрация против хореографии: Вам нужно решить, кто контролирует поток. Оркестрация использует центральный координатор. Хореография полагается на события. У обоих подходов есть компромиссы в плане прозрачности и контроля.
Защита проекта от будущих изменений 🔮
Технологии меняются. Протоколы развиваются. Ваша карта должна быть достаточно абстрактной, чтобы выдержать эти изменения.
Сосредоточьтесь на бизнес-логике, а не на деталях реализации. Описывайте, что означают данные, а не только как они кодируются. Эта абстракция позволяет менять базовые технологии, не переписывая всю архитектуру.
Учитывайте масштабируемость. Может ли поток выдержать десятикратную нагрузку? Показывает ли карта, где могут возникнуть узкие места? Проектируйте с учётом роста с самого начала.
Заключительные мысли о логике данных
Создание карт микросервисов с логикой потока данных — это фундаментальный навык для архитекторов. Это переводит разговор с абстрактного кода на конкретное движение. Визуализируя поток, команды могут принимать более обоснованные решения по устойчивости, безопасности и производительности.
Требуется дисциплина, чтобы поддерживать карты в актуальном состоянии. Требуется сотрудничество, чтобы все понимали пути. Но результат — система, которую легче создавать, легче отлаживать и легче масштабировать. Данные движутся чётко, а система остаётся стабильной под нагрузкой.
Вложите время в эти диаграммы. Они служат документацией для жизненно важного потока вашей системы. Когда на рабочем сервере гаснет свет, именно эти карты будут руководить восстановлением.