











किसी भी विश्लेषक या विकासकर्ता के लिए यह समझना महत्वपूर्ण है कि जानकारी किस तरह सिस्टम के माध्यम से आगे बढ़ती है। डेटा फ्लो डायग्राम (DFD) इस गति का दृश्य प्रतिनिधित्व प्रदान करता है। यह डेटा कहाँ से आता है, वह कैसे बदलता है, और अंततः वह कहाँ जाता है, इसका नक्शा बनाता है। इस गाइड में इन डायग्रामों को सटीकता और स्पष्टता के साथ बनाने की प्रक्रिया को चरणबद्ध तरीके से बताया गया है।
डेटा गति को दृश्य रूप में क्यों दिखाना चाहिए? 📊
पेन या कैनवास उठाने से पहले, डायग्राम के उद्देश्य को समझना आवश्यक है। DFD एक फ्लोचार्ट नहीं है। यह नियंत्रण प्रवाह या तार्किक निर्णयों को नहीं दिखाता है। इसके बजाय, यह डेटा की गति पर ही ध्यान केंद्रित करता है। इस अंतर को बनाए रखना सटीकता बनाए रखने के लिए बहुत महत्वपूर्ण है।
डेटा प्रवाह को दृश्य रूप में दिखाने से कई वास्तविक लाभ मिलते हैं:
- स्पष्टता:जटिल प्रणालियाँ दृश्य घटकों में बाँटने पर समझने में आसान हो जाती हैं।
- संचार:हितधारक बिना कोड के ज्ञान के बिना प्रणाली के व्यवहार पर चर्चा कर सकते हैं।
- अंतर विश्लेषण:गायब डेटा स्टोर या अनावश्यक प्रवाह ड्राफ्टिंग प्रक्रिया के दौरान स्पष्ट हो जाते हैं।
- दस्तावेजीकरण:डायग्राम प्रणाली की आवश्यकताओं का एक जीवंत रिकॉर्ड के रूप में कार्य करता है।
डेटा फ्लो डायग्राम के मुख्य घटक 🧩
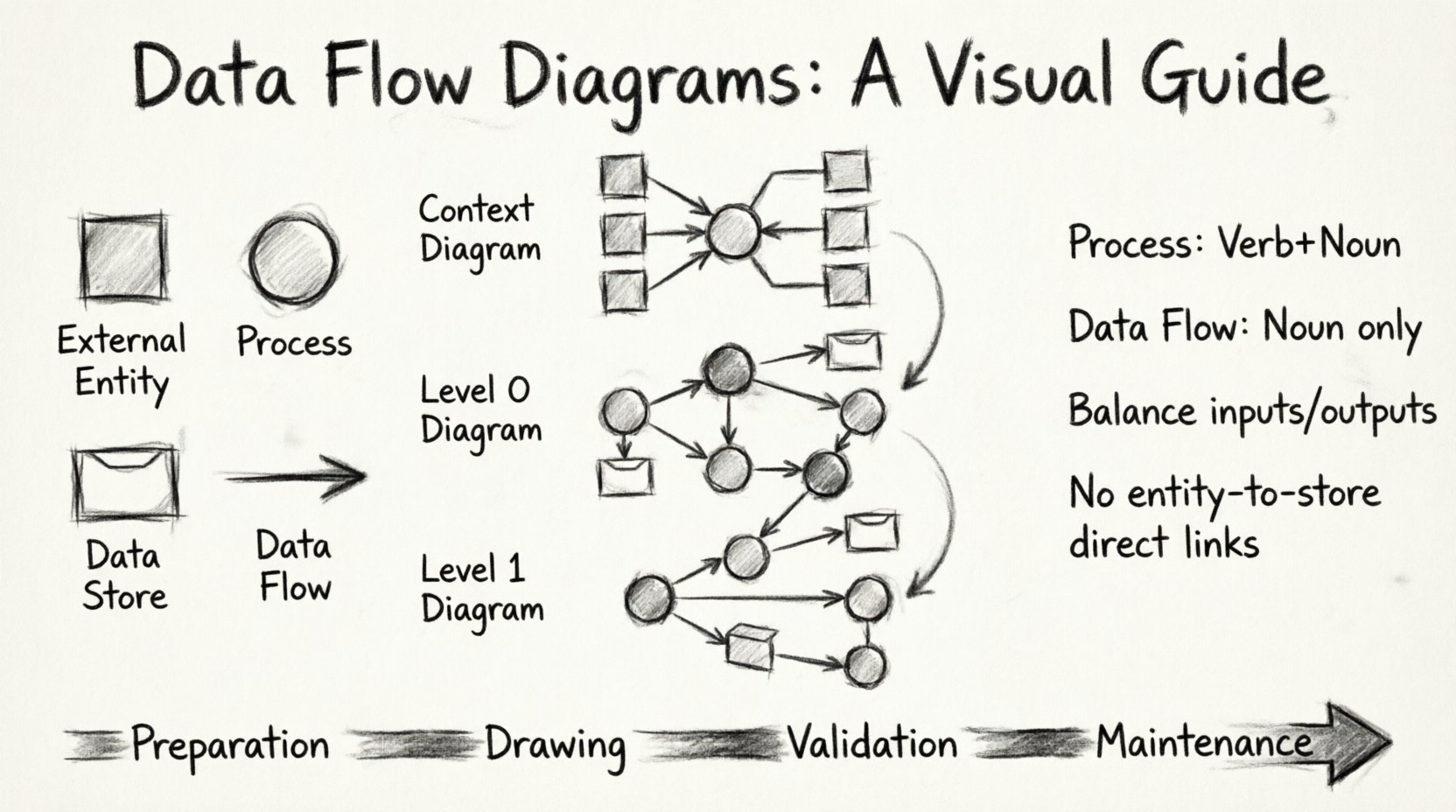
प्रत्येक DFD चार मानक प्रतीकों पर निर्भर करता है। इन प्रतीकों के डायग्राम की शब्दावली बनाते हैं। उनका सही तरीके से उपयोग करने से यह सुनिश्चित होता है कि कोई भी चार्ट पढ़ने वाला आर्किटेक्चर को समझ सके।
1. बाहरी एकाई (स्रोत या गंतव्य)
बाहरी एकाई मनुष्यों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करती हैं जो प्रक्रिया के साथ बातचीत करती हैं। वे प्रणाली की सीमा के बाहर स्थित होती हैं। डेटा उनसे आता है या उन्हें जाता है। आमतौर पर इन्हें वर्ग या आयताकार आकृति में बनाया जाता है।
2. प्रक्रिया (रूपांतरण)
एक प्रक्रिया डेटा को बदलती है। यह इनपुट लेती है, गणना या क्रिया करती है, और आउटपुट उत्पन्न करती है। यह डायग्राम का केंद्र बिंदु है। प्रक्रियाओं को आमतौर पर गोल या गोल किनारे वाले आयताकार आकृति में दर्शाया जाता है। प्रत्येक प्रक्रिया को कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
3. डेटा स्टोर (गोदाम)
डेटा स्टोर बाद में उपयोग के लिए जानकारी को संग्रहीत करते हैं। प्रक्रियाओं के विपरीत, वे डेटा को रूपांतर नहीं करते हैं; वे बस उसे सुरक्षित रखते हैं। उदाहरण के लिए डेटाबेस, फाइलें या कतारें हैं। इन्हें आमतौर पर खुले छोर वाले आयताकार या समानांतर रेखाओं के रूप में दिखाया जाता है।
4. डेटा प्रवाह (संबंध)
डेटा प्रवाह जानकारी के आंदोलन का प्रतिनिधित्व करते हैं। तीर दिशा को दर्शाते हैं। प्रत्येक प्रवाह को डेटा का वर्णन करने वाले संज्ञा वाक्यांश से लेबल किया जाना चाहिए, क्रिया शब्द के बजाय। उदाहरण के लिए, “ऑर्डर विवरण” सही है, जबकि “ऑर्डर प्रोसेस करें” गलत है।
तैयारी चरण 📝
तुरंत ड्रॉ करने की कोशिश करने से अक्सर भ्रम उत्पन्न होता है। तैयारी सुनिश्चित करती है कि डायग्राम प्रबंधनीय बना रहे। पहली रेखा बनाने से पहले इन चरणों का पालन करें।
प्रणाली सीमा को परिभाषित करें
यह पहचानें कि प्रणाली के अंदर क्या है और बाहर क्या है। सीमा के भीतर की हर चीज सॉफ्टवेयर या प्रक्रिया द्वारा प्रबंधित की जाती है। बाहर की हर चीज बाहरी है। इस सीमा की मदद से बाहरी एकाई को कहाँ रखना है, यह तय करने में मदद मिलती है।
जानकारी के स्रोत एकत्र करें
मौजूदा दस्तावेजों की समीक्षा करें, हितधारकों से साक्षात्कार करें, और वर्तमान कार्य प्रवाह का अध्ययन करें। आपको यह जानने की आवश्यकता है कि कौन सी डेटा प्रणाली में प्रवेश करती है और क्या परिणाम अपेक्षित हैं। सटीक इनपुट डेटा के बिना, डायग्राम अनुमानित होगा।
चरण 1: संदर्भ डायग्राम 🌍
संदर्भ डायग्राम एक उच्च स्तरीय दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और उन बाहरी एकाई को जो इसके साथ बातचीत करती हैं। यह किसी भी DFD के लिए शुरुआती बिंदु है।
- एकल प्रक्रिया की पहचान करें:पूरे सिस्टम का प्रतिनिधित्व करने वाले एक वृत्त या बबल बनाएं। उसका नाम दें, जैसे कि “ऑर्डर मैनेजमेंट सिस्टम।”
- बाहरी एजेंटों को स्थापित करें:सभी उपयोगकर्ताओं, विभागों या बाहरी प्रणालियों के लिए वर्ग बनाएं। उदाहरण में “ग्राहक,” “गोदाम,” या “भुगतान गेटवे” शामिल हैं।
- डेटा प्रवाह बनाएं:एजेंटों को केंद्रीय प्रक्रिया से तीरों के द्वारा जोड़ें। प्रत्येक तीर को आदान-प्रदान किए जा रहे डेटा के साथ लेबल करें। यदि डेटा भेजा और प्राप्त किया जाता है, तो तीर दोनों दिशाओं में जाने चाहिए।
- पूर्णता की जांच करें:यह सुनिश्चित करें कि प्रत्येक बाहरी अंतरक्रिया का ध्यान रखा गया है। यदि कोई एजेंट डेटा भेजता है लेकिन कोई डेटा प्राप्त नहीं करता है, तो जांचें कि क्या उत्तर गायब है।
चरण 2: स्तर 0 आरेख (शीर्ष स्तर) 🏗️
जब संदर्भ स्थापित हो जाता है, तो एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करें। इसे स्तर 0 आरेख के रूप में जाना जाता है। यह प्रणाली को मुख्य कार्यात्मक क्षेत्रों में बांटता है।
- प्रक्रिया को विभाजित करें:एकल संदर्भ प्रक्रिया को 3 से 7 तक मुख्य प्रक्रियाओं से बदलें। बहुत अधिक न बनाएं, क्योंकि यह भ्रम का कारण बनता है, या बहुत कम, क्योंकि इसमें विवरण की कमी होती है।
- डेटा स्टोर की पहचान करें:यह निर्धारित करें कि इस स्तर पर डेटा कहां संग्रहीत करने की आवश्यकता है। जहां जानकारी प्राप्त की जाती है या संग्रहीत की जाती है, उन प्रक्रियाओं के बीच डेटा स्टोर रखें।
- प्रवाहों को जोड़ें:प्रक्रियाओं, एजेंटों और स्टोर के बीच तीर बनाएं। सुनिश्चित करें कि प्रत्येक प्रक्रिया को इनपुट और आउटपुट हो।
- संतुलन बनाए रखें:इस स्तर पर इनपुट और आउटपुट को संदर्भ आरेख के अनुरूप होना चाहिए। यदि संदर्भ आरेख में “ऑर्डर” प्रवेश कर रहा है, तो स्तर 0 आरेख में “ऑर्डर” किसी उप-प्रक्रिया में प्रवेश करना चाहिए।
चरण 3: स्तर 1 और उससे आगे तक विभाजन 🔍
यदि स्तर 0 आरेख में कोई प्रक्रिया जटिल है, तो उसके आगे विभाजन की आवश्यकता होती है। इससे स्तर 1 आरेख बनता है। आप इस प्रक्रिया को तब तक जारी रख सकते हैं जब तक प्रक्रियाएं इतनी सरल नहीं हो जाती हैं कि उन्हें सीधे लागू किया जा सके।
विभाजन के नियम
- एक प्रक्रिया एक समय में:अगले पर जाने से पहले एक उप-प्रक्रिया को विभाजित करने पर ध्यान केंद्रित करें। पूरी प्रणाली को एक ही समय में बनाने की कोशिश न करें।
- प्रवाहों को बनाए रखें:जब आप एक प्रक्रिया को छोटी प्रक्रियाओं में तोड़ते हैं, तो मूल प्रक्रिया में प्रवेश कर रहे डेटा को नए उप-प्रक्रियाओं में प्रवेश करना चाहिए। बाहर निकल रहे डेटा को नए उप-प्रक्रियाओं से आना चाहिए।
- विवरण सीमित करें:जब तक तर्क इतना स्पष्ट न हो जाए कि डेवलपर को आगे के विवरण के बिना कोड लिखने में सक्षम हो, तब तक विभाजन बंद कर दें। आमतौर पर, अधिकांश प्रणालियों के लिए तीन स्तर पर्याप्त होते हैं।
नामकरण प्रणाली और उत्तम व्यवहार 🏷️
स्थिर नामकरण आरेख को पढ़ने योग्य बनाता है। असंगत नामकरण भ्रम और त्रुटियों का कारण बनता है।
प्रक्रिया नाम
प्रक्रिया के नाम क्रिया के बाद एक संज्ञा होनी चाहिए। उदाहरण के लिए “उपयोगकर्ता की पुष्टि करें,” “कर की गणना करें,” या “रिपोर्ट बनाएं।” इससे क्रिया का संकेत मिलता है। “प्रणाली” या “डेटा” जैसे अस्पष्ट नामों से बचें। परिवर्तन का वर्णन करने के लिए सक्रिय क्रियाएँ का उपयोग करें।
डेटा प्रवाह के नाम
डेटा प्रवाह के नाम संज्ञा या संज्ञा वाक्यांश होने चाहिए। उदाहरण के लिए “ग्राहक आईडी,” “बिल,” या “भुगतान प्राप्ति पत्र”। “बिल भेजें” जैसे क्रियाओं से बचें क्योंकि प्रवाह स्वयं डेटा है, क्रिया नहीं। क्रिया प्रक्रिया है।
एकाधिकार के नाम
बाहरी एकाधिकार को एकवचन या बहुवचन संज्ञा के रूप में लिखा जाना चाहिए जो क्रियाकलाप करने वाले को दर्शाता है। “ग्राहक डेटा” के बजाय “ग्राहक” का उपयोग करें। “गोदाम प्रबंधन” के बजाय “गोदाम” का उपयोग करें। एकाधिकार क्रियाकलाप करने वाला है, डेटा नहीं।
डेटा प्रवाह नियम और सीमाएँ ⚖️
कठोर नियमों का पालन करने से डिजाइन में तार्किक त्रुटियाँ रोकी जा सकती हैं। इन सीमाओं को सुनिश्चित करना है कि आरेख एक वैध प्रणाली का प्रतिनिधित्व करता है।
| नियम | विवरण |
|---|---|
| डेटा स्टोर इनपुट | डेटा केवल प्रक्रिया से स्टोर में लिखा जा सकता है। एकाधिकार और स्टोर के बीच सीधे प्रवाह आमतौर पर अनुमत नहीं हैं। |
| डेटा स्टोर आउटपुट | डेटा केवल प्रक्रिया द्वारा स्टोर से पढ़ा जा सकता है। एकाधिकार स्टोर को सीधे प्राप्त नहीं कर सकते। |
| प्रक्रिया इनपुट/आउटपुट | प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होने चाहिए। वह प्रक्रिया जो डेटा को खाती है लेकिन उत्पन्न नहीं करती है, एक “काला छेद” है। वह प्रक्रिया जो इनपुट के बिना डेटा बनाती है, एक “जादुई स्रोत” है। दोनों त्रुटियाँ हैं। |
| डेटा प्रवाह का प्रतिच्छेदन | डेटा प्रवाह को सीधे डेटा स्टोर या बाहरी एकाधिकार को पार नहीं करना चाहिए। उन्हें प्रक्रिया के माध्यम से जाना चाहिए। |
सत्यापन और समीक्षा ✅
आरेख बनाने के बाद उसका सत्यापन करना आवश्यक है। इस चरण से यह सुनिश्चित करने के लिए कि मॉडल वास्तविकता के अनुरूप है।
संतुलन की जाँच करें
एक मातृ प्रक्रिया के इनपुट और आउटपुट की उसकी बच्ची प्रक्रियाओं के इनपुट और आउटपुट के साथ तुलना करें। मातृ प्रक्रिया में प्रवेश करने वाले डेटा को बच्ची प्रक्रियाओं में प्रवेश करने वाले डेटा के बराबर होना चाहिए। मातृ प्रक्रिया से निकलने वाले डेटा को बच्ची प्रक्रियाओं से निकलने वाले डेटा के बराबर होना चाहिए। यदि वे मेल नहीं खाते हैं, तो आरेख संतुलित नहीं है और सुधार की आवश्यकता होती है।
पूर्णता की जाँच करें
प्रत्येक डेटा प्रवाह की समीक्षा करें। क्या प्रत्येक डेटा के लिए एक गंतव्य है? क्या प्रत्येक प्रक्रिया के लिए एक स्रोत है? क्या ऐसे अनाथ डेटा स्टोर हैं जिनका कोई कनेक्शन नहीं है? एक पूर्ण आरेख में कोई खुला छोर नहीं होता है।
हितधारक सत्यापन
आरेख को उन लोगों को दिखाएं जो प्रणाली का उपयोग करते हैं। उनसे डेटा प्रवाह का पता लगाने के लिए कहें। क्या वे मार्ग से सहमत हैं? क्या वे गायब चरणों को पहचानते हैं? उनका प्रतिक्रिया सटीकता का अंतिम परीक्षण है।
आरेख को बनाए रखना 🔄
DFD एक बार का कार्य नहीं है। प्रणालियाँ विकसित होती हैं और आवश्यकताएँ बदलती हैं। आरेख को उनके साथ विकसित होना चाहिए।
- संस्करण नियंत्रण: परिवर्तनों का अनुसरण करें। संस्करणों को तारीखों या संख्याओं के साथ लेबल करें।
- नियमित रूप से अपडेट करें:जब भी कोई नया फीचर जोड़ा जाता है या कोई प्रक्रिया बदलती है, तुरंत DFD को अपडेट करें।
- पुराने संस्करणों को संग्रहीत करें:ऑडिट या डिबगिंग के दौरान संदर्भ के लिए पुराने आरेखों को रखें।
दृश्य सटीकता पर निष्कर्ष 🎯
डेटा प्रवाह आरेख बनाना तर्क और दृश्य प्रस्तुति का एक अनुशासित अभ्यास है। जटिल प्रणालियों को समझने योग्य भागों में विभाजित करने के लिए धैर्य की आवश्यकता होती है। ऊपर बताए गए चरणों का पालन करके, आप एक आरेख बना सकते हैं जो विकास और संचार के लिए विश्वसनीय नक्शा के रूप में कार्य कर सकता है।
लक्ष्य केवल रेखाएं खींचना नहीं है, बल्कि प्रवाह को समझना है। जब डेटा प्रवाह स्पष्ट होते हैं, तो प्रणाली डिज़ाइन स्पष्ट हो जाता है। इस स्पष्टता से त्रुटियां कम होती हैं और अंतिम उत्पाद में सुधार होता है। डेटा पर ध्यान केंद्रित करें, कोड पर नहीं, और आरेख अपना उद्देश्य प्रभावी ढंग से पूरा करेगा।