











डेटा फ्लो डायग्राम (DFD) प्रणाली विश्लेषण और डिज़ाइन में एक आधार के रूप में काम करते हैं। वे जानकारी के एक प्रणाली में गति के बारे में एक दृश्य प्रतिनिधित्व प्रदान करते हैं, बाहरी एकाधिकार, आंतरिक प्रक्रियाओं, डेटा स्टोरेज और उन्हें जोड़ने वाले फ्लो के बीच बातचीत को उजागर करते हैं। जबकि अवधारणा सरल है, इन डायग्राम की विस्तृतता आवश्यक विस्तार के आधार पर बहुत अधिक भिन्न हो सकती है। इस विभाजन में दो सबसे महत्वपूर्ण चरण स्तर 0 और स्तर 1 DFD हैं। इन दोनों स्तरों के बीच अंतर को समझना वास्तुकारों, विश्लेषकों और हितधारकों के लिए आवश्यक है जो अनावश्यक जटिलता में फंसे बिना प्रणाली के तर्क को संचारित करना चाहते हैं।
इस गाइड में स्तर 0 और स्तर 1 डायग्राम बनाने के लिए संरचनात्मक अंतर, उपयोग के मामले और सर्वोत्तम प्रथाओं का अध्ययन किया जाएगा। हम उच्च स्तर के संदर्भ दृश्य से विस्तृत कार्यात्मक विभाजन तक जाने के तरीके का अध्ययन करेंगे, जिससे आपके प्रणाली दस्तावेज़ीकरण में स्पष्टता और सटीकता सुनिश्चित होगी।
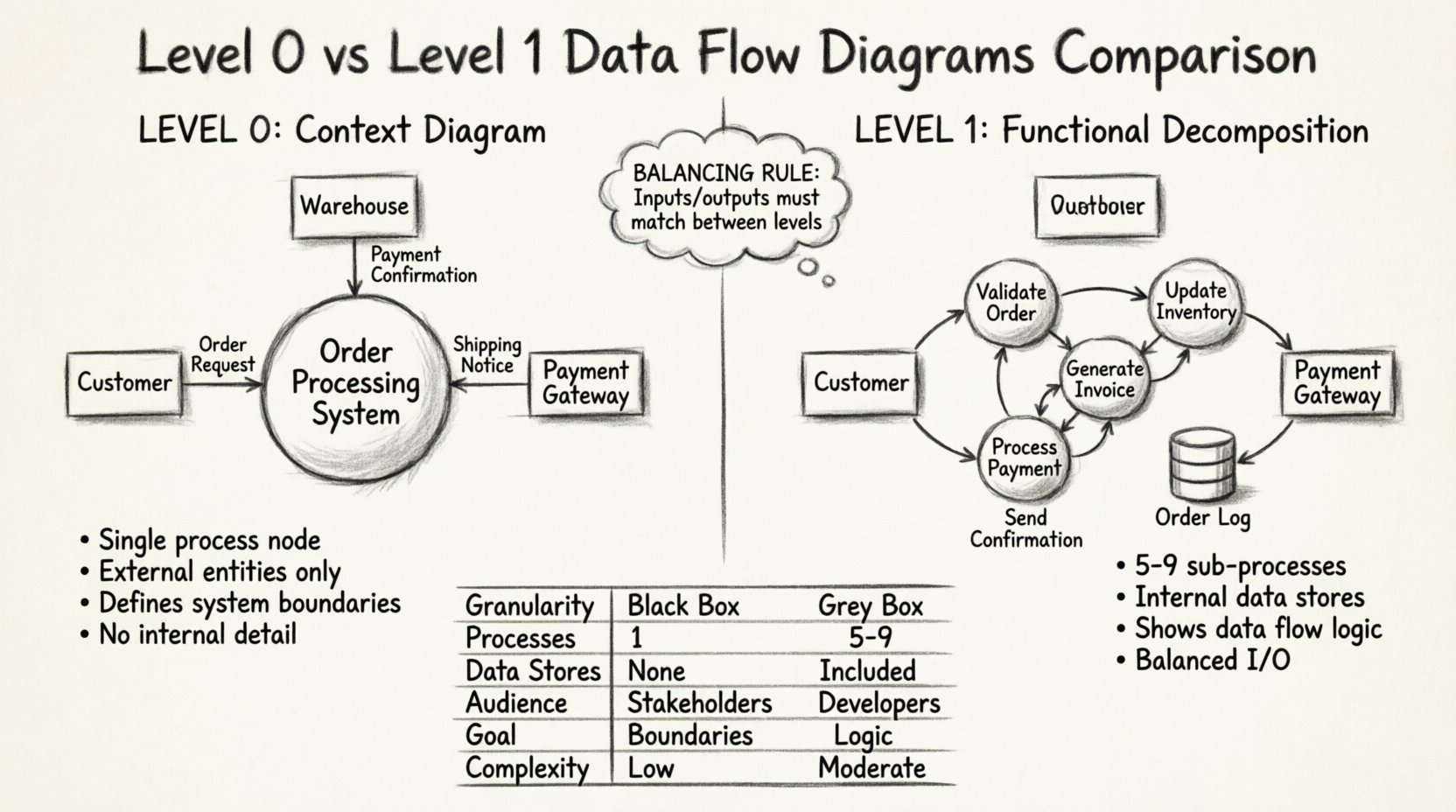
🧭 स्तर 0 डेटा फ्लो डायग्राम क्या है?
स्तर 0 DFD को अक्सर संदर्भ डायग्राम, प्रणाली को एकल, एकीकृत प्रक्रिया के रूप में दर्शाता है। यह DFD विभाजन में सर्वोच्च स्तर की सार्थकता है। यहाँ मुख्य लक्ष्य प्रणाली की सीमाओं को परिभाषित करना और यह दिखाना है कि यह बाहरी दुनिया के साथ कैसे बातचीत करती है।
मुख्य विशेषताएँ
- एकल प्रक्रिया नोड: पूरी प्रणाली को एक वृत्त या गोल आयत के रूप में दर्शाया जाता है, जिसे आमतौर पर प्रणाली के नाम से चिह्नित किया जाता है।
- बाहरी एकाधिकार: ये वे स्रोत या गंतव्य हैं जो प्रणाली की सीमा के बाहर स्थित हैं। उदाहरण में उपयोगकर्ता, अन्य प्रणालियाँ या नियामक निकाय शामिल हैं।
- डेटा प्रवाह: तीर बाहरी एकाधिकार और प्रणाली के बीच डेटा के इनपुट और आउटपुट को दर्शाते हैं।
- आंतरिक विवरण नहीं: डेटा स्टोरेज, उप-प्रक्रियाओं या आंतरिक डेटा गति को दिखाया नहीं गया है।
यह डायग्राम प्रश्न का उत्तर देता है: “प्रणाली क्या करती है, और यह किससे बातचीत करती है?” यह आमतौर पर आवश्यकता संग्रह चरण के दौरान पहला कार्य बनाया जाता है। यह प्रोजेक्ट के दायरे के बारे में हितधारकों के बीच साझा समझ प्रदान करता है, जब तक यह यांत्रिकी में डूबने से पहले नहीं।
स्तर 0 की दृश्य संरचना
कल्पना कीजिए कि पृष्ठ के केंद्र में एक बड़ा वृत्त है जिस पर “ऑर्डर प्रोसेसिंग सिस्टम” लेबल है। इस वृत्त के चारों ओर आयत हैं जो बाहरी एकाधिकार का प्रतिनिधित्व करते हैं, जैसे “ग्राहक”, “गोदाम”, और “भुगतान गेटवे”। रेखाएँ इन आयतों को केंद्रीय वृत्त से जोड़ती हैं, जिन्हें आदान-प्रदान किए जा रहे डेटा के नाम से लेबल किया गया है, जैसे “ऑर्डर अनुरोध” या “भुगतान पुष्टि”। इस सरलता से यह सुनिश्चित होता है कि तकनीकी रूप से अपरिचित हितधारक त्वरित रूप से प्रणाली के उद्देश्य को समझ सकते हैं।
⚙️ स्तर 1 डेटा फ्लो डायग्राम क्या है?
स्तर 1 DFD स्तर 0 डायग्राम पर विस्तार करता है जिसमें एकल प्रणाली प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित किया जाता है। यह छोटे विवरण में नहीं जाते हुए प्रणाली के आंतरिक तर्क को उजागर करता है। यह स्तर उच्च स्तर के संदर्भ और विस्तृत डिज़ाइन विवरणों के बीच के अंतर को पूरा करता है।
मुख्य विशेषताएँ
- विभाजित प्रक्रियाएँ: स्तर 0 से एकल प्रक्रिया को 5 से 9 तक मुख्य उप-प्रक्रियाओं में विभाजित किया जाता है। यह संख्या पठनीयता बनाए रखने के लिए एक दिशा-निर्देश है।
- आंतरिक डेटा स्टोरेज: इस स्तर पर डेटा को रखे जाने वाले भंडारों का परिचय दिया जाता है, जैसे डेटाबेस, फाइलें या कतारें।
- परिष्कृत डेटा प्रवाह: अब तीर यह दिखाते हैं कि डेटा उप-प्रक्रियाओं और डेटा स्टोरेज के बीच कैसे आता-जाता है।
- संतुलित इनपुट/आउटपुट स्तर 0 प्रक्रिया के इनपुट और आउटपुट को स्तर 1 उप-प्रक्रियाओं के संग्रहित इनपुट और आउटपुट के साथ मेल बैठाना आवश्यक है।
यह आरेख प्रश्न का उत्तर देता है: “प्रणाली अपने कार्य को कैसे प्राप्त करती है?” विकासकर्ताओं और सिस्टम वास्तुकारों के लिए महत्वपूर्ण है जिन्हें सूचना के प्रवाह को समझने की आवश्यकता है ताकि आधारभूत वास्तुकला बनाई जा सके।
स्तर 1 की दृश्य संरचना
पिछले उदाहरण का उपयोग करते हुए, “आदेश प्रोसेसिंग प्रणाली” के वृत्त को छोटे वृत्तों के संग्रह से प्रतिस्थापित किया जाता है। एक वृत्त “आदेश की पुष्टि” हो सकता है, दूसरा “इन्वेंटरी को अपडेट करना” और तीसरा “बिल जनरेट करना”। इन वृत्तों को तीरों द्वारा जोड़ा जाता है जो उनके बीच डेटा के आवागमन को दर्शाते हैं। साथ ही, एक बेलनाकार आकृति दिखाई दे सकती है, जो “ग्राहक डेटाबेस” या “आदेश लॉग” का प्रतिनिधित्व करती है। इस संरचना के कारण टीम को निर्भरताओं और डेटा रखरखाव की आवश्यकताओं को देखने में सहायता मिलती है।
🆚 तुलना: स्तर 0 बनाम स्तर 1
अंतरों को स्पष्ट करने के लिए, हम इन दोनों स्तरों की कई दिशाओं के आधार पर तुलना कर सकते हैं। यह तालिका संरचनात्मक और कार्यात्मक अंतरों को उजागर करती है।
| विशेषता | स्तर 0 (संदर्भ आरेख) | स्तर 1 (कार्यात्मक विभाजन) |
|---|---|---|
| विस्तार | प्रणाली-स्तरीय दृश्य (काला बॉक्स) | मुख्य कार्यात्मक मॉड्यूल (ग्रे बॉक्स) |
| प्रक्रियाओं की संख्या | बिल्कुल 1 | 5 से 9 तक मुख्य उप-प्रक्रियाएँ |
| डेटा भंडार | कोई नहीं दिखाया गया | स्पष्ट रूप से शामिल |
| दर्शक | हितधारक, प्रबंधन, उपयोगकर्ता | विकासकर्ता, सिस्टम वास्तुकार, विश्लेषक |
| प्राथमिक लक्ष्य | प्रणाली की सीमाओं को परिभाषित करना | आंतरिक तर्क और प्रवाह को परिभाषित करना |
| जटिलता | कम | मध्यम |
🔄 संतुलन की अवधारणा
स्तर 0 से स्तर 1 में जाते समय एक महत्वपूर्ण नियम है संतुलन. स्तर 0 प्रक्रिया में प्रवेश करने वाले और बाहर निकलने वाले इनपुट और आउटपुट को स्तर 1 उप-प्रक्रियाओं में प्रवेश करने वाले और बाहर निकलने वाले इनपुट और आउटपुट के संयुक्त रूप से समान होना चाहिए। इससे यह सुनिश्चित होता है कि विभाजन प्रक्रिया के दौरान कोई डेटा न तो बनाया जाए और न ही नष्ट किया जाए।
उदाहरण के लिए, यदि स्तर 0 पर “ग्राहक डेटा” के प्रवेश को दिखाया गया है, तो स्तर 1 में “ग्राहक डेटा” के कम से कम एक उप-प्रक्रिया में प्रवेश करने को दिखाना चाहिए। यदि स्तर 0 पर “रसीद” के प्रणाली से बाहर निकलने को दिखाया गया है, तो स्तर 1 में एक उप-प्रक्रिया को दिखाना चाहिए जो “रसीद” डेटा उत्पन्न करे। इस संतुलन को बनाए रखने में विफलता विश्लेषण में त्रुटि या डिजाइन में गायब घटक को इंगित करती है।
🛠 डिजाइन के लिए सर्वोत्तम प्रथाएँ
प्रभावी DFDs बनाने के लिए अनुशासन और विशिष्ट प्रथाओं का पालन करना आवश्यक है। इन दिशानिर्देशों का पालन करने से स्पष्टता बनाए रखने में मदद मिलती है और भ्रम से बचा जा सकता है।
1. नामकरण प्रथाएँ
प्रक्रियाओं के नाम एक क्रिया-संज्ञा संरचना के साथ रखे जाने चाहिए (उदाहरण के लिए, “कर की गणना” के बजाय “कर”)। डेटा प्रवाहों के नाम संज्ञा वाक्यांशों के साथ रखे जाने चाहिए जो सामग्री को इंगित करें (उदाहरण के लिए, “बिल के विवरण” के बजाय “बिल”)। बाहरी एकाधिकारों के नाम स्पष्ट रूप से रखे जाने चाहिए ताकि वे डेटा प्रदान करने वाले क्रियाकलाप या प्रणाली को दर्शाएं।
2. प्रतिच्छेदन से बचना
आरेख व्यवस्था में डेटा प्रवाह रेखाओं के प्रतिच्छेदन को कम से कम करना चाहिए। प्रतिच्छेदन वाली रेखाएँ दृश्य शोर में बदल जाती हैं और सूचना के मार्ग को ट्रैक करने में कठिनाई पैदा करती हैं। यदि प्रतिच्छेदन अनिवार्य है, तो सुनिश्चित करें कि वे अलग-अलग हों और स्पष्ट रूप से लेबल किए गए हों।
3. डेटा स्टोर संगतता
सुनिश्चित करें कि डेटा स्टोर को आरेखों में संगत रूप से लेबल किया गया हो। स्तर 1 में “ग्राहक डीबी” कहलाने वाले डेटाबेस को स्तर 2 में “उपयोगकर्ता तालिका” के नाम से नहीं बदला जाना चाहिए। संगतता विभिन्न स्तरों के चरणों में नेविगेशन और समझ में मदद करती है।
4. उप-प्रक्रियाओं की सीमा निर्धारित करना
जब तक स्तर 1 विस्तृत होना चाहिए, उसे व्यापक नहीं होना चाहिए। यदि एक उप-प्रक्रिया में बहुत अधिक तर्क है, तो उसके लिए अपना स्तर 2 विभाजन आवश्यक हो सकता है। हालांकि, स्तर 1 को आमतौर पर पठनीयता के लिए प्रबंधनीय सीमा में रखना चाहिए ताकि पाठक परेशान न हो।
📈 प्रत्येक स्तर का उपयोग कब करें
उचित स्तर का चयन परियोजना चरण और दर्शकों पर निर्भर करता है।
स्तर 0 का उपयोग करें:
- परियोजना प्रारंभ: शुरुआत में सीमा और सीमाओं को स्थापित करने के लिए।
- निदेशक सारांश: तकनीकी रूप से अपरिचित नेतृत्व को एक उच्च स्तर का अवलोकन प्रदान करने के लिए।
- इंटरफेस परिभाषा: यह स्पष्ट करने के लिए कि प्रणाली बाहरी प्रणालियों से कहाँ जुड़ती है।
स्तर 1 का उपयोग करें:
- प्रणाली डिजाइन: विकास टीम को आंतरिक तर्क पर मार्गदर्शन करने के लिए।
- एकीकरण योजना: यह पहचानने के लिए कि डेटा स्टोर और आंतरिक प्रवाह कहाँ होते हैं।
- परीक्षण रणनीति: प्रक्रिया मार्गों और डेटा रूपांतरणों के आधार पर परीक्षण मामलों को परिभाषित करने के लिए।
🔍 सामान्य चुनौतियाँ और समाधान
इन आरेखों को बनाने में अक्सर विशिष्ट चुनौतियाँ आती हैं। इन समस्याओं के बारे में जागरूक रहने से सटीक उपकरणों के निर्माण में मदद मिलती है।
समस्या: अनुपस्थित डेटा स्टोर
विश्लेषक कभी-कभी लेवल 1 आरेखों में डेटा स्टोर को शामिल करने के बारे में भूल जाते हैं, और प्रक्रियाओं के बीच डेटा प्रवाह सीधे होता है इसकी धारणा बनाते हैं। हालांकि, अधिकांश प्रणालियों को स्थायित्व की आवश्यकता होती है। सुनिश्चित करें कि आप उन स्थानों को पहचानें जहाँ लेनदेन के बीच डेटा सहेजा जाता है।
समस्या: भूत डेटा प्रवाह
एक भूत डेटा प्रवाह एक तीर है जो कहीं भी नहीं इशारा करता है या कहीं से भी उत्पन्न नहीं होता है। प्रत्येक तीर को किसी स्रोत (प्रक्रिया, एकाधिकार या स्टोर) से शुरू होना चाहिए और एक गंतव्य पर समाप्त होना चाहिए। अपने आरेख की जांच करें ताकि सुनिश्चित हो कि सभी रेखाएँ सही तरीके से जुड़ी हैं।
समस्या: अत्यधिक जटिलता
लेवल 1 में प्रत्येक एकल चरण को दिखाने की कोशिश करने से आरेख भारी हो सकता है। यदि लेवल 1 आरेख पढ़ने योग्य नहीं हो जाता है, तो प्रणाली को तार्किक उपप्रणालियों में विभाजित करने और प्रत्येक के लिए अलग-अलग लेवल 1 आरेख बनाने के बजाय एक विशाल आरेख के बजाय विचार करें।
🔗 उच्च स्तरों पर संक्रमण
जब लेवल 1 आरेख पूरा हो जाता है, तो यह लेवल 2 आरेखों के लिए माता-पिता के रूप में कार्य करता है। लेवल 1 से प्रत्येक उप-प्रक्रिया को आगे विभाजित किया जा सकता है। यह पुनरावर्ती प्रक्रिया तब तक जारी रहती है जब तक कि प्रक्रियाएँ इतनी सरल नहीं हो जाती हैं कि उन्हें सीधे कोड या कॉन्फ़िगरेशन के रूप में लागू किया जा सके। लेवल 1 आरेख एक महत्वपूर्ण चरण है जो विभाजन रणनीति के सही होने की गारंटी देता है, जब तक विशिष्ट एल्गोरिदम या डेटाबेस स्कीमा के विवरण में डूबने से पहले नहीं।
📝 अंतरों का सारांश
लेवल 0 और लेवल 1 डेटा प्रवाह आरेख सिस्टम विश्लेषण में अलग-अलग लेकिन पूरक भूमिकाएँ निभाते हैं। लेवल 0 प्रणाली की सीमा और बाहरी वातावरण के साथ इसके संबंध को परिभाषित करता है। लेवल 1 ने झाड़ू उतारकर मुख्य कार्यात्मक घटकों और आंतरिक डेटा संचालन को उजागर करता है। एक साथ, वे एक परतदार दृष्टिकोण बनाते हैं जो रणनीतिक योजना और रणनीतिक कार्यान्वयन दोनों को समर्थन देता है।
संतुलन, स्थिर नामाकरण और उचित विविधता के सिद्धांतों का पालन करके, टीमें इन आरेखों का उपयोग अस्पष्टता को कम करने, उम्मीदों को समायोजित करने और टिकाऊ प्रणालियों का निर्माण करने के लिए कर सकती हैं। चाहे आप पुराने एप्लिकेशन का दस्तावेजीकरण कर रहे हों या एक नई वास्तुकला का डिज़ाइन कर रहे हों, इन स्तरों के बीच अंतर को समझना स्पष्ट संचार और प्रभावी प्रणाली मॉडलिंग सुनिश्चित करता है।