











जब जटिल प्रणालियों का मॉडलिंग किया जाता है, तो स्पष्टता मुख्य लक्ष्य होती है। डेटा फ्लो डायग्राम (DFD) एक प्रणाली के माध्यम से जानकारी के आवागमन को दृश्य रूप से दर्शाने के लिए एक आधारभूत उपकरण के रूप में कार्य करते हैं। इस ढांचे के भीतर, दो प्रतीक दृश्य को नियंत्रित करते हैं: औरप्रक्रिया औरडेटा स्टोर। हालांकि वे अक्सर बातचीत करते हैं, लेकिन उनके रूपांतरण और स्थायित्व के संबंध में मूल रूप से अलग अवधारणाओं का प्रतिनिधित्व करते हैं। सही विश्लेषण और डिजाइन के लिए इनके बीच के अंतर को समझना आवश्यक है।
यह गाइड इन तत्वों के कार्यात्मक भूमिकाओं, दृश्य प्रतिनिधित्वों और तार्किक प्रभावों का अध्ययन करता है। क्रिया और भंडारण के बीच अंतर स्थापित करके, विश्लेषक प्रणाली के व्यवहार को अस्पष्टता के बिना संचारित करने वाले आरेख बना सकते हैं।
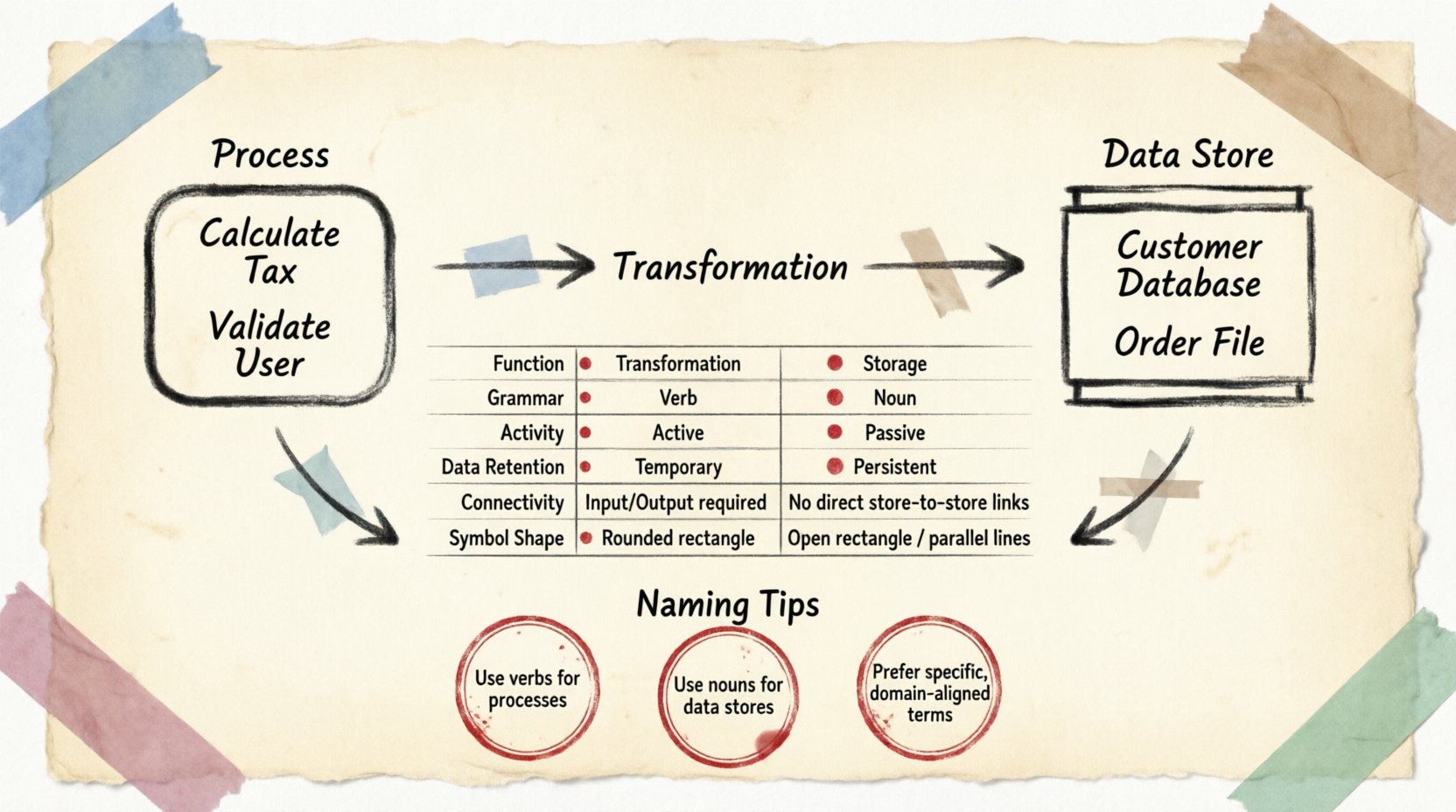
🔄 प्रक्रिया को परिभाषित करना
एक प्रक्रिया कार्य के एक इकाई या रूपांतरण का प्रतिनिधित्व करती है। यह वह स्थान है जहां डेटा के रूप में बदलाव होता है, गणना की जाती है या फ़िल्टर की जाती है। एक प्रक्रिया को एक काले बॉक्स के रूप में सोचें। आपको पता है कि क्या आता है और क्या बाहर निकलता है, लेकिन आंतरिक तंत्र उस जानकारी के भंडारण के बजाय रूपांतरण तर्क द्वारा निर्धारित किया जाता है।
🔹 मुख्य विशेषताएं
- रूपांतरण: मुख्य कार्य डेटा को संशोधित करना है। इनपुट डेटा प्रवेश करता है, नियम या तर्क लागू किए जाते हैं, और आउटपुट डेटा बाहर निकलता है।
- कालिक प्रकृति: प्रक्रियाएं केवल तब सक्रिय होती हैं जब उत्तेजित की जाती हैं। वे निष्पादनों के बीच डेटा को बनाए नहीं रखती हैं।
- दिशात्मकता: डेटा एक प्रक्रिया में आता है और बाहर निकलता है। एक प्रक्रिया जिसके बिना इनपुट या आउटपुट हो, DFD संदर्भ में तार्किक रूप से अमान्य है।
- क्रिया नामकरण: प्रक्रियाओं को आमतौर पर क्रिया या क्रिया वाक्यांशों के साथ लेबल किया जाता है (उदाहरण के लिए, कर की गणना करें, उपयोगकर्ता की पुष्टि करें, रिपोर्ट उत्पन्न करें).
🔹 काला बॉक्स अवधारणा
उच्च स्तरीय मॉडलिंग में, एक प्रक्रिया एक काला बॉक्स है। ध्यान केंद्रित है क्याडेटा पर क्या होता है, न किकैसे यह तकनीकी रूप से कैसे होता है। उदाहरण के लिए, “ऑर्डर प्रक्रिया” नामक एक प्रक्रिया ऑर्डर विवरण लेती है और एक लेनदेन रिकॉर्ड बनाती है। यह नहीं बताता है कि क्या गणना मेमोरी में, डिस्क पर या एक दूरस्थ API के माध्यम से होती है। इस अमूर्तता के कारण स्टेकहोल्डर्स को तकनीकी कार्यान्वयन के बजाय व्यापार तर्क पर ध्यान केंद्रित करने की अनुमति मिलती है।
हालांकि, जैसे ही आरेख निचले स्तरों में विभाजित होते हैं, आंतरिक तर्क अधिक विस्तृत हो जाता है। फिर भी, प्रक्रिया एक सक्रिय रूपांतरण इंजन बनी रहती है। यह इनपुट का उपभोग करती है, कार्य करती है और आउटपुट उत्पन्न करती है। यह उस जानकारी के लिए एक धारण टैंक के रूप में कार्य नहीं करती है।
🗄️ डेटा स्टोर को परिभाषित करना
एक डेटा स्टोर एक भंडारण स्थान का प्रतिनिधित्व करता है जहां जानकारी रखी जाती है। प्रक्रिया के विपरीत, एक डेटा स्टोर डेटा को परिवर्तित नहीं करता है। यह प्रतीक्षा करता है। यह डेटा को एक स्थायी अवस्था में रखता है जब तक कि एक प्रक्रिया इसे प्राप्त नहीं करती या एक प्रक्रिया इसे वहां रखती नहीं है।
🔹 मूल विशेषताएं
- स्थायित्व: डेटा एक स्टोर में तब भी रहता है जब कोई प्रक्रिया सक्रिय नहीं होती है। यह मेमोरी बफर या अस्थायी चर के विपरीत अंतर का मुख्य बिंदु है।
- निष्क्रिय प्रकृति: डेटा स्टोर को कोई क्रिया शुरू नहीं करते हैं। उन्हें पढ़ने या लिखने के लिए एक प्रक्रिया की आवश्यकता होती है।
- संज्ञा नामकरण: स्टोर को आमतौर पर संज्ञा (जैसे, ग्राहक डेटाबेस, आदेश फ़ाइल, इन्वेंटरी लॉग).
- खुला-अंत: डेटा प्रवाह एक स्टोर में प्रवेश और निकास कर सकता है। हालांकि, एक स्टोर दूसरे स्टोर से सीधे नहीं जुड़ सकता है। डेटा को भंडारों के बीच ले जाने के लिए एक प्रक्रिया के माध्यम से प्रवाहित होना आवश्यक है।
🔹 भंडारण अवधारणा
एक पुस्तकालय की कल्पना करें। पुस्तकें डेटा हैं। दराज डेटा स्टोर हैं। एक पुस्तकालय अधिकारी प्रक्रिया है। पुस्तकालय अधिकारी पुस्तकों का निर्माण नहीं करता है; वह उन्हें व्यवस्थित करता है। दराज स्वयं पुस्तकों को नहीं हटाते हैं; वे उन्हें जगह पर रखते हैं। जब कोई पाठक पुस्तक मांगता है, तो पुस्तकालय अधिकारी उसे निकालता है (पढ़ने की क्रिया)। जब एक नई पुस्तक आती है, तो पुस्तकालय अधिकारी उसे दराज पर रखता है (लेखन की क्रिया)।
सिस्टम वार्ता में, एक डेटा स्टोर एक डेटाबेस तालिका, एक समतल फ़ाइल, एक कतार या एक क्लाउड बैग का प्रतिनिधित्व कर सकता है। DFD प्रतीक तकनीक को सारांशित करता है। चाहे यह SQL तालिका हो या साधारण टेक्स्ट फ़ाइल, तार्किक भूमिका समान होती है: यह एक ऐसी जगह है जहां जानकारी रखी जाती है।
⚡ अंतरक्रिया और डेटा प्रवाह
प्रक्रिया और डेटा स्टोर के बीच संबंध डेटा प्रवाह के सख्त नियमों द्वारा नियंत्रित होता है। DFD में तीर डेटा के गति का प्रतिनिधित्व करते हैं। इन तीरों के द्वारा सूचना स्थानांतरण की दिशा निर्धारित होती है।
🔹 पढ़ने-लिखने का चक्र
जब कोई प्रक्रिया जानकारी के लिए आवश्यकता महसूस करती है, तो वह डेटा स्टोर से प्रक्रिया की ओर एक तीर खींचती है। इससे पढ़ने की क्रिया का संकेत मिलता है। प्रक्रिया डेटा को निकालती है जिसका उपयोग इसके परिवर्तन तर्क में किया जाता है। विपरीत रूप से, जब प्रक्रिया नई जानकारी उत्पन्न करती है, तो वह प्रक्रिया से डेटा स्टोर की ओर एक तीर खींचती है। इससे लिखने की क्रिया का संकेत मिलता है। अब डेटा भविष्य के उपयोग के लिए स्टोर कर लिया गया है।
महत्वपूर्ण बात यह है कि डेटा प्रवाह दो डेटा स्टोर को सीधे नहीं जोड़ सकता है। डेटा किसी भंडारण से दूसरे भंडारण में बिना प्रक्रिया के स्थानांतरित नहीं हो सकता है। यह नियम इस सिद्धांत को बल देता है कि डेटा स्थानांतरण हमेशा किसी स्तर के तर्क या नियंत्रण के साथ जुड़ा होता है, भले ही वह तर्क सरल कॉपी क्रिया हो।
🔹 बाहरी एकाइयाँ
बाहरी एकाइयाँ (स्रोत या निकास) प्रक्रियाओं के साथ बातचीत करती हैं, डेटा स्टोर के सीधे नहीं। एक बाहरी एकाई मानव उपयोगकर्ता, तीसरे पक्ष का API या दूसरा सिस्टम हो सकता है। वे डेटा को प्रक्रिया को भेजते हैं या प्रक्रिया से डेटा प्राप्त करते हैं। फिर प्रक्रिया तय करती है कि उस डेटा को भंडारण में स्टोर करना है या उसे फेंक देना है।
📋 तुलना सारणी
संरचनात्मक अंतरों का सारांश देने के लिए, निम्नलिखित विशेषताओं के विभाजन पर विचार करें।
| विशेषता | प्रक्रिया | डेटा स्टोर |
|---|---|---|
| कार्य | रूपांतरण / क्रिया | स्टोरेज / मेमोरी |
| व्याकरण | क्रिया (उदाहरण के लिए, अपडेट करें) | संज्ञा (उदाहरण के लिए, उपयोगकर्ता तालिका) |
| गतिविधि | सक्रिय (प्रेरित होने पर चलता है) | निष्क्रिय (प्राप्त किए जाने तक बैठता है) |
| डेटा अवधारणा | अस्थायी (निष्पादन के दौरान) | स्थायी (लंबे समय तक) |
| कनेक्टिविटी | एंटिटीज, स्टोर्स, अन्य प्रक्रियाओं से जुड़ता है | केवल प्रक्रियाओं से जुड़ता है |
| प्रतीक आकृति | गोलाकार आयत या वृत्त | खुला आयत या समानांतर रेखाएँ |
🧩 नामकरण प्रथाएँ
नामकरण में सुसंगतता समीक्षा और कार्यान्वयन चरणों के दौरान भ्रम को रोकती है। जब एक ही शब्द का उपयोग स्टोरेज और क्रिया दोनों के लिए किया जाता है, तो अस्पष्टता अक्सर उत्पन्न होती है।
🔹 प्रक्रिया नामकरण
नामों को डेटा पर की जा रही क्रिया का वर्णन करना चाहिए। “करो यह” या “हैंडल करो” जैसे सामान्य नामों से बचें। इसके बजाय विशिष्ट वर्णनकर्ता का उपयोग करें। उदाहरण के लिए, “लॉगिन प्रमाणपत्र की पुष्टि करें” को “लॉगिन चेक करें” से बेहतर है। इस स्पष्टता से डेवलपर्स को तुरंत अपेक्षित इनपुट और आउटपुट आवश्यकताओं को समझने में मदद मिलती है।
🔹 डेटा स्टोर नामकरण
नामों को भीतर रखे गए सामग्री का प्रतिबिंबित करना चाहिए। बहुवचन संज्ञाओं या स्पष्ट पहचानकर्ताओं का उपयोग करें। “ऑर्डर्स” ऑर्डर रिकॉर्ड्स के संग्रह को इंगित करता है। “ऑर्डर” एकल लेनदेन उदाहरण को इंगित कर सकता है। संदर्भ महत्वपूर्ण है, लेकिन बहुवचन संज्ञाएँ आम तौर पर एक भंडारण स्थान को इंगित करती हैं जो एक से अधिक रिकॉर्ड्स को संग्रहीत करती है।
जब डेटा स्टोर के नामकरण कर रहे हों, तो उसके दायरे को ध्यान में रखें। “डेटाबेस” नाम वाला स्टोर बहुत अस्पष्ट है। “ग्राहक डेटाबेस” या “लेनदेन लॉग” आवश्यक संदर्भ प्रदान करते हैं। इस विस्तार की सहायता बाद में आरेख को भौतिक स्टोरेज संरचनाओं से मैप करने में मिलती है।
🧪 विघटन और स्तर
DFD हीरार्किक होते हैं। एक उच्च स्तर का आरेख (संदर्भ आरेख) प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। जैसे आप इसे निम्न स्तरों में विघटित करते हैं, प्रक्रिया और स्टोर के बीच का अंतर अधिक महत्वपूर्ण हो जाता है।
🔹 स्तर 0 बनाम स्तर 1
एक संदर्भ आरेख में, पूरी प्रणाली एक प्रक्रिया होती है। स्तर 0 पर, इस प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित किया जाता है। यहाँ डेटा स्टोर का परिचय दिया जाता है ताकि बड़े डेटा घटकों के स्थान को दिखाया जा सके। स्तर 1 और उससे आगे, प्रक्रियाओं को और अधिक निर्माण किया जाता है।
विघटन के दौरान सुनिश्चित करें कि डेटा स्टोर की अनावश्यक दोहराव न हो। यदि स्तर 0 पर कोई स्टोर मौजूद है, तो आमतौर पर यह स्तर 1 तक बना रहना चाहिए, जब तक कि कोई विशिष्ट उप-प्रक्रिया अस्थायी कैश की आवश्यकता न हो (जो एक अलग स्टोर होगा)। स्तरों के बीच सुसंगतता ट्रेसेबिलिटी सुनिश्चित करती है।
🔹 संतुलन
विघटन में एक महत्वपूर्ण नियम “संतुलन” है। मातृ प्रक्रिया के इनपुट और आउटपुट को निम्न स्तर के आरेख में बच्चे प्रक्रियाओं के इनपुट और आउटपुट के साथ मेल बैठाना चाहिए। डेटा स्टोर को भी संरेखित करना चाहिए। यदि कोई स्टोर मातृ आरेख में दिखाई देता है, तो बच्चे आरेख में उस डेटा प्रवाह को सही तरीके से ध्यान में रखना चाहिए। यदि कोई प्रक्रिया विभाजित की जाती है, तो स्टोर तक डेटा प्रवाह को विभाजन के बीच बनाए रखना चाहिए।
⚠️ बचने के लिए तार्किक त्रुटियाँ
कुछ संरचनात्मक गलतियाँ एक आरेख को अमान्य कर सकती हैं। इन त्रुटियों को विकास चरण के दौरान समय बचाने के लिए जल्दी से पहचानना चाहिए।
- भूत डेटा प्रवाह: एक प्रक्रिया से बिना आने वाले डेटा प्रवाह के साथ एक तीर निकलना असंभव है। एक प्रक्रिया किसी भी चीज के बिना आउटपुट नहीं बना सकती है। प्रत्येक आउटपुट को इनपुट या संग्रहीत डेटा से निकाला जाना चाहिए।
- सीधे स्टोर कनेक्शन: जैसा कि उल्लेख किया गया है, एक स्टोर दूसरे स्टोर से नहीं जुड़ सकता है। डेटा को प्रक्रिया के माध्यम से गुजरना चाहिए। इससे यह सुनिश्चित होता है कि सभी डेटा गतिशीलता जानबूझकर और प्रक्रिया में होती है।
- अनकनेक्टेड प्रक्रियाएँ: एक प्रक्रिया जिसमें कोई आने वाला या निकलने वाला डेटा प्रवाह नहीं है, अलग है। यह प्रणाली से कोई बातचीत नहीं करती है और DFD में कोई उद्देश्य नहीं रखती है।
- एंटिटीज और स्टोर्स को गलती से मिलाना: बाहरी एंटिटीज प्रणाली की सीमा के बाहर होती हैं। डेटा स्टोर्स अंदर होते हैं। बाहरी एंटिटी के प्रतीक को प्रणाली की सीमा के अंदर न रखें, जैसे कि वह एक डेटाबेस हो।
🛠️ कार्यान्वयन के प्रभाव
प्रक्रिया और स्टोर के बीच अंतर यह निर्धारित करता है कि प्रणाली कैसे बनाई जाती है। प्रक्रियाएँ फंक्शन, मेथड या माइक्रोसर्विसेज से मैप होती हैं। डेटा स्टोर्स टेबल, फाइल या ऑब्जेक्ट स्टोरेज से मैप होते हैं।
🔹 डेटाबेस डिज़ाइन
जब डेटाबेस का डिज़ाइन किया जाता है, तो DFD में डेटा स्टोर्स स्कीमा ब्लूप्रिंट बन जाते हैं। डेटा प्रवाह तीरों के भीतर के लक्षण कॉलम को परिभाषित करते हैं। स्टोर्स के बीच संबंध (प्रक्रियाओं द्वारा मध्यस्थता के माध्यम से) फॉरेन की या ट्रांजैक्शनल लिंक्स को परिभाषित करते हैं।
🔹 वर्कफ्लो स्वचालन
वर्कफ्लो इंजन के लिए, प्रक्रियाएँ पाइपलाइन में चरणों का प्रतिनिधित्व करती हैं। डेटा स्टोर्स वर्कफ्लो की स्थिति का प्रतिनिधित्व करते हैं। एक प्रक्रिया स्टोर में स्थिति को अपडेट कर सकती है ताकि कार्य को पूरा किया गया माना जाए। स्टोर की सक्रिय प्रकृति को समझने से यह सुनिश्चित होता है कि वर्कफ्लो इंजन आगे बढ़ने से पहले सही स्थिति का इंतजार करता है।
🔍 दृश्य प्रतिनिधित्व मानक
विभिन्न पद्धतियाँ थोड़ी अलग-अलग प्रतीकों का उपयोग करती हैं, लेकिन तर्क समान रहता है।
- डेमार्को और यौरडन: प्रक्रियाओं के लिए गोल किनारे वाले आयत और डेटा स्टोर्स के लिए खुले आयत का उपयोग करता है।
- गेन और सर्सन: प्रक्रियाओं के लिए गोल किनारे वाले आयत और डेटा स्टोर्स के लिए समानांतर रेखाओं का उपयोग करता है।
चाहे किसी भी नोटेशन का चयन किया जाए, अर्थगत अर्थ समान होता है। एक प्रक्रिया कार्य करती है; एक स्टोर रखता है। परियोजना दस्तावेज़ में संगतता का महत्व एक विशिष्ट मानक का पालन करने से अधिक महत्वपूर्ण है, बशर्ते कि टीम चुनी गई परंपरा को समझती हो।
🎯 भूमिकाओं का सारांश
एक टिकाऊ प्रणाली मॉडल बनाने के लिए भूमिकाओं के निर्धारण में अनुशासन की आवश्यकता होती है। प्रक्रिया कलाकार है। यह काम करती है। डेटा स्टोर स्टेज है। यह सामान रखता है। बिना कलाकार के, स्टेज खाली है। बिना स्टेज के, कलाकार के पास अपने निष्कर्षों को रखने के लिए कहीं नहीं है।
परिवर्तन और संग्रहण के बीच स्पष्ट अंतर बनाए रखकर विश्लेषक ऐसे आरेख बनाते हैं जो केवल दृश्य रूप से आकर्षक नहीं होते बल्कि तार्किक रूप से भी स्थिर होते हैं। ये आरेख व्यावसायिक स्टेकहोल्डर्स और तकनीकी टीमों के बीच एक अनुबंध के रूप में कार्य करते हैं। वे ज़िम्मेदारी की सीमा और मूल्य के प्रवाह को परिभाषित करते हैं।
जब DFD की समीक्षा करते हैं, तो प्रत्येक प्रतीक के लिए दो प्रश्न पूछें: “क्या यह काम कर रहा है?” (प्रक्रिया) या “क्या यह जानकारी रख रहा है?” (स्टोर)। यदि उत्तर अस्पष्ट है, तो लेबल या कनेक्शन को सुधारें। स्पष्टता प्रणाली मॉडलिंग का अंतिम लक्ष्य है।
इन सिद्धांतों का पालन करने से यह सुनिश्चित होता है कि परिणामी आर्किटेक्चर रखरखाव योग्य, स्केलेबल और समझने योग्य होती है। अंतर सरल है, लेकिन इसका प्रणाली की अखंडता पर प्रभाव गहन है।