











Construir sistemas de software confiables requiere más que simplemente escribir código funcional. Exige una comprensión clara de cómo se comporta el sistema bajo diversas condiciones. Los diagramas de máquinas de estado, a menudo denominados simplemente diagramas de estado, proporcionan el plano de este comportamiento. Muestran los modos distintos que un sistema puede ocupar y las reglas que rigen las transiciones entre ellos. Sin embargo, a medida que los sistemas crecen en complejidad, aumenta la probabilidad de errores lógicos. Depurar estos problemas requiere un enfoque estructurado, una profunda comprensión de la lógica subyacente y una eliminación metódica de variables.
Esta guía describe las estrategias esenciales para identificar y resolver errores lógicos dentro de arquitecturas basadas en estados. Al comprender la anatomía de las transiciones de estado y los errores comunes, los ingenieros pueden mantener la integridad del sistema sin depender de conjeturas.
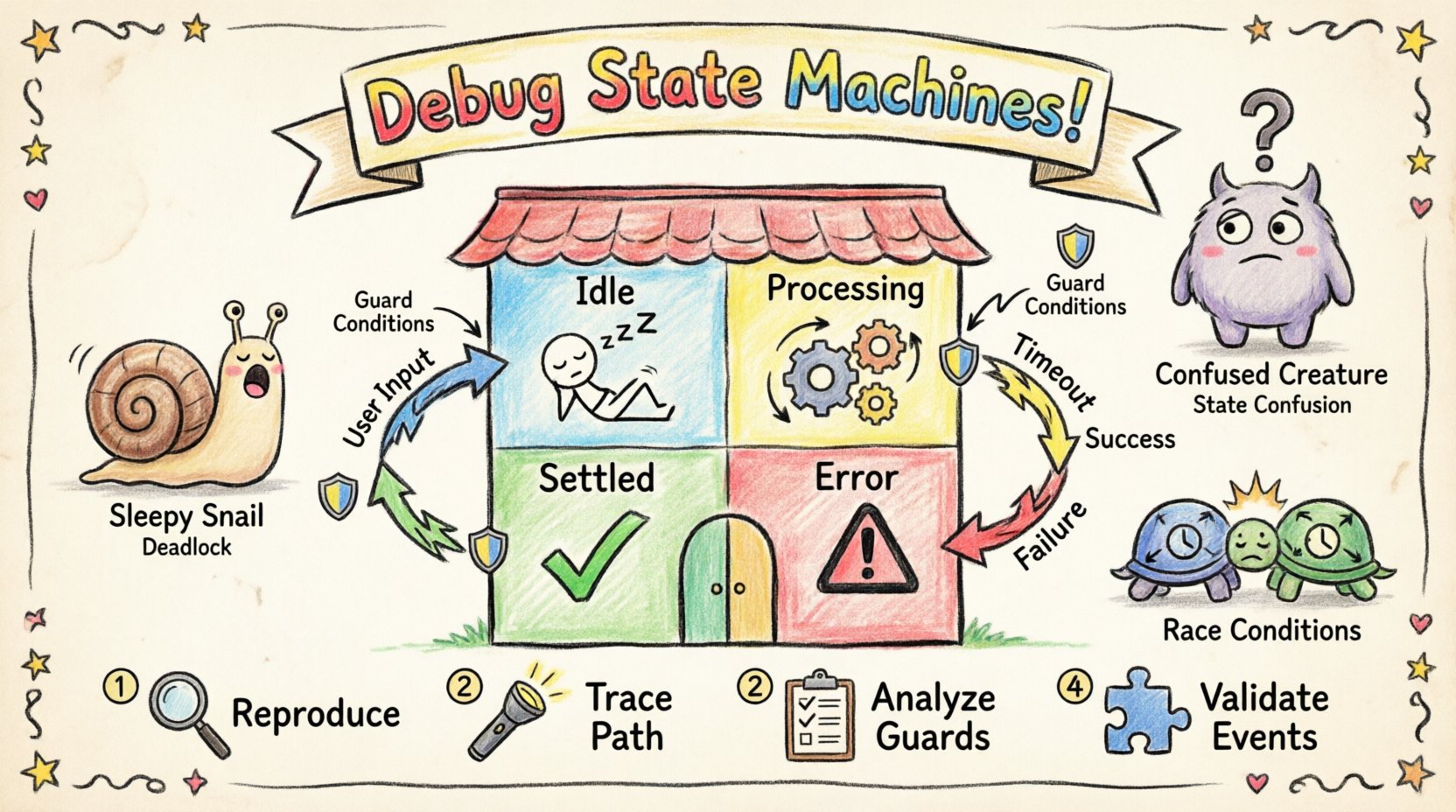
🔍 Comprender la anatomía de una máquina de estados
Antes de solucionar problemas, uno debe comprender los componentes que impulsan la máquina de estados. Un diagrama de estado no es meramente una representación visual; es un contrato lógico que define el ciclo de vida del sistema. Cada elemento cumple una función específica en el control del flujo y los datos.
- Estados: Modos o condiciones distintos en los que el sistema puede existir. Ejemplos incluyen Ocioso, Procesando, o Error.
- Transiciones: Los caminos que conectan estados. Una transición ocurre cuando un evento específico desencadena un cambio de un estado a otro.
- Eventos: Señales o acciones que desencadenan transiciones. Pueden ser acciones internas o entradas externas.
- Guardas: Condiciones booleanas evaluadas durante una transición. La transición solo ocurre si la guarda se evalúa como verdadera.
- Acciones: Operaciones realizadas al entrar, salir o durante una transición. Pueden incluir registro, actualización de datos o activación de servicios externos.
- Estados inicial/final: El punto de partida y el punto de terminación del ciclo de vida.
Al depurar, es crucial verificar que estos componentes interactúen correctamente. Un error lógico a menudo proviene de una discrepancia entre el comportamiento esperado definido en el diagrama y el comportamiento real en el entorno de ejecución.
🚨 Errores lógicos comunes y sus síntomas
Los sistemas complejos frecuentemente sufren de tipos específicos de fallas lógicas. Reconocer los síntomas temprano puede ahorrar tiempo significativo durante el proceso de depuración. La tabla a continuación categoriza problemas comunes, sus síntomas observables y las causas raíz más probables.
| Tipo de error | Síntoma | Causa raíz |
|---|---|---|
| Transiciones espurias | El sistema pasa a un estado inesperado sin un desencadenante claro. | Condiciones de guarda faltantes o controladores de eventos superpuestos. |
| Muertes en espera | El sistema se detiene y no responde a entradas válidas. | No hay transiciones salientes desde un estado específico para ciertos eventos. |
| Estados inaccesibles | Ciertos estados nunca se ingresan durante la operación normal. | Rutas de entrada incorrectas o lógica que salta estados específicos. |
| Confusión de estados | El sistema se comporta de manera diferente en el mismo estado dependiendo del historial. | Fallo al restablecer el contexto o gestionar correctamente los estados de historial. |
| Condiciones de carrera concurrentes | Acciones conflictivas ocurren simultáneamente en estados paralelos. | Falta de sincronización entre submáquinas concurrentes. |
🧪 Metodología paso a paso para depuración
Resolver problemas de máquinas de estado requiere un flujo de trabajo disciplinado. Las soluciones puntuales a menudo introducen nuevos errores. Siga este enfoque sistemático para aislar y corregir errores lógicos.
1. Reproduzca el problema
Antes de intentar una solución, debe reproducir confiablemente el error. Si el problema es intermitente, documente la secuencia de eventos que llevan al fallo.
- Identifique la entrada o evento específico que desencadena el comportamiento incorrecto.
- Registre el estado actual del sistema antes de que ocurra el evento.
- Registre el estado al que entra el sistema después del evento.
- Verifique si el problema ocurre de forma consistente o solo bajo condiciones específicas (por ejemplo, valores de datos específicos).
2. Rastree la ruta de ejecución
Utilice mecanismos de registro para rastrear la ruta de ejecución. Cada transición debe registrarse con el contexto relevante.
- Registro de entrada/salida:Registre cuándo se entra y se sale de un estado.
- Registro de transiciones:Registre el evento que desencadenó la transición.
- Evaluación de condiciones de guarda:Registre si las condiciones de guarda pasaron o fallaron y por qué.
- Registro de acciones: Registre cuando se ejecutan las acciones y su salida.
Esta data crea una cronología de eventos. Compare esta cronología con el diagrama de estados. Busque discrepancias donde el código se desvíe del diseño.
3. Analice las condiciones de guarda
Las condiciones de guarda son fuentes frecuentes de errores lógicos. Una transición podría parecer disponible en el diagrama, pero una condición oculta la impide dispararse.
- Revise todas las condiciones de guarda asociadas con la transición problemática.
- Verifique que las variables utilizadas en la condición de guarda coincidan con los datos disponibles en el momento del evento.
- Verifique efectos secundarios en la evaluación de la condición de guarda que podrían alterar el estado inesperadamente.
- Asegúrese de que las condiciones de guarda no sean demasiado restrictivas, bloqueando transiciones válidas.
4. Valide el manejo de eventos
Los eventos son los catalizadores del cambio. Si un evento no se maneja correctamente, el sistema podría ignorarlo o manejarlo en el estado incorrecto.
- Verifique si el nombre del evento coincide exactamente entre la fuente y la máquina de estados.
- Verifique que el evento se envíe a la instancia correcta de la máquina de estados.
- Asegúrese de que el evento no sea consumido por un estado padre cuando debería ser manejado por un estado hijo.
- Confirme que la cola de eventos procese los eventos en el orden esperado.
🔄 Manejo de concurrencia y estados paralelos
Las máquinas de estados avanzadas a menudo utilizan estados concurrentes. Esto permite que múltiples máquinas de estados independientes se ejecuten simultáneamente dentro de un estado compuesto. Aunque potentes, esto introduce complejidad en cuanto a sincronización y compartición de datos.
1. Puntos de sincronización
En entornos concurrentes, las transiciones deben sincronizarse para evitar condiciones de carrera. Una transición en un estado paralelo podría depender de la finalización de una transición en otro.
- Defina barreras de sincronización claras donde los estados paralelos deben alinearse.
- Utilice banderas o variables de estado para indicar la preparación de las ramas paralelas.
- Asegúrese de que los estados finales en las ramas paralelas se alcancen antes de que el estado compuesto finalice.
2. Integridad de los datos compartidos
Los estados paralelos a menudo acceden a recursos compartidos. Si dos estados modifican los mismos datos simultáneamente, puede ocurrir corrupción.
- Implemente mecanismos de bloqueo al acceder a variables de estado compartidas.
- Utilice estructuras de datos inmutables siempre que sea posible para evitar modificaciones accidentales.
- Revise todas las funciones de acción para determinar si modifican el estado global o compartido.
🛡️ Técnicas de verificación y validación
Depurar es reactivo; la verificación es proactiva. Implementar estrategias para validar la máquina de estados antes de la implementación reduce la carga de depuración.
1. Análisis estático
Las herramientas de análisis estático pueden escanear la definición del diagrama de estados sin ejecutar el código. Pueden identificar problemas estructurales.
- Verifique los estados inalcanzables.
- Identifique las transiciones que no pueden ser activadas por ningún evento.
- Verifique que todos los estados tengan rutas de salida válidas.
- Asegúrese de que todos los eventos sean manejados (sin errores de eventos no manejados).
2. Verificación de modelos
La verificación de modelos implica verificar matemáticamente que la máquina de estados satisfaga propiedades específicas. Esto es especialmente útil para sistemas críticos para la seguridad.
- Defina propiedades como «el sistema nunca entra en un estado de bloqueo».
- Ejecute algoritmos para verificar estas propiedades frente al grafo de transición de estados.
- Utilice estas herramientas para validar escenarios complejos de concurrencia.
3. Pruebas unitarias para máquinas de estados
Cada estado y transición debe probarse de forma independiente cuando sea posible.
- Escriba pruebas que coloquen al sistema en un estado específico y desencadenen un evento específico.
- Asegúrese de que el sistema pase al siguiente estado correcto.
- Asegúrese de que se activen las acciones esperadas.
- Pruebe condiciones límite, como disparar un evento en un estado donde no debería permitirse.
📝 Documentación para mantenimiento futuro
Una máquina de estados difícil de entender es difícil de depurar. Una documentación clara garantiza que los ingenieros futuros puedan solucionar problemas de forma efectiva sin tener que invertir la lógica.
- Comente el código:Agregue comentarios en línea que expliquen transiciones complejas o condiciones de guarda poco obvias.
- Mantenga los diagramas:Mantenga los diagramas visuales de estados sincronizados con el código. Un diagrama desactualizado es una carga.
- Documente casos extremos:Registre limitaciones conocidas o escenarios específicos que la máquina maneja de forma diferente.
- Control de versiones:Trate las definiciones de estados como código. Utilice el control de versiones para rastrear los cambios en la lógica con el tiempo.
⚙️ Escenario del mundo real: El flujo de procesamiento de pagos
Considere un sistema de procesamiento de pagos. La máquina de estados gestiona el ciclo de vida de una transacción:Iniciado, Autorizado, Liquidado, o Fallido.
Imagina un escenario en el que una transacción ingresa al estado de Liquidado estado, pero la base de datos indica que aún está Autorizado. Este es un error clásico de inconsistencia de estado.
- Diagnóstico: La transición desde Autorizado hasta Liquidado fue activada, pero la lógica de actualización de estado falló al confirmar el cambio en el almacenamiento permanente.
- Impacto: El usuario ve éxito, pero el backend espera que los fondos estén reservados.
- Solución: Implementa un envoltorio de transacción que garantice que la actualización de estado y la confirmación en la base de datos ocurran de forma atómica.
- Prevención: Agrega un trabajo de reconciliación que verifique periódicamente el estado de la máquina de estados frente al estado de la base de datos.
🔧 Herramientas avanzadas de depuración
Aunque el rastreo manual es efectivo, ciertas herramientas pueden acelerar el proceso de depuración.
- Visualizadores interactivos de estado: Herramientas que te permiten avanzar paso a paso por los estados visualmente en tiempo real.
- Agregadores de registros: Sistemas centralizados de registro que permiten filtrar por ID de estado o tipo de evento.
- Protocolos de depuración: Interfaces que permiten a los sistemas externos consultar el estado actual de la máquina sin reiniciarla.
- Entornos de simulación:Áreas de pruebas donde puedes reproducir secuencias de eventos para reproducir errores de forma segura.
🧠 Carga cognitiva y complejidad del estado
A medida que aumenta el número de estados, la carga cognitiva necesaria para mantener la lógica crece exponencialmente. Esto se conoce como el problema de explosión de estados.
- Modulariza:Divide las máquinas de estado grandes en submáquinas más pequeñas y manejables.
- Abstrae:Utiliza estados compuestos para ocultar la complejidad de la lógica de nivel superior.
- Limita:Limita estrictamente el número de estados concurrentes para reducir la sobrecarga de sincronización.
- Refactoriza:Revisa periódicamente el diagrama de estados para identificar estados redundantes o superpuestos.
🛑 Manejo de entradas inesperadas
Los sistemas robustos deben manejar entradas que no están definidas en el diagrama de estados. Esto a menudo se conoce como el “Estado de error”.
- Transiciones predeterminadas:Define una transición general para eventos que ocurren en estados inesperados.
- Registro:Registra eventos inesperados con alta severidad para alertar a los desarrolladores.
- Recuperación:Asegúrate de que el sistema pueda recuperarse de un estado de error, en lugar de fallar.
- Notificación:Notifica al usuario o al sistema de monitoreo cuando ocurre un evento inesperado.
📊 Métricas para la salud de la máquina de estados
Para mantener un sistema saludable, rastrea métricas específicas relacionadas con la máquina de estados.
- Frecuencia de transición:Con qué frecuencia ocurren transiciones específicas. Cambios bruscos podrían indicar un error.
- Duración del estado:Durante cuánto tiempo el sistema permanece en un estado específico. Duraciones largas podrían indicar un cuello de botella.
- Tasa de errores: El porcentaje de eventos que provocan transiciones de error.
- Contador de bloqueos: El número de veces que el sistema entra en un estado sin transiciones salientes.
🚀 Conclusión sobre la integridad del sistema
Mantener la integridad de una máquina de estados es un proceso continuo. Requiere vigilancia, documentación clara y una comprensión profunda del flujo lógico. Al seguir las metodologías descritas anteriormente, los ingenieros pueden depurar eficazmente errores lógicos y garantizar que los sistemas complejos se comporten de manera predecible.
Recuerda que el objetivo no es solo corregir el error inmediato, sino mejorar la robustez general de la arquitectura. Una máquina de estados bien diseñada es auto-documentada y resistente al cambio. Invierte tiempo en la fase de diseño para reducir el costo de depuración más adelante.
Aplica estos principios de forma consistente. Revisa tus diagramas con regularidad. Prueba tus transiciones exhaustivamente. Con disciplina, puedes gestionar la complejidad y entregar software estable y confiable.