











Diseñar una máquina de estados robusta es una de las tareas más críticas en la arquitectura de sistemas. Cuando se implementa correctamente, los diagramas de estado proporcionan claridad, previsibilidad y mantenibilidad. Sin embargo, cuando la lógica está defectuosa, el sistema puede entrar en un estado en el que no es posible ningún avance posterior. Esto se conoce como un deadlock. En un diagrama de máquina de estados, un deadlock ocurre cuando el sistema alcanza un estado desde el cual no existe ninguna transición válida, deteniendo la ejecución indefinidamente. ⏸️
Esta guía explora la mecánica del diseño de máquinas de estados, centrándose específicamente en la identificación y prevención de deadlocks. Cubriremos las guardas de transición, las acciones de entrada y salida, las regiones concurrentes y las estrategias de validación. Siguiendo estos enfoques estructurados, puedes asegurarte de que tus diagramas de estado permanezcan resilientes ante diversas condiciones. 🔒
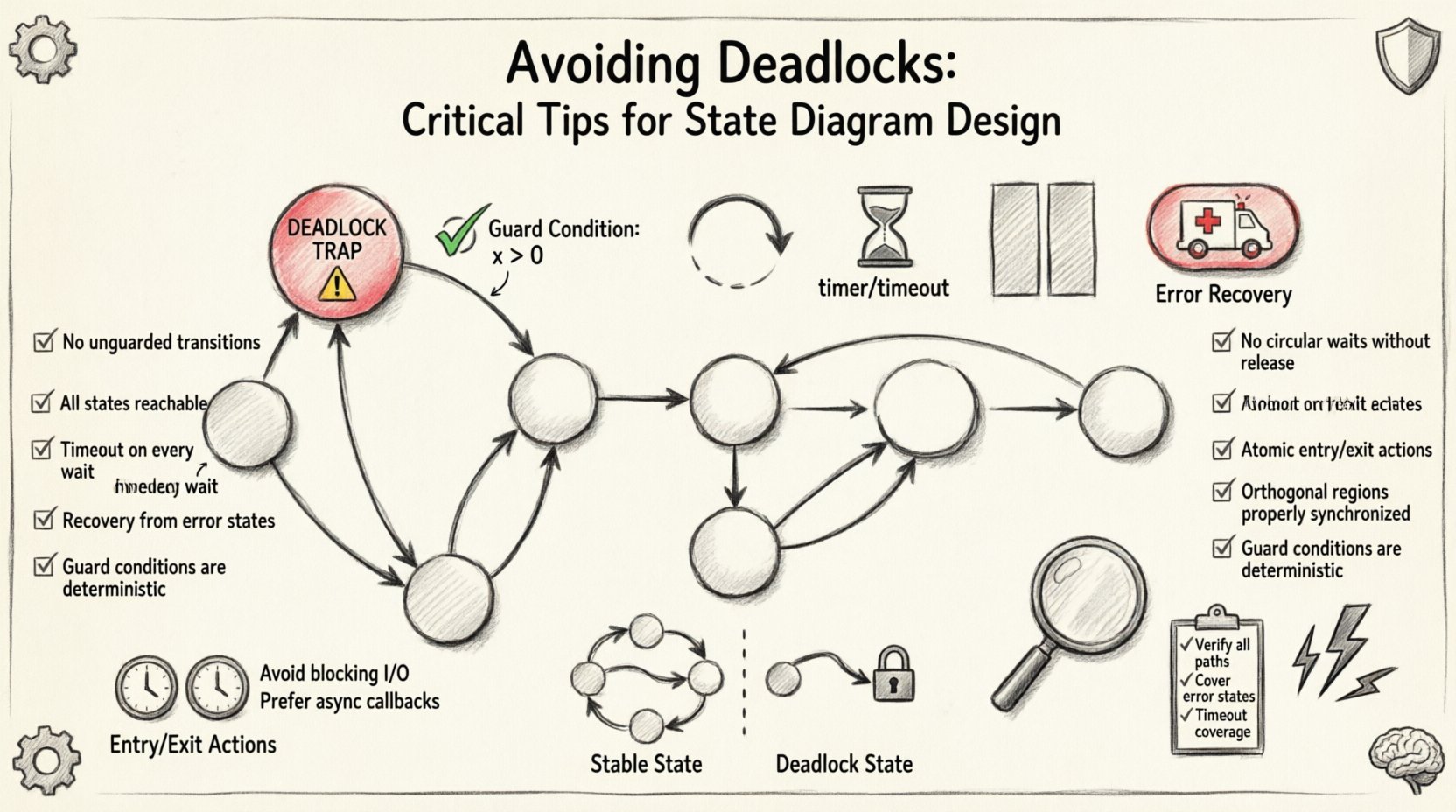
🧠 Comprender los deadlocks en máquinas de estados
Un deadlock en una máquina de estados finita (FSM) representa una interrupción lógica. A diferencia de un error en tiempo de ejecución que podría hacer que la aplicación se bloquee, un deadlock a menudo hace que el sistema parezca congelarse mientras sigue funcionando. El motor está activo, pero no puede ejecutar ningún comando porque el estado actual carece de transiciones salientes que satisfagan las condiciones de activación. 🔍
Para diseñar de forma efectiva, uno debe comprender la anatomía de un escenario de deadlock. Rara vez se debe a una sola línea de código faltante. En cambio, a menudo es el resultado de interacciones complejas entre múltiples estados, guardas y eventos externos. A continuación se presentan las características principales de un estado de deadlock:
- Sin transiciones salientes: El estado no tiene flechas que salgan de él.
- Transiciones inalcanzables: Todas las flechas salientes tienen condiciones de guarda que nunca pueden ser verdaderas dada la información actual.
- Faltan rutas por defecto: No existe una transición de respaldo para manejar entradas inesperadas.
- Retención de recursos: El sistema retiene un recurso (como un bloqueo o conexión) pero espera por otra condición que nunca ocurrirá.
Prevenir estos escenarios requiere una filosofía de diseño proactiva en lugar de una depuración reactiva. Examinemos los causas raíz en detalle. 📉
⚠️ Causas comunes de deadlocks en el diseño de estados
Los deadlocks no son accidentes aleatorios; son resultados predecibles de decisiones de diseño específicas. Comprender estos patrones te ayuda a evitarlos antes de que afecten la producción. A continuación se presentan los principales culpables detrás del bloqueo de la máquina de estados.
1. Guardas de transición faltantes
Al diseñar transiciones, cada flecha que sale de un estado representa una posible ruta hacia adelante. Si un estado tiene múltiples entradas posibles (eventos), pero solo algunas están asignadas a transiciones, el sistema se detiene cuando ocurre un evento no asignado. Esto a menudo se conoce como un estado de “trampa”. ❌
- El problema: Una máquina de estados espera desencadenantes específicos. Si llega un desencadenante inesperado y ninguna transición lo maneja, el sistema permanece en el mismo estado.
- La solución: Asegúrate de que cada estado tenga en cuenta todos los eventos definidos, o implementa un manejador predeterminado global para capturar entradas inesperadas.
2. Condiciones de guarda conflictivas
Las condiciones de guarda son expresiones booleanas que deben evaluarse como verdaderas para que una transición se active. Un error común ocurre cuando dos transiciones comparten el mismo estado de origen y evento, pero sus condiciones de guarda son mutuamente excluyentes o no cubren ninguna situación posible. 🧩
- El problema: Definiste la transición A (si la puntuación > 10) y la transición B (si la puntuación < 5). ¿Qué ocurre si la puntuación es exactamente 10? Si la lógica es estricta, podría fallar ambas.
- La solución: Revisa las condiciones de guarda para casos límite. Asegúrate de que la unión de todas las condiciones de guarda para un evento específico cubra todo el dominio de entrada.
3. Dependencias circulares
En sistemas complejos, los estados pueden depender del estado de otros estados o de procesos externos. Si el Estado A espera a que el Estado B finalice, y el Estado B espera que el Estado A reconozca, ninguno avanza. Esto es un clásico bloqueo de sincronización. ⏳
- El problema:La lógica está entrelazada de tal manera que requiere un reconocimiento mutuo antes de avanzar.
- La solución:Rompe el ciclo introduciendo temporizadores o permitiendo que un proceso continúe sin la confirmación inmediata del otro.
4. Manejo incorrecto de los estados de historia
Los estados de historia permiten que un sistema recuerde su estado anterior al reingresar. Si no se implementan correctamente, un estado de historia puede apuntar a un estado que ya no es válido o ha sido eliminado. 🔄
- El problema:La máquina intenta transicionar a un estado histórico que ya no existe o es inaccesible.
- La solución:Valide que los destinos históricos sigan activos cuando la máquina se reinicie o se reinicie.
🛡️ Patrones de diseño para prevenir bloqueos
Una vez que comprendas los riesgos, puedes aplicar patrones específicos para mitigarlos. Estos patrones no son específicos de software; se aplican a cualquier lenguaje de modelado o marco de implementación. 🛠️
1. El patrón de estado predeterminado
Cada máquina de estados debe tener un punto de entrada definido. Este suele ser el estado inicial. Sin embargo, más allá del estado inicial, cada uno de los demás estados debería tener idealmente una ruta predeterminada. Si un evento no coincide con una condición específica, el sistema debería volver a un comportamiento predeterminado seguro. 📍
- Implementación:Cree una transición de tipo «captura todo» para cada estado que maneje los eventos desconocidos de forma adecuada.
- Beneficio:Evita que el sistema entre en un estado indefinido cuando ocurre una entrada inesperada.
2. El patrón de guardia de tiempo de espera
A veces, un estado debe esperar un evento externo que podría nunca ocurrir. Para evitar una espera indefinida, puedes introducir un temporizador. Si el evento no llega dentro de una duración especificada, se activa una transición de tiempo de espera. ⏱️
- Implementación:Agregue una transición desencadenada por un evento basado en el tiempo (por ejemplo, «Temporizador expirado»).
- Beneficio:Garantiza que el sistema siempre avance, incluso si no se cumple la condición principal.
3. El patrón de estado paralelo
En flujos de trabajo complejos, un solo estado no puede capturar todas las actividades concurrentes. Las regiones ortogonales permiten dividir un estado en múltiples subestados independientes. Esto reduce la complejidad de las guardas de transición. ⚡
- Implementación:Utilice estados compuestos con múltiples regiones que se ejecuten simultáneamente.
- Beneficio:Simplifica la lógica separando las responsabilidades. Si una región entra en un estado de interbloqueo, la otra aún puede funcionar o informar del error.
4. El estado de recuperación de errores
Diseñe un estado específico dedicado al manejo de errores. Si el sistema detecta una anomalía, pasa inmediatamente a este estado. Desde aquí, puede intentar reiniciar, volver a intentarlo o alertar a un operador. 🚑
- Implementación:Agregue un estado dedicado de “Error” o “Recuperación” accesible desde múltiples puntos.
- Beneficio:Aisla el fallo y proporciona una ruta clara para la recuperación, en lugar de dejar al sistema en un estado dañado.
📊 Comparación: Interbloqueo frente a estado estable
Para visualizar la diferencia entre un estado saludable y un interbloqueo, considere la siguiente tabla de comparación. Esto destaca las diferencias estructurales en el diseño.
| Característica | Estado estable | Estado de interbloqueo |
|---|---|---|
| Transiciones | Existe al menos una transición saliente válida. | Ninguna transición saliente satisface las condiciones actuales. |
| Lógica de guardia | Las guardias cubren todos los escenarios de entrada relevantes. | Las guardias son mutuamente excluyentes o incompletas. |
| Manejo de eventos | Los eventos desencadenan acciones esperadas. | Los eventos son ignorados o provocan una detención. |
| Recuperación | El sistema se corrige automáticamente o pasa a la siguiente fase. | El sistema requiere una intervención externa para reiniciarse. |
🧪 Estrategias de validación y pruebas
Diseñar es solo la mitad de la batalla. Debe validar el diagrama para asegurarse de que resista la presión. Probar máquinas de estado requiere un enfoque diferente al de probar funciones estándar. 🧪
1. Verificación de modelos
La verificación de modelos es un método de verificación formal. Prueba matemáticamente que una máquina de estados satisface ciertas propiedades, como “ningún estado es alcanzable donde exista un interbloqueo”. Esto es altamente efectivo para sistemas críticos. 🔢
- Técnica:Utilice herramientas de métodos formales para recorrer todo el espacio de estados.
- Resultado: Una garantía matemática de que el sistema no puede entrar en un estado de interbloqueo.
2. Pruebas de cobertura de estados
Asegúrese de que cada estado y cada transición se prueben al menos una vez. Esto se conoce como cobertura de estados. Si un estado no se prueba, no podrá saber si contiene una condición de interbloqueo oculta. 🎯
- Técnica:Escriba casos de prueba que obliguen al sistema a entrar en cada estado definido.
- Resultado:Verificación de que las transiciones se activan correctamente desde cada punto de entrada.
3. Pruebas de estrés de entradas
Envíe entradas inválidas, nulas o inesperadas al sistema. Una máquina de estados robusta no debería colapsar ni quedar bloqueada al recibir datos incorrectos. Debería rechazar la entrada o transicionar a un estado seguro. 🌪️
- Técnica:Genere entradas aleatorias o de límite y observe el comportamiento.
- Resultado:Identificación de casos límite que conducen a interbloqueos.
4. Análisis estático
Antes de ejecutar el código, analice la estructura del diagrama. Busque estados sin flechas salientes. Busque bucles que nunca terminen. Las herramientas a menudo pueden detectar estos patrones automáticamente. 🔎
- Técnica:Ejecute scripts de revisión o análisis estático en los archivos de definición de estados.
- Resultado:Detección temprana de errores estructurales.
🔄 Manejo de concurrencia y estados paralelos
La concurrencia añade complejidad. Cuando múltiples regiones operan simultáneamente, los interbloqueos pueden surgir por problemas de sincronización. Debe asegurarse de que los caminos paralelos no se bloquen entre sí. 🏗️
1. Regiones independientes
Asegúrese de que los estados paralelos sean verdaderamente independientes. Si el Estado A en la Región 1 necesita datos del Estado B en la Región 2, introduce una dependencia. Esta dependencia puede convertirse en un cuello de botella. 🚧
- Mejor práctica:Minimice el intercambio de datos entre regiones ortogonales.
- Alternativa:Utilice un bus de eventos para comunicarse entre regiones sin bloqueo directo.
2. Puntos de sincronización
A veces, los estados deben sincronizarse. Por ejemplo, la Región A debe finalizar antes de que la Región B comience. Si lo implementa manualmente, corre el riesgo de interbloqueo. Utilice constructos de sincronización integrados proporcionados por su marco. ⚙️
- Mejor práctica:Evite los mecanismos de bloqueo manual a menos que sea absolutamente necesario.
- Alternativa:Utilice estados de unión que esperen a que todas las rutas entrantes finalicen de forma natural.
⚙️ Acciones de entrada y salida
Las acciones de entrada y salida son fragmentos de código que se ejecutan al entrar o salir de un estado. Estas son fuentes comunes de bloqueos sutiles. ⚠️
1. Acciones de entrada bloqueantes
Si una acción de entrada realiza una tarea de larga duración (como una solicitud de red) sin un tiempo de espera, el sistema no puede salir de ese estado hasta que la tarea finalice. Si la tarea se queda colgada, la máquina de estados se queda colgada. 🕸️
- Mejor práctica:Mantenga las acciones de entrada ligeras y no bloqueantes.
- Alternativa:Reasigne las tareas pesadas a trabajadores en segundo plano y cambie al estado de “Procesamiento”.
2. Bucles infinitos en acciones de salida
Una acción de salida nunca debe desencadenar una transición que lleve de inmediato al mismo estado. Esto crea un bucle que consume recursos sin progreso. 🔄
- Mejor práctica:Asegúrese de que las acciones de salida no vuelvan a activar la misma transición de estado.
- Alternativa:Utilice marcas para evitar la activación recursiva de acciones.
📝 Lista de verificación para diagramas de estado
Antes de implementar una máquina de estados, revise esta lista. Cubre las áreas críticas donde los bloqueos suelen ocultarse. ✅
| Elemento de verificación | Aprobado / Fallido | Notas |
|---|---|---|
| ¿Son todos los estados alcanzables desde el estado inicial? | ||
| ¿Tiene cada estado al menos una transición saliente? | ||
| ¿Son todas las condiciones de guardia lógicamente sólidas (sin brechas)? | ||
| ¿Existen mecanismos de tiempo de espera para los estados de espera? | ||
| ¿Las regiones paralelas evitan dependencias directas de datos? | ||
| ¿Existe un estado de recuperación de errores global? | ||
| ¿Han sido probadas las acciones de entrada en busca de comportamientos bloqueantes? |
🔍 Análisis profundo: Escenarios de casos extremos
Aunque se cuente con un buen diseño, los casos extremos pueden pasar desapercibidos. Aquí tienes escenarios específicos en los que los bloqueos a menudo se manifiestan en entornos de producción. 🌐
1. La trampa de la condición de carrera
Cuando dos eventos ocurren simultáneamente, el orden de procesamiento importa. Si la máquina de estados procesa el Evento A antes que el Evento B, podría tomar un camino que provoque un bloqueo. Si procesa B antes que A, podría tener éxito. ⚡
- Mitigación:Coloque los eventos en una cola y proceselos de forma secuencial. Asegúrese de que el orden de los eventos no afecte la validez del estado final.
2. La trampa de agotamiento de recursos
Un estado podría esperar un recurso (como una conexión a la base de datos). Si el grupo está agotado, la espera es infinita. Esto parece un bloqueo, pero en realidad es un problema de recursos. 💾
- Mitigación:Implemente tiempos de espera para conexiones y estados de respaldo que reduzcan la funcionalidad de forma gradual.
3. La trampa de desviación de configuración
El diagrama podría estar diseñado para el Estado A, pero el archivo de configuración especifica el Estado B. Si la lógica de transición depende de valores de configuración que faltan, el sistema se detiene. 📄
- Mitigación:Valide la configuración contra el esquema del diagrama de estados al iniciar.
🚀 Consideraciones finales para un diseño robusto
Construir una máquina de estados que resista los bloqueos se trata de disciplina. Requiere anticipar los modos de fallo y diseñar rutas alrededor de ellos. Al centrarse en transiciones claras, lógica de guardia completa y manejo robusto de errores, se crean sistemas resilientes al cambio. 🛡️
Recuerde que los diagramas de estados son documentos vivos. A medida que cambian los requisitos, el diagrama debe evolucionar. Las revisiones y sesiones de refactorización regulares aseguran que las nuevas características no introduzcan errores antiguos. Mantenga el modelo simple, mantenga la lógica explícita y mantenga los caminos de recuperación claros. 🔄
Cuando prioriza la estabilidad sobre la velocidad en la fase de diseño, ahorra tiempo significativo en el mantenimiento posterior. Una máquina de estados bien diseñada es la columna vertebral del comportamiento confiable del software. Invierta el esfuerzo en el diseño, y el sistema funcionará de forma consistente. 📈