











Los sistemas distribuidos dependen en gran medida del movimiento de información entre componentes aislados. Al construir microservicios, la arquitectura no se trata solo de separar el código; se trata de orquestar cómo los datos viajan a través de una red. Comprender la lógica de flujo de datos es esencial para mantener la integridad del sistema, el rendimiento y la confiabilidad. Sin un mapa claro de dónde proviene la información, dónde se transforma y dónde se almacena, los sistemas se vuelven opacos y difíciles de depurar.
Esta guía explora la metodología para mapear estos flujos. Analizaremos los componentes estructurales, la lógica detrás del movimiento de datos y los patrones que rigen la comunicación entre servicios. El objetivo es crear una arquitectura transparente en la que cada transacción esté debidamente registrada.
Entendiendo la arquitectura 🏗️
La arquitectura de microservicios descompone una aplicación monolítica en unidades más pequeñas e independientes. Cada unidad gestiona una capacidad empresarial específica. Sin embargo, esta independencia introduce complejidad en cuanto a la gestión del estado y la comunicación. Los datos no existen en el vacío; se mueven.
Cuando mapeas estos servicios, estás esencialmente dibujando un plano de sistema de su sistema nervioso. Debes identificar los productores de datos y los consumidores. Debes comprender los protocolos utilizados para la transmisión. ¿Los servicios se comunican directamente mediante HTTP? ¿Utilizan una cola de mensajes? ¿Acceden a una base de datos compartida?
La claridad en esta área previene el acoplamiento. Si el Servicio A depende del Servicio B para funcionar, esa dependencia debe ser explícita en tus mapas. Las dependencias ocultas provocan fallos en cadena. Al visualizar el flujo, puedes identificar cuellos de botella antes de que afecten el rendimiento en producción.
Principales motivadores para el mapeo
- Observabilidad:No puedes depurar lo que no puedes ver. Un mapa claro ayuda a rastrear las solicitudes en el entorno distribuido.
- Seguridad:Comprender el flujo de datos te permite aplicar cifrado y controles de acceso en los límites adecuados.
- Rendimiento:Identificar rutas con alta latencia ayuda a optimizar las llamadas de red y las consultas a la base de datos.
- Cumplimiento:Las regulaciones suelen exigir conocer dónde reside la información sensible y cómo se mueve.
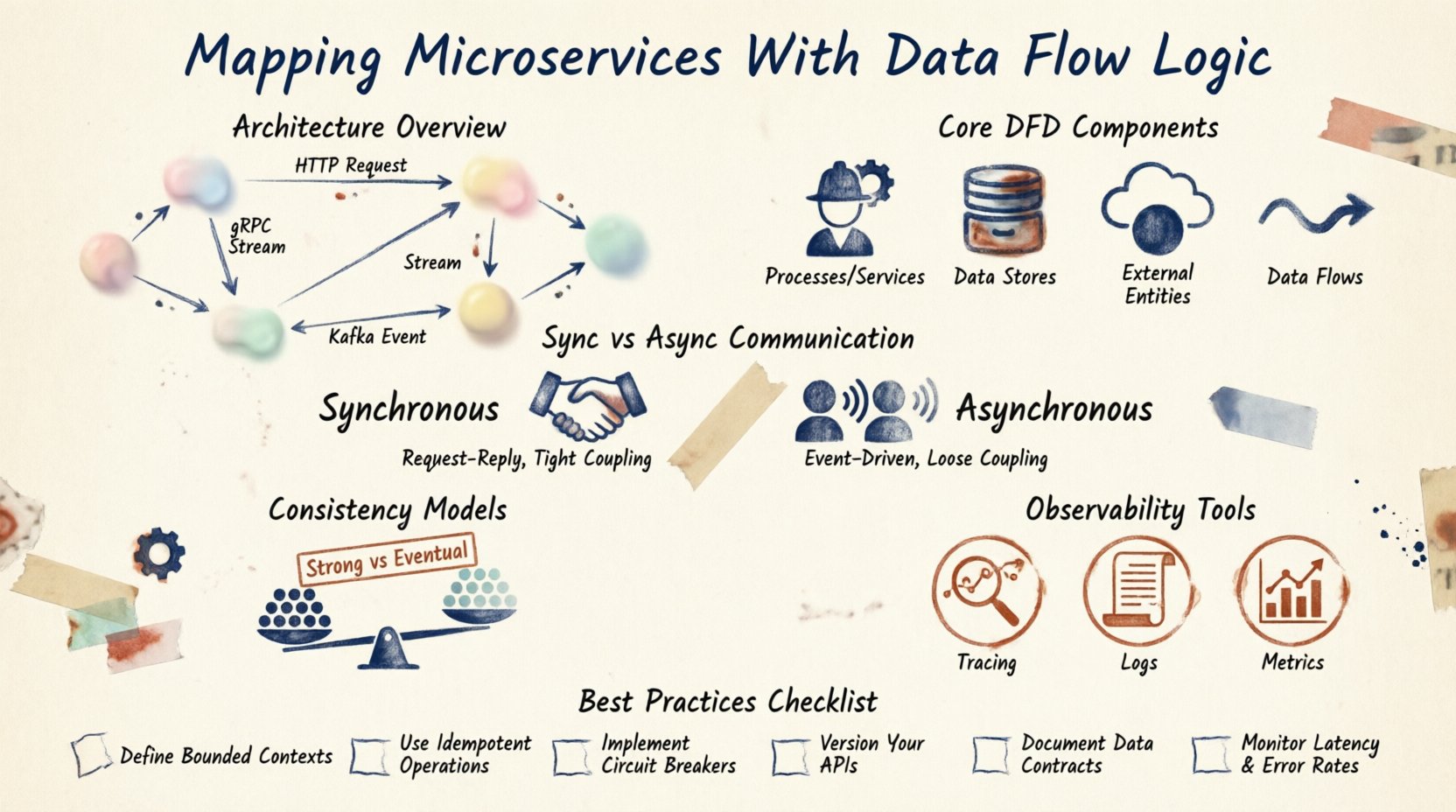
Componentes principales de los diagramas de flujo de datos 📊
Un diagrama de flujo de datos (DFD) proporciona una forma estandarizada de representar estas interacciones. En el contexto de microservicios, los componentes son ligeramente diferentes a los de los DFD tradicionales de ingeniería de software.
1. Procesos (servicios)
Estos son los elementos activos. Cada microservicio representa un proceso que transforma datos de entrada en datos de salida. Por ejemplo, un servicio de pedidos recibe los detalles del pedido y los transforma en una reserva de inventario.
2. Almacenes de datos
Los datos no siempre permanecen en la memoria. A menudo persisten en bases de datos, cachés o almacenamiento de objetos. En un entorno de microservicios, los servicios suelen tener almacenes de datos privados. Esto garantiza un acoplamiento débil. Si cambia el esquema de la base de datos, solo el servicio propietario necesita adaptarse.
3. Entidades externas
Estos son actores fuera del sistema. Podrían ser una pasarela de pago de terceros, una aplicación móvil o un usuario. Inician solicitudes o reciben notificaciones. Mapear estas fronteras es crucial para el diseño de la puerta de enlace de API.
4. Flujos de datos
Estos son los arcos que conectan los componentes. Representan el movimiento de información. Cada flujo debe tener una etiqueta que describa los datos que se transfieren. ¿Es una carga útil JSON? ¿Es un archivo binario? ¿Es una notificación de evento?
Proceso paso a paso de mapeo 🗺️
Crear un mapa es un ejercicio sistemático. Requiere descomponer el sistema capa a capa. A continuación se presenta un enfoque lógico para construir estos diagramas.
- Identifica el límite: Define qué está dentro del sistema y qué está fuera. Esto establece el alcance de tu diagrama.
- Lista los servicios: Enumera cada microservicio involucrado en el proceso empresarial específico que estás analizando.
- Define los puntos de entrada de datos: ¿Dónde entra los datos en el sistema? ¿Es un punto de acceso de API? ¿Un trabajo programado? ¿Un consumidor de cola de mensajes?
- Rastrea el camino:Sigue un solo fragmento de datos desde su entrada hasta su salida. Anota cada servicio que toca.
- Identifica el almacenamiento:Marca dónde se lee o escribe los datos en cada paso.
- Valida la lógica:Revisa el mapa con el equipo de desarrollo para asegurarte de que coincide con la implementación real.
Patrones de comunicación 📡
Cómo los servicios se comunican entre sí determina la lógica de flujo. Hay dos modos principales: síncrono y asíncrono.
Comunicación síncrona
El servicio A llama al servicio B y espera una respuesta. Esto suele implementarse mediante REST o gRPC. Proporciona retroalimentación inmediata, pero crea acoplamiento estrecho. Si el servicio B es lento, el servicio A se queda esperando.
Comunicación asíncrona
El servicio A envía un mensaje y continúa trabajando. El servicio B lo recoge cuando está listo. Esto utiliza brokers de mensajes o flujos de eventos. Mejora la resiliencia, pero dificulta el seguimiento del estado.
| Aspecto | Síncrono | Asíncrono |
|---|---|---|
| Latencia | Más alta (bloqueante) | Más baja (no bloqueante) |
| Acoplamiento | Estrecho | Débil |
| Complejidad | Fácil de rastrear | Requiere almacenamiento de eventos |
| Manejo de fallos | Reintentar inmediatamente | Colas de mensajes muertos |
Modelos de consistencia 🤝
En un sistema distribuido, la consistencia de los datos es una preocupación principal. No puedes confiar en una única transacción a través de múltiples bases de datos. Debes decidir un modelo de consistencia.
Consistencia fuerte
Cada lectura recibe la escritura más reciente. Es difícil lograrlo entre microservicios sin bloquear. A menudo requiere mecanismos de bloqueo distribuido.
Consistencia eventual
Los datos serán consistentes después de un tiempo. Las actualizaciones se propagan de forma asíncrona. Este es el estándar para la mayoría de los microservicios. Permite alta disponibilidad, pero requiere que la aplicación maneje las inconsistencias temporales de los datos.
Observabilidad y rastreo 🔍
Una vez que se dibuja el mapa, necesitas herramientas para monitorearlo. El rastreo distribuido te permite seguir un ID de solicitud a través de cada servicio. Esto es vital para depurar.
Los registros deben estar correlacionados. Si una solicitud falla, los registros del Gateway, del Servicio de Pedidos y del Servicio de Pagos deben estar vinculados. Esta conexión es el gemelo digital de tu Diagrama de Flujo de Datos.
Las métricas también forman parte del flujo. Debes rastrear el volumen de mensajes, la latencia de las llamadas y las tasas de errores. Estas métricas validan la salud de los caminos de datos que has diseñado.
Mejores prácticas para el mantenimiento 🛠️
Un diagrama solo es útil si permanece preciso. Los sistemas evolucionan, y el mapa debe evolucionar con ellos.
- Automatizar la generación: Cuando sea posible, genera diagramas a partir del código o de la infraestructura como código. Esto reduce los errores manuales.
- Control de versiones: Almacena tus diagramas en el mismo repositorio que tu código. Revisa los diagramas durante las solicitudes de fusión.
- Revisiones regulares: Programa revisiones trimestrales para asegurarte de que el mapa coincida con el sistema en funcionamiento.
- Documentar protocolos: Define claramente los formatos de datos. Usa esquemas para imponer una estructura entre los servicios.
Desafíos en los flujos distribuidos ⚠️
Mapear estos sistemas no está exento de dificultades. Las redes fallan. Los servicios se reinician. Se pierde datos.
Latencia de red: La distancia física entre servicios puede afectar el rendimiento. Debes tener en cuenta esto en tu lógica de temporización.
Fragmentación de datos: Los datos están distribuidos en muchos almacenes. Reconstruir una vista completa de una entidad requiere unir datos de fuentes diferentes. Esto añade complejidad a las consultas.
Orquestación frente a coreografía: Debes decidir quién controla el flujo. La orquestación utiliza un coordinador central. La coreografía depende de eventos. Ambas tienen compromisos en cuanto a visibilidad y control.
Diseño resistente al futuro 🔮
La tecnología cambia. Los protocolos evolucionan. Tu mapa debe ser lo suficientemente abstracto para sobrevivir a estos cambios.
Enfócate en la lógica del negocio, no en los detalles de implementación. Describe qué significa los datos, no solo cómo están codificados. Esta abstracción te permite cambiar las tecnologías subyacentes sin volver a escribir toda la arquitectura.
Considera la escalabilidad. ¿El flujo puede manejar diez veces la carga? ¿El mapa muestra dónde podrían ocurrir cuellos de botella? Diseña para el crecimiento desde el principio.
Pensamientos finales sobre la lógica de datos
Mapear microservicios con lógica de flujo de datos es una habilidad fundamental para arquitectos. Trasladar la conversación desde código abstracto hasta movimiento concreto. Al visualizar el flujo, los equipos pueden tomar mejores decisiones sobre resiliencia, seguridad y rendimiento.
Requiere disciplina mantener los mapas actualizados. Requiere colaboración para asegurarse de que todos entiendan los caminos. Pero el resultado es un sistema más fácil de construir, más fácil de depurar y más fácil de escalar. Los datos fluyen claramente, y el sistema permanece estable bajo presión.
Invierte el tiempo en estos diagramas. Sirven como documentación para el torrente vital de tu sistema. Cuando se apagan las luces en un servidor de producción, estos mapas son los que guían la recuperación.