











資料完整性依賴於可見性。若無法清楚掌握資訊在系統中如何流動,組織將處於盲目狀態。追蹤資料血統可提供這張地圖,記錄資料從起源到消費的完整旅程。資料流程圖作為此任務的基礎視覺語言,能將複雜的技術流程轉化為易於理解的結構,使團隊能精確追蹤資料的轉換與依賴關係。此方法確保每筆資料皆可追蹤,支援合規性、除錯與策略決策。
此過程不僅僅是簡單地在方框之間畫線。它需要深入理解基礎架構、驅動轉換的邏輯,以及所涉及的儲存機制。透過運用標準化的圖示技術,技術團隊可建立一份隨著基礎設施演進而持續更新的動態文件。本文概述透過流程圖實現血統追蹤的方法論,著重於清晰性、準確性與長期可維護性。
理解資料血統 🧬
資料血統指的是資料的歷史。它記錄資料在其生命周期中經歷的來源、移動與轉換過程。想像一滴水進入河川系統;血統追蹤這滴水的來源、經過的支流,以及最終流往何處。在數位環境中,這代表知道是哪個資料庫表格產生了記錄、哪段程式碼處理了它,以及哪個儀表板顯示了最終的指標。
建立血統至關重要,原因有三:首先,它有助於故障排除。當報告中的數字看似錯誤時,血統可讓工程師逆向追蹤數值,找出差異發生的位置。其次,它支援法規合規。關於資料隱私的法規通常要求組織明確知道個人資訊存放於何處,以及如何被使用。最後,它建立信任。當利益相關者理解數字背後的來源與處理邏輯時,他們更可能信任分析結果。
血統可分為兩種主要類型:邏輯血統與物理血統。邏輯血統描述資料的概念性移動,例如「客戶編號從銷售部門移至帳單部門」。物理血統則詳細說明具體的技術步驟,例如「從表格A的第5欄透過SQL查詢B提取至表格C的第3欄」。流程圖能有效連結這兩者,提供一份能同時滿足業務利益相關者與技術工程師的視覺化呈現。
資料流程圖的角色 📊
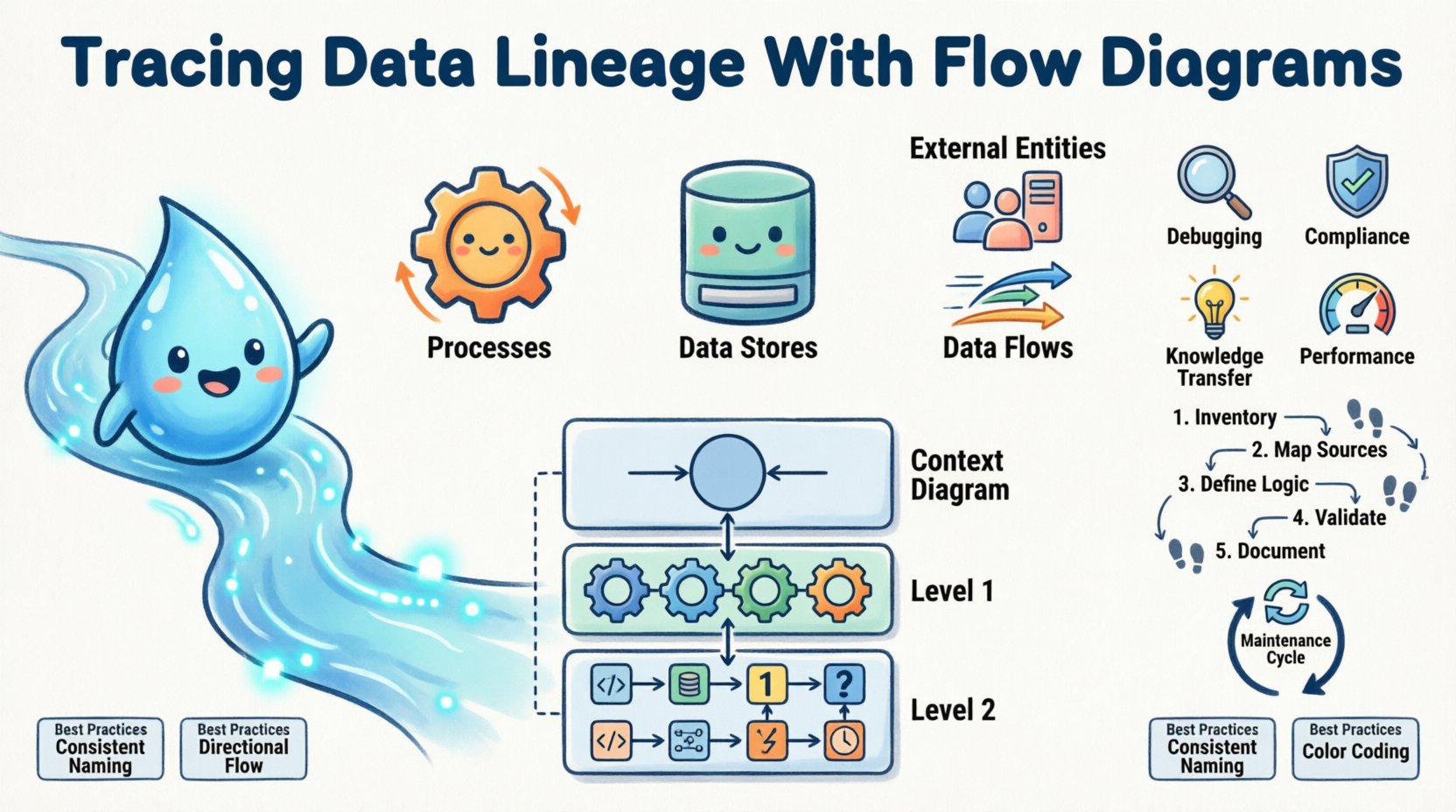
資料流程圖(DFD)是用來圖示資料在系統中如何流動的視覺化表示。與專注於資料物件之間靜態關係的實體關係圖不同,DFD強調資訊的動態流動與處理。它將複雜系統分解為可管理的元件,使其成為追蹤血統的理想工具。
標準的DFD包含四個核心元素:
- 流程:轉換資料的動作。通常以圓形或圓角矩形表示。例如「計算稅額」或「合併銷售資料」。
- 資料儲存:資料存放的位置。以開口的矩形表示,代表資料庫、檔案或佇列。
- 外部實體:系統邊界以外的來源或目的地。使用者、其他系統或法規機構通常屬於此類。
- 資料流: 連接各元件的箭頭,用以表示資料移動的方向與內容。
當用於血統追蹤時,這些元件會成為更大圖形中的節點。連結關係揭示了資料的路徑。透過遵循DFD標準,團隊可確保一致性。一個圖表中的流程遵循與另一個圖表中流程相同的視覺規則,降低任何審閱文件者的心智負擔。
圖表細節層級 🛠️
為管理複雜度,DFD通常以不同抽象層級建立。此層級結構使利益相關者能聚焦於特定區域,而不會被整個系統架構所壓垮。標準做法包含三個層級深度。
| 層級 | 描述 | 使用情境 |
|---|---|---|
| 上下文圖(第0層) | 高階概覽,將系統視為單一流程,並顯示其與外部實體的互動。 | 高階主管摘要與高階架構規劃。 |
| 第1層圖 | 將主要流程拆解為主要的子流程與資料儲存。 | 系統設計與識別主要資料接觸點。 |
| 第2層圖 | 進一步將第1層的特定流程拆解為詳細步驟。 | 技術實作、程式碼審查與詳細審計。 |
這種分層方法可避免圖表變得無法閱讀。若單一頁面顯示每一筆SQL連接與API呼叫,將會混亂不堪。相反地,上下文圖提供整體視角,而第2層圖則提供工程任務所需的細節層級。在追蹤血統時,經常需要跨層次比對。第2層圖中的查詢,可能在第1層圖中被簡化為單一流程。
實施血統追蹤的步驟 📝
建立精確的血統地圖需要系統性的方法。隨意繪製會導致不一致和遺漏的連結。以下步驟概述了一個穩健的工作流程,用於建立和維護資料血統的流程圖。
1. 記錄現有資產
繪製之前,你必須清楚現有的資產。整理一份所有相關資料庫、資料倉儲、應用伺服器和報表工具的清單。識別主要的資料來源,例如交易系統或外部 API。此清單構成了你圖表的邊界。若缺少完整的清單,血統圖將出現缺口,導致治理上的盲點。
2. 將資料來源對應至目的地
從來源開始。識別資料的初始進入點。向前追蹤至第一個處理步驟。記錄轉換邏輯。是否有腳本清理資料?是否有檢視過濾特定資料列?在流程層級記錄這些資訊。持續追蹤,直到達至最終目的地,例如商業智慧儀表板或歸檔儲存系統。
3. 定義轉換邏輯
資料很少保持靜態。它經常被聚合、合併或計算。這些轉換是血統中的關鍵節點。記錄所應用的具體規則。例如:「欄位 X 中的空值被替換為 0」或「時間戳記從 UTC 轉換為本地時間」。這種細節對於除錯至關重要。若下游報表顯示預期之外的值,了解轉換規則可讓你在測試環境中重現錯誤。
4. 與技術團隊共同驗證
單獨繪製的圖表容易出錯。與建置資料管道的工程師以及使用資料的分析師共同審查草圖。他們可以識別遺漏的步驟或錯誤的假設。這種協作確保圖表反映現實,而非僅僅理論設計。驗證是維持血統文件完整性的重要步驟。
5. 記錄元資料
將元資料附加至圖表元素上。這包括版本號、擁有者姓名和建立日期。資料流會隨時間變動。某個流程可能在下個季度被重構。元資料讓你可以追蹤圖表本身的歷史,確保你知道在特定審計期間,哪個版本的血統圖正在使用中。
結構化血統的優勢 🏗️
投入時間建立詳細的流程圖,能為整個組織帶來實質回報。其優勢不僅限於簡單的文件記錄。
- 減少除錯時間: 當錯誤發生時,工程師花費在尋找根本原因上的時間減少。圖表如同指南,直接指出可能出錯的區域。
- 提升影響分析: 若提出變更,例如修改欄位名稱,血統圖會清楚顯示哪些報表和下游流程將受影響。這可防止意外停機。
- 法規合規性: 審計人員需要資料處理的證明。流程圖提供清晰的視覺審計軌跡,滿足資料隱私與安全的要求。
- 知識傳遞: 新成員能快速理解系統架構。他們不再依賴口耳相傳的知識,而是透過研究圖表來掌握資料在組織內的流動方式。
- 效能最佳化: 分析資料流經常能揭露瓶頸。若資料在某個儲存位置或處理步驟上等待過久,圖表會標示出應著力優化的地點。
維護圖表 🔄
血統圖不是一次性的任務。系統會持續演進,新的資料來源被加入,舊的流程則被停用。若圖表未及時更新,將變得具有誤導性。維持準確性需要對變更管理採取嚴謹的方法。
每次資料管道被修改時,都應重新審查圖表。這應納入部署檢查清單。若整合了新的 API,必須加入外部實體與資料流。若轉換邏輯變更,流程框的描述也必須更新。將圖表視為程式碼,可確保其持續作為可靠的資源。
自動化可協助維護工作。某些平台允許根據元資料倉儲自動產生圖表。雖然仍需人工審查,但自動化能減輕視覺呈現與技術現實不同步的負擔。然而,完全依賴自動化可能忽略業務脈絡,因此人工監督仍至關重要。
應對複雜性 ⚖️
大型企業經常面臨複雜的資料生態系統。數千張資料表與數百個流程可能讓單一圖表過於龐大。在這些情況下,模組化至關重要。將血統劃分為邏輯領域。為銷售資料、客戶資料與財務資料分別建立圖表。在交集處連結它們,但保持主要視圖的聚焦。
另一項挑戰是處理遺留系統。較舊的系統可能缺乏自動追蹤所需的元資料。在這些情況下,必須進行手動重建。訪談原始開發人員或審閱舊文件,以推斷資料流。對這些缺口保持透明。在圖表上標示出不確定區域,以指出需要進一步調查的位置。
提升清晰度的最佳實務 🚀
為確保圖表能發揮其功能,請遵循以下設計與呈現的指導原則。
- 一致的命名: 在所有圖示中使用標準名稱來命名流程和資料儲存。避免使用可能讓讀者混淆的縮寫。
- 方向流動: 將圖示安排成從左到右或從上到下邏輯流動。這符合自然的閱讀習慣。
- 色彩編碼: 使用顏色來表示狀態。例如,綠色代表活躍的流程,紅色代表已棄用的流程,黃色代表需要審查的流程。
- 分層: 將高階視圖與詳細視圖分開。不要在主圖中塞入每一筆欄位對應關係,以免造成混亂。
- 存取控制: 確保需要的人能夠存取圖示。安全團隊可能需要查看涉及敏感資訊的資料流,而開發人員則需要看到技術實作細節。
最終考量 🔍
使用流程圖追蹤資料血統是一門結合技術精確性與清晰溝通的學問。它能將抽象的資料移動轉化為具體的視覺模型。透過遵循既定標準並維持嚴謹的更新週期,組織能夠實現高度的資料透明度。這種透明度是現代資料治理的基石。
建立與維護這些圖示所付出的努力,將在降低風險與提升效率方面獲得回報。隨著資料量增加與法規日益嚴格,追蹤資料來源與旅程的能力將變得更加關鍵。今日投資於清晰且準確的流程圖,能讓組織為明日的挑戰做好準備。目標不僅是記錄系統,更要深入理解系統,以持續改善。